Article
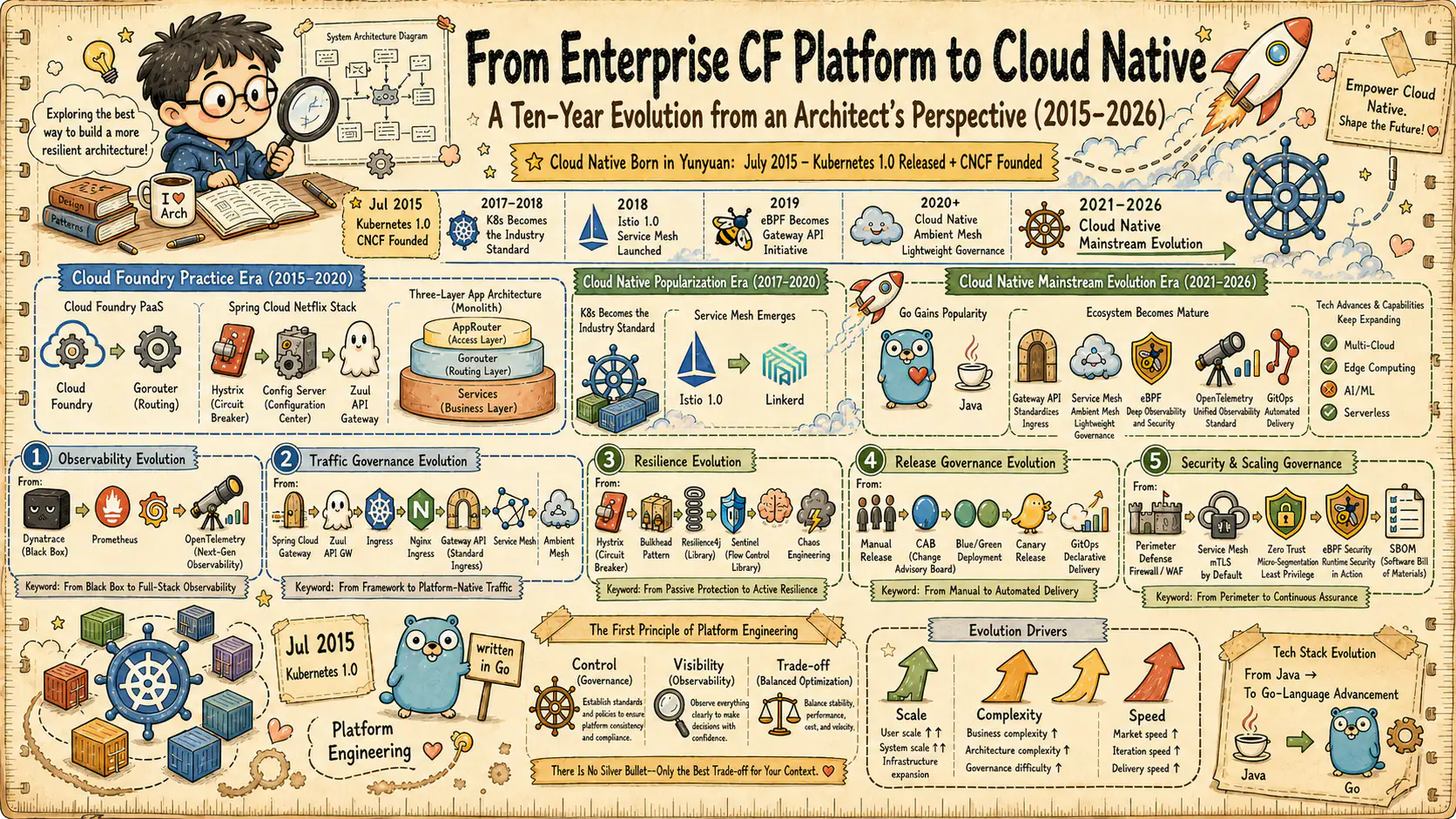
From enterprise-level CF platform to cloud native (1): Architect's review - the gains and losses of microservice governance in the era of enterprise-level CF platform
Based on the front-line architecture practice of enterprise-level CF platforms from 2015 to 2020 and industry observations from 2015 to 2026 (to date), we review the microservice governance design decisions in the Cloud Foundry era and analyze which ones have withstood the test of time and which ones have been reconstructed by the cloud native wave.
From enterprise-level CF platform to cloud native (1): Architect’s review - the gains and losses of microservice governance in the era of enterprise-level CF platform
Subtitle: Gains and losses of microservice governance in the enterprise-level CF platform era (2015-2020, 6 years of practice)

Figure 1: Ingress routing, identity services and runtime layered architecture in a common enterprise-grade Cloud Foundry platform
1. Opening Positioning: Six Years of CF Practice and Continuous Industry Observation
In the spring of 2015, the enterprise-level CF platform coincided with the rapid expansion of Cloud Foundry (CF) in the enterprise-level market. At that time, the microservice architecture had just entered the mainstream view from the technical blogs of Internet giants such as Netflix and Amazon. The Spring Cloud Netflix suite released its first stable version. Docker 1.0 was released less than a year ago, and Kubernetes was still in the experimental stage of 0.x.
This article takes the front-line architecture practice of enterprise-level CF platforms from 2015 to 2020 as the main line, and combines the continuous industry observation from 2015 to 2026 (to date) to review the evolution of microservice governance. In the past six years (2015-2020), from the migration of single applications to microservices, the splitting of dozens of services, the design of CF multi-region deployment architecture, the formulation of communication specifications between services, and the construction of observability systems, these practices have allowed me to form a systematic understanding of enterprise-level microservice governance, and also accumulated a lot of experience about “what works and what doesn’t work.”
After starting from the front-line practice of enterprise-level CF platform, we continue to observe the evolution of architecture in organizations of different industries and sizes: from the cloud native transformation of startups, to the hybrid cloud deployment of financial institutions, to the implementation of Service Mesh in large e-commerce companies. These observations provide a perspective beyond the specific technology stack of the enterprise-level CF platform, and see more clearly which architectural principles in the decisions of the year have stood the test of time, and which are specific implementations that have been eliminated by the technology wave.
The goal of this series of articles is to review the evolution of enterprise-level microservice governance based on enterprise-level CF platform practices and continuous industry observations from 2015 to 2020. This article begins by focusing on the enterprise-level CF platform era from 2015 to 2020, answering three core questions:
-
**What was the technology selection logic back then? ** Why choose the combination of Cloud Foundry + Spring Cloud Netflix instead of other options that seemed more promising at the time?
-
**What design principles have stood the test of time? ** After six years of practice, which decisions still seem correct today, and have even been inherited by later technologies?
-
**Which decisions were “right at the time but limited now”? ** Why did the optimal solution back then become technical debt today? What is the underlying logic behind this shift?
It should be noted that this article is not a retelling of the technical documentation of Cloud Foundry or Spring Cloud, but the review notes of a practitioner. This article will try to restore the decision-making scenarios, trade-off factors and subsequent actual effects at the time, to help readers understand the complexity of enterprise-level technology selection, and how to make sustainable architecture decisions in an environment where technology is rapidly evolving.
2. Governance philosophy in the enterprise-level CF platform era
2.1 Cloud Foundry’s enterprise-level PaaS positioning
The PaaS market around 2015 was still in the early competitive stage. Heroku has a first-mover advantage in the public cloud field, but it is mainly targeted at startups and small applications; OpenShift has just started, and container technology is not yet mature; Google App Engine has many functional limitations and its support for the Java ecosystem is not perfect. In the enterprise market, Cloud Foundry was the most mature option at the time. There are several key considerations when choosing CF as the core platform for an enterprise-level CF platform:
**First, enterprise-level feature completeness. ** CF has considered enterprise-level requirements such as multi-expansion account isolation, security compliance, and audit logs from the beginning of its design. Its organization (Org) and space (Space) models are naturally adapted to the department structure and authority management needs of large enterprises. In contrast, early Kubernetes had almost no multi-extended account security isolation mechanism, and RBAC was relatively stable until version 1.6.
**Second, the fit with the enterprise-level CF platform technology stack. ** The core business of the enterprise-level CF platform is built on Java, and CF has the best support for Java applications. The Buildpack mechanism allowed for standardized application packaging, and the Diego container runtime (later Garden) provided a Docker-compatible but more controlled execution environment. For enterprise software that requires strict compliance audits, this controlled environment is more suitable than a free container runtime.
**Third, the simplicity of the deployment model. ** The developer experience of cf push was unparalleled at the time. Developers only need to focus on the code, and the platform automatically handles low-level details such as construction, containerization, scheduling, load balancing, and log aggregation. This level of abstraction is critical for enterprise-scale CF platforms with thousands of developers - it significantly lowers the barrier to adoption of microservices architecture across the company.
The complete life cycle of cf push
Behind the cf push command is a complete and sophisticated life cycle management process. Understanding this process helps clarify the essential differences in application deployment models between Cloud Foundry and Kubernetes:

Figure 1-1: The complete life cycle of cf push (platform takes over the build, runtime, health check and route registration)
1. Upload
- CLI compresses and uploads application code to Cloud Controller
- Generate a unique app package and store it in blobstore
2. Staging
- Diego Brain schedules Staging tasks to Diego Cell
- Buildpack detection: Automatically select buildpack based on code characteristics (such as pom.xml, package.json)
- Compile and package:
- Java buildpack download JDK, Maven/Gradle
- Perform compilation (such as
mvn clean package) - Package applications and runtime dependencies into Droplets (executable units)
- Droplets are stored in blobstore and separated from the code
3. Cell Scheduling (Diego/Garden)
- Diego Brain schedules the Droplet to the available Diego Cell
- Garden container runtime creates application containers (similar to Docker but more controlled)
- Download the Droplet and extract it to the container file system
- Set environment variables, ports, and resource limits
4. Application startup
- Execute the startup command generated by the buildpack (such as
java -jar app.jar) - Health checks (HTTP/TCP/Process) verify application readiness
- The application status changes to Running
5. Route registration (Gorouter)
- Cloud Controller registers application routes (such as
my-app.cfapps.io) with Gorouter - Gorouter updates the routing table and maps the domain name to the IP:Port of the container instance
- Traffic starts being forwarded to the application
The key to this process is that the platform completely takes over the build and runtime management - developers do not need to write Dockerfiles, manage image warehouses, or configure scheduling policies. This high level of abstraction was CF’s core competency between 2015 and 2020, but it also brought about the problem of limited flexibility: when custom container images, privileged access, or specific kernel parameters are required, CF’s controlled environment becomes a constraint.
2.2 Governance boundaries of Spring Cloud Netflix stack
At the application layer, the enterprise-level CF platform has selected some components of Spring Cloud Netflix as the core framework for microservice governance. It should be noted that the enterprise-level CF platform environment does not use the Eureka service registry and Ribbon client load balancing - service discovery is handled by Cloud Foundry’s Gorouter and internal DNS mechanism, which was considered more concise and efficient in the architectural decisions at the time. The Spring Cloud Netflix capability matrix actually adopted by the enterprise-level CF platform:
- Circuit Break Downgrade: Hystrix implements circuit breaker mode (this is the main governance component used)
- Configuration Management: Spring Cloud Config supports externalized configuration
- Not used: Eureka (service discovery is handled by CF Platform), Ribbon (load balancing is handled by Gorouter), Zuul (gateway is handled by AppRouter and CF Gorouter)
This choice may seem like “following the mainstream” today, but in 2015-2016, it was actually a well-thought-out technical decision - Only introduce necessary governance capabilities and avoid reinventing the wheel. In the large-scale team collaboration scenario of the enterprise-level CF platform at that time, this strategy significantly reduced cross-team technical differences and operational risks.
The core design concept of this technology stack is layered governance: the platform layer (CF Gorouter) is responsible for service discovery and load balancing, and the application layer (Hystrix) is responsible for circuit breaking and fault tolerance. The advantage of this architecture is the separation of responsibilities - the platform handles general network capabilities and the application handles specific business fault tolerance requirements.
**Flexibility advantage. ** Codification of governance logic means that behavior can be precisely controlled. Hystrix’s thread pool isolation, timeout configuration, and degradation strategies can all be fine-tuned through code, unlike later Service Mesh that relied on externally configured DSLs.
**Development experience advantages. ** All governance functions are exposed through Spring’s annotation and configuration mechanism, and Java developers can obtain complete microservice capabilities without leaving the familiar technology stack.
But this design also has its implicit constraints: the governance logic is tightly coupled with the application, and upgrading the governance framework means that the application must be rebuilt and deployed. At the time, this was seen as an acceptable trade-off - after all, Spring Cloud’s version iterations were relatively stable, and redeploying an application on CF was only a matter of seconds.
2.3 Division of responsibilities between platform layer and application layer
A core feature of an enterprise-grade CF platform architecture is clear hierarchical governance boundaries. This boundary can be summarized using the “three-layer routing” model:
Layer 1: Application Router (AppRouter). This is an enterprise-grade CF platform-specific component that handles user authentication, session management, and extended account routing. In a multi-extension account SaaS scenario, AppRouter determines the target extension account based on the requested domain name or path, handles the OAuth/OIDC authentication process, and then forwards the authenticated request to the downstream service.
Second layer: CF Gorouter. This is the core routing component of the CF platform, responsible for mapping external requests to specific application instances. Gorouter maintains the location mapping table of application instances and handles TLS termination, load balancing, and health checks. It is completely transparent to the application - the application only needs to listen to the port in the container and does not need to care about external routing configuration.
Layer 3: Cloud Foundry platform routing and application layer elastic communication. For calls between services within the platform, CF supports container-to-container communication through internal DNS (such as apps.internal), and cooperates with network policy to achieve secure access between services. Gorouter is responsible for platform-level load balancing. Governance capabilities such as circuit breaker, retry, and timeout are implemented by the application layer framework (mainly Hystrix) rather than automatically provided by the CF platform.
The value of this layered architecture lies in the clear responsibilities: each layer only handles the problems that its own layer should handle. AppRouter does not handle service discovery, Gorouter does not handle circuit breaking, and Hystrix does not handle external routing. This clear layering is especially important in large organizations—it allows different teams to focus on their own areas and reduces the complexity of cross-team collaboration.
2.4 The technology selection decision-making logic of the year
Looking back at the technology selection of that year, it can be summarized by three core principles:
**Principle 1: Give priority to solutions that have been verified by production. ** Netflix in 2015 has been running microservice architecture in production environments for many years, and Spring Cloud Netflix is a systematic encapsulation of these practices. In comparison, Istio won’t release version 0.1 until 2017, and Linkerd 1.0 is still in its early stages. In enterprise-level scenarios, “someone has used it” is an extremely important filtering condition.
**Principle 2: Control the complexity of the technology stack. ** At that time, the industry evaluated the possibility of self-developed service governance solutions, but ultimately gave up. The reason is not a matter of technical capabilities, but of maintenance costs. A self-developed RPC framework, service discovery system, and circuit breakers require long-term maintenance by a dedicated team. Spring Cloud Netflix has an active community, production endorsement from Netflix, and complete support from the Spring ecosystem. The cost of introducing these components is much lower than building it yourself.
**Principle 3: Maintain consistency with the overall technology strategy of the enterprise-level CF platform. ** Enterprise-grade CF platforms are heavily promoting Cloud Foundry as a unified application platform in 2015-2016. Choosing CF’s native mechanism and Spring Cloud’s standard solution means that you can collaborate with the company’s platform team, security team, and operation and maintenance team. If you choose a completely different technology stack (such as Kubernetes, which was already developing at the time), you will face a lot of organizational resistance.
These decisions were reasonable at the time. But from today’s perspective, some of these assumptions have since changed—which is what the next section discusses.
2.5 Space and enterprise-level CF platform expand the boundaries of the account system: design-time isolation vs run-time isolation
Conclusion first: **Space solves delivery isolation, while extended accounts solve data and identity isolation; the two cannot replace each other. **
In the practice of enterprise-level CF platform from 2015 to 2020, the most easily confused concepts within the team are “CF Space and enterprise-level CF platform extended account system”. Cloud Foundry’s Space is naturally suitable for hosting delivery pipeline layers such as dev/test/prod, but it is not equivalent to extending the account security domain. Treating Space as an extended account isolation unit will cause chain problems in resource management, identity boundaries, and data lifecycle governance after scaling up.
Based on the first-line practice of implementing enterprise-level multi-expansion accounts at that time, the boundaries can be summarized into three lines:
- Space is a design-time isolation unit: mainly used for version, environment, and release process management.
- The enterprise-level CF platform extended account system is a runtime isolation unit: used for business data isolation, identity isolation, and permission isolation.
- Extended accounts can consume applications across multiple Spaces: Expanding account boundaries at runtime does not depend on a single Space.

Figure 2: Governance boundaries of Space and enterprise-level CF platform extended account systems (design-time isolation and run-time isolation)
The value of this division is not only a clear concept, but also directly determines the subsequent governance strategy: which capabilities you will hand over to the platform process, and which capabilities will be precipitated into extended account lifecycle services.
2.6 Extended account life cycle management: Entitlement → Subscription → Onboarding → Runtime → Offboarding
Conclusion first: **Multiple expansion account management is not a static configuration item, but a full life cycle pipeline. **
In the era of enterprise-level CF platforms, the main line of extended account management is not as simple as “creating an extended account”, but a closed-loop link from commercial authorization to technical lease withdrawal:
- Entitlement (permission quota): Define which platform capabilities and SaaS capabilities customers can use.
- Subscription: Bind a technology extension account to a specific application.
- Onboarding (callback): The platform triggers a callback, and the application completes the initialization of extended account-level resources.
- Runtime (Runtime Identification and Access): Performs authentication, routing, and data access based on extended account context.
- Offboarding (retirement and deletion): Terminate access, export window, data deletion and audit closed loop.
There are two points that are very critical in engineering practice but are easily overlooked:
- Subscription callbacks will be triggered repeatedly and must be idempotent and reference counted: Avoid repeatedly creating extended account resources such as HDI schema/container.
- Retirement logic must be bound to the subscription relationship: Complete deletion at the physical level is only allowed after the last valid subscription ends.

Figure 3: Multi-extended account life cycle governance flow (from authorization to lease cancellation)
This is why enterprise-level multi-extended account systems will eventually move towards the governance model of “platform callback + application orchestration + audit traceability”: without a life cycle perspective, the so-called multi-extended account will only stay in the initial stage of “database plus a column account_context_id”.
2.7 Security governance link: AppRouter + OAuth2/OIDC identity service (CF common implementation is UAA) + JWT Scope
Conclusion first: **The core of security governance in the era of enterprise-level CF platforms is not “whether there is authentication”, but “whether the extended account identity is stably propagated throughout the entire link and consumed with the minimum permissions.” **
In the runtime link, the key steps are:
- AppRouter identifies the target extension account from the extension account domain name/path;
- OAuth2/OIDC identity service (CF common implementation is UAA) Complete the authentication under the extended account identity zone and delegate to the extended account IdP;
- The issued JWT carries extended accounts, users, and scopes;
- The downstream microservice performs extended account context parsing and scope verification based on JWT, and then accesses the extended account isolation data.
This link seems standard, but the real engineering challenge lies in “consistency”: when requests traverse multiple microservices, message channels, and asynchronous tasks, the extended account context and permission boundaries cannot be lost, drifted, or amplified by default.

Figure 4: Extended account security authentication link (identity partitioning and permission propagation)
Looking back today, this approach still has long-term value: regardless of whether the base is CF or Kubernetes, extended account identity propagation, minimum permissions, and audit closed loop are irreplaceable governance main lines.
3. Design principles that have stood the test of time
After six years of practicing the enterprise-level CF platform, some design decisions have proven to stand the test of time. They are not features of a specific technology, but architectural-level principles that are still valid today.
3.1 Layer 3 routing idea
The core value of the AppRouter → Gorouter → Spring Cloud three-tier architecture mentioned earlier does not lie in the specific components used, but in the principle of “layered governance” itself. This principle contains several key points:
**Separation of concerns. ** Each layer handles only specific types of routing decisions. AppRouter handles extended accounts and authentication, Gorouter handles instance location, and the service layer handles business routing. This separation allowed each layer to evolve independently - enterprise-grade CF platforms later introduced more sophisticated scaling account isolation strategies in AppRouter, but without the need to modify the Gorouter or service layer.
**Replaceability. ** The layered architecture allows the implementation of one layer to be replaced without affecting other layers. The enterprise-grade CF platform later replaced the Gorouter layer of some products with a custom ingress gateway, but the code of the AppRouter and service layer remained almost unchanged. This kind of replaceability is extremely valuable as the architecture evolves.
**Fault isolation. ** The fault impact scope of each layer is limited to that layer. Gorouter problems will not affect calls between services, and Hystrix circuit breakers only affect communication between specific services. This fault isolation is critical to the stability of large distributed systems.
Today, this principle is carried forward in Service Mesh architecture. Istio’s data plane (Envoy Sidecar) actually adds a governance layer between the application layer and the network layer, achieving more fine-grained control and better separation of concerns.
3.2 Zero-downtime concept of blue-green deployment
Blue-Green Deployment, natively supported by CF, is another practice that has stood the test of time. This mechanism allows new versions to be deployed without affecting online traffic, and instant rollback can be achieved by switching routes.
In the context of an enterprise-level CF platform, blue-green deployment solves several key issues:
**Coordination of database migrations. ** After microservices are split, database schema changes are the most dangerous operations. Blue-green deployment allows you to deploy a new version (green environment) first, verify that it works properly, then perform database migration, and finally switch traffic. If the migration fails, you can immediately switch back to the blue environment.
**Handling of long sessions. **Enterprise applications often have long user sessions. Restarting the application directly will cause the session to be lost and affect the user experience. Blue-green deployment allows existing sessions to end naturally in the blue environment before switching traffic, and new sessions are routed to the green environment.
**Basics of A/B testing. ** The routing switching mechanism of blue-green deployments can be extended to distribute traffic proportionally, which lays the foundation for later A/B testing and canary releases.
Today, blue-green deployment, canary release, and grayscale release have become standard practices for cloud native applications. Kubernetes’ Deployment rolling updates, Flagger’s automated canaries, and Argo Rollouts’ progressive delivery are all evolutions of this concept. But around 2015, CF already provided zero-downtime deployment capabilities out of the box, which is an important manifestation of its enterprise-level maturity.
3.3 Separation of configuration and code
The design of Spring Cloud Config was an important advancement at the time. It separates the application configuration from the code base, stores it in an independent Git repository, and provides it to the application at runtime through Config Server.
This design solves several practical problems:
**Environmental differentiation management. ** Configuration differences (database connections, API keys, function switches) between development, testing, and production environments no longer need to be handled through conditional branches in the code, but are managed through different Git branches or profiles.
**Dynamic configuration updates. ** With Spring Cloud Bus, configuration changes can be pushed to running applications without redeployment. This is very useful when urgently adjusting timeout parameters and switch functions.
**Audit and Compliance. ** The configuration change history is saved in Git, and you can trace who modified what configuration at what time. This is necessary for enterprise software that needs to pass compliance audits.
Today, separation of configuration and code has become a basic principle. The GitOps model takes this concept to the extreme - not only configuration, but also infrastructure definition is included in Git management. Tools such as External Secrets Operator and Sealed Secrets solve the problem of configuration security. But the core principle is still established by Spring Cloud Config that year: configuration is an artifact independent of code and requires version control, audit tracking, and dynamic management capabilities.
3.4 Concept change of observability priority
The emphasis on observability in enterprise-grade CF platform environments was ahead of its time. CF natively integrates the Loggregator log aggregation system, the Diego container provides detailed application life cycle events, and Gorouter records the access logs of all requests. At the application layer, Spring Boot Actuator exposes a rich set of health checks and metrics.
More importantly, we have established the design principle of “observability first” at the architectural level:
**Every service must expose a health check endpoint. ** This is not optional, but a mandatory requirement for deploying to CF. CF’s health check mechanism will call /health regularly. If a non-200 status code is returned, the container will be marked as unhealthy and restarted.
**All requests must have traceable identification. ** The enterprise-level CF platform implements an early version of distributed tracing at the application layer - each request is assigned a correlation ID when it enters the system, and this ID is propagated along the call chain and eventually appears in all related logs. Although there was no mature distributed tracing system at the time (Zipkin was just beginning to develop), this mechanism already allowed the team to correlate logs across services.
**Metrics must be easy to aggregate and analyze. ** All services expose metrics using a unified format (Micrometer later became the standard), collected and analyzed through Dynatrace. The enterprise-level CF platform clearly requires during the architecture review that key indicators (KPIs) and alarm thresholds must be defined when new functions are launched.
Today, observability has changed from an “operational and maintenance requirement” to a “core architectural element.” OpenTelemetry provides a standardized observation data format, Prometheus and Grafana become the de facto standards for measurement data, and Jaeger and Tempo handle distributed tracing. However, the principle of “observability first” - considering how to monitor, how to troubleshoot, and how to measure during the design phase - was established in the enterprise-level CF platform that year and is still valid today.
3.5 Expanded hierarchical strategy for account data isolation
Conclusion first: **In an enterprise-level multi-extended account SaaS scenario, extended account data isolation should be prioritized by “Extended Account Independent Container/Schema” by default, and exception management should be done based on scale and cost. **
The practice of the enterprise-level CF platform at that time was not to “only pursue the strongest isolation”, but to make layered trade-offs:
- Default path: Extended account-level isolation container (such as HDI container per extended account);
- Exception path: When the amount of extended account data is extremely small and the cost constraints are significant, shared storage and strict extended account column isolation should be considered;
- High compliance scenarios: When recovery, migration, legal deletion, and audit traceability requirements are higher, stronger isolation units are preferred.
The key to this decision being able to withstand the test of time is that it simultaneously meets four types of governance objectives: security boundaries, operation and maintenance operability, cost controllability, and evolution portability.

Figure 5: Extended account data isolation decision matrix (balance of security, cost and operability)
For today’s architects, this experience still applies: first clearly define the “default isolation level”, and then institutionalize the “access conditions for downgraded sharing”, not the other way around.
4. Decisions that were “right then, but limited now”
Although the architecture of CF + Spring Cloud Netflix was a reasonable choice at the time, technological evolution has turned some of these decisions into technical debt today. Understanding the underlying logic of these changes is more valuable than simply judging “it was the wrong choice at the time.”
4.1 Service discovery: CF platform routing vs Kubernetes DNS + Service Mesh
**The decision-making scene of the year. **
In the era of enterprise-level CF platforms, service discovery does not use application layer solutions such as Eureka, but relies on the Cloud Foundry platform’s native Gorouter and internal DNS mechanism. This was different from the mainstream Spring Cloud Netflix practice at the time - the enterprise-level CF platform chose a layered architecture in which “the platform provides service discovery and the application focuses on business logic”.
CF’s service discovery mechanism is simple and efficient: after an application is deployed through cf push, the platform automatically allocates internal routes (such as app-name.apps.internal) to it, and Gorouter maintains the location mapping of application instances. Inter-service calls are resolved to Gorouter through internal DNS, and then Gorouter performs load balancing. The advantages of this approach are:
- Application-agnostic: No need to introduce libraries such as Eureka Client, the application only needs to call the internal domain name of the target service through HTTP
- Unified platform maintenance: Service registration, health check, and instance online and offline are all automatically handled by the CF platform
- Multi-language friendly: Whether the application uses Java, Node.js or Python, the service discovery mechanism is exactly the same
This architectural decision was forward-looking at the time - it anticipated the later Kubernetes Service + DNS model. However, CF’s platform routing also has its limitations: it is mainly load balancing at the L4 layer and does not support fine routing based on request content (such as by header, grayscale by weight).
**Revelation of limitations. **
The first limitation of CF platform routing is functional boundaries. Gorouter provides basic round-robin load balancing and does not support the following advanced governance capabilities:
- **Fine-grained traffic policy. ** For example, routing based on header/cookie/identity, or grayscale based on business tags.
- **Zero trust security between native services. ** For example, automatic mTLS certificate rotation, fine-grained service authorization policies.
- **Unified policy distribution and playback. ** Lack of declarative control plane for complex traffic governance policies.
Therefore, the industry will continue to shift more governance responsibilities to the Kubernetes ecosystem (Service, Gateway API, Service Mesh):
-
**Standardization requirements. ** When an organization uses multiple languages and frameworks, the cost of maintaining Eureka Client for each language is high. The infrastructure layer solution is language independent.
-
**Operation and maintenance are simplified. ** Kubernetes automatically handles the addition and deletion of Endpoints, and there is no need to maintain an independent high-availability cluster like Eureka.
-
**Capability evolution. ** Service Mesh can provide capabilities that Eureka cannot achieve, such as mTLS automatic encryption, weight-based grayscale routing, rich traffic indicators, etc.
This is not a problem with Eureka’s design, but the evolution of architectural patterns caused by changes in the technical environment. Eureka was still the mainstream choice for many teams around 2015; by 2026-03, Kubernetes DNS, Gateway API, Service Mesh, and platform-level service discovery had become more common governance boundaries.
4.2 Configuration management: Spring Cloud Config Server vs GitOps + External Secrets
**The decision-making scene of the year. **
Spring Cloud Config Server solved the core need for configuration externalization at the time. The enterprise-level CF platform centrally stores all configurations in the Git repository. Config Server pulls the configuration from Git and exposes it as a REST API. The configuration is obtained from the Config Server when the application starts.
This architecture supports configuration of multi-environment management (via Git branches or profiles), dynamic refresh (via Spring Cloud Bus), and audit trails (Git history). In 2015, this is pretty much the only mature option for configuration externalization.
**Revelation of limitations. **
The first problem with Config Server is a single point of bottleneck. The startup of all applications relies on Config Server. When applications expand on a large scale, Config Server becomes a performance bottleneck. Although it can be alleviated through clustering, this increases the complexity of operation and maintenance.
The second issue is security. Config Server’s REST API exposes sensitive configurations and requires additional authentication and authorization mechanisms. Sensitive configurations such as keys, passwords, etc. are stored in clear text or simply encrypted in Git, which does not comply with modern security best practices.
The third problem is the separation of the cloud native ecosystem. Kubernetes has ConfigMap and Secret native mechanisms, Helm provides templated configuration management, and Flux and ArgoCD implement GitOps workflow. Spring Cloud Config is a parallel system independent of these mechanisms and cannot be seamlessly integrated with the Kubernetes ecosystem.
**Alternatives for today. **
GitOps has become the mainstream paradigm for configuration management. Configuration (including application configuration and infrastructure configuration) is stored in a Git repository, and GitOps tools (Flux, ArgoCD, Fleet) automatically synchronize the configuration to the cluster.
For sensitive configurations, the External Secrets Operator and Vault integration provide secure key management. The configuration is stored in Vault and the application obtains it through environment variables or mounted volumes. There is no need to expose plaintext keys in Git.
Kubernetes’ native ConfigMap and Secret cooperate with mechanisms such as downward API and projected volumes to provide flexible configuration injection methods. Helm and Kustomize provide configuration templating and multi-environment management capabilities.
**Deep logical analysis. **
The transition from Config Server to GitOps reflects the “infrastructure” of configuration management responsibilities. Config Server is an application layer solution, and configuration logic is coupled in the Spring ecosystem; GitOps is an infrastructure layer solution, and configuration becomes part of the cluster state.
Driving forces for this shift:
-
**Uniformity requirements. ** Modern application stacks include Kubernetes resources, application configurations, and infrastructure definitions, and GitOps provides a unified management plane.
-
**Security improvements. ** External Secrets and Vault integration solve key management problems in the Config Server era.
-
**Automation capabilities. ** GitOps tools not only synchronize configurations, but also implement advanced functions such as automatic rollback, drift detection, and multi-cluster management.
4.3 Circuit Breaker Downgrade: Hystrix Thread Pool Isolation vs eBPF + Sidecar-less
**The decision-making scene of the year. **
Hystrix is Netflix’s open source circuit breaker library, which provides functions such as circuit breaker, downgrade, and thread pool isolation. Hystrix is widely used in the architecture of the enterprise-level CF platform era. Each call to an external service is wrapped in a HystrixCommand and configured with independent thread pools and timeout parameters.
Thread pool isolation is one of the core features of Hystrix. Each dependent service is allocated an independent thread pool. When the response of a service becomes slow, its thread pool will be full, but it will not affect the calls of other services. This is very effective in preventing fault propagation.
**Revelation of limitations. **
The first problem with Hystrix is resource overhead. Thread pool isolation requires maintaining a set of threads for each dependency, and threads are heavier resources in Java. When a service has a large number of downstream dependencies, the total number of thread pools will be large, increasing memory consumption and context switching overhead.
The second problem is programming complexity. Developers need to explicitly create HystrixCommand in code to handle various configurations and callbacks. This intrusive programming model increases code complexity and does not work smoothly with asynchronous programming models such as CompletableFuture and Reactive Streams in Java 8+.
The third problem is version lock. Hystrix entered maintenance mode in 2018 (no longer actively developed by Netflix), and Spring Cloud removed default support for Hystrix in subsequent releases. But in the code base of an enterprise-grade CF platform, the replacement of thousands of HystrixCommands becomes a huge technical debt.
**Alternatives for today. **
Service Mesh is the mainstream solution for circuit breaker degradation. Service Mesh such as Istio and Linkerd implement the circuit breaker function in the data plane (Sidecar or Proxyless mode), which is completely transparent to the application. The application uses normal HTTP/gRPC calls, and the circuit breaking logic is automatically handled by the data plane.
A more cutting-edge solution is to use eBPF to implement sidecar-less service governance. Projects such as Cilium and Merbridge use eBPF to implement traffic interception and governance at the Linux kernel layer, eliminating the overhead of Sidecar while providing more fine-grained control capabilities than Hystrix.
Resilience4j is a recommended alternative to Hystrix, providing similar circuit breaking functionality but with a more lightweight design (not relying on thread pool isolation, using semaphores or bulkhead patterns). For scenarios where Service Mesh cannot be used, Resilience4j is a better transition solution.
**Deep logical analysis. **
The transition from Hystrix to Service Mesh reflects the “sinking” and “decentralization” of governance logic. Hystrix is the library of the application layer, and each service independently maintains its own governance logic; Service Mesh is the capability of the infrastructure layer, and the governance logic is unified and implemented on the data plane.
The core driver of this transformation is the deepening of separation of concerns. In a microservices architecture, circuit breaker degradation is a “cross-cutting concern” - required by each service, but should not be implemented individually by the developers of each service. Service Mesh separates this concern from the application layer and lowers it to the infrastructure layer, allowing developers to focus on business logic.
The eBPF solution further advances this trend, sinking governance capabilities to the operating system kernel layer to achieve higher performance and lower overhead.
4.4 Observability: Dynatrace black box monitoring vs. OpenTelemetry full link
**The decision-making scene of the year. **
The enterprise-grade CF platform uses Dynatrace as the primary APM tool in the CF environment. Dynatrace was the leader in enterprise-level APM at the time, providing automated application topology discovery, performance baselines, anomaly detection, root cause analysis and other functions. One of its core advantages is “black box monitoring” - by injecting Java Agent, it automatically captures method calls, SQL execution, and HTTP requests without modifying the application code.
This black-box approach is extremely valuable in the large-scale environment of enterprise-grade CF platforms. There is no need to configure monitoring points one by one for thousands of services. Dynatrace Agent automatically discovers the calling relationships between services and builds a complete dependency topology map.
**Revelation of limitations. **
The first problem with Dynatrace is vendor lock-in. Dynatrace’s data format, query language, and visualization interface are proprietary and cannot be integrated with other tools. When enterprises want to use Grafana for unified visualization and Prometheus for alarms, they find that data export and conversion are extremely difficult.
The second issue is cost. Dynatrace is charged per agent, and in large-scale microservices environments, annual licensing costs can reach millions of dollars. As the number of services continues to grow, this cost becomes a budget pressure.
The third issue is standardization. Dynatrace uses its own tracing format that is not compatible with the open source OpenTracing and OpenCensus standards. When the community began to formulate the OpenTelemetry standard, Dynatrace support lagged significantly.
**Alternatives for today. **
OpenTelemetry has become the de facto standard in observability. It provides a unified data model and SDK, and supports three observation data types: traces, metrics, and logs. After the application is connected to the OpenTelemetry SDK, it can send data to any compatible backend (Jaeger, Prometheus, Grafana Tempo, Datadog, Dynatrace, etc.).
Prometheus + Grafana becomes the standard combination for metric monitoring. Prometheus’ pull model and PromQL query language are widely accepted by the cloud native ecosystem, and Grafana provides flexible dashboards and alerting capabilities.
Jaeger and Zipkin handle distributed tracing, and Grafana Tempo and Loki provide cost-optimized tracing and log storage solutions.
**Deep logical analysis. **
The transformation from Dynatrace black-box monitoring to OpenTelemetry is essentially an evolution from “vendor proprietary solutions” to “open source standard solutions”. The driving force behind this transformation:
-
**The unified needs of the cloud native ecosystem. ** The Kubernetes ecosystem needs a platform-independent observation standard, and OpenTelemetry fills this gap.
-
**Cost optimization needs. ** The cost advantage of open source solutions is obvious in large-scale scenarios, especially for observation types such as logs and tracking with huge amounts of data.
-
**Portability requirements. ** Enterprises want to avoid being locked into a single vendor, and OpenTelemetry’s standard format ensures that data can be migrated between different tools.
-
**Developer experience requirements. ** OpenTelemetry provides a more flexible tracking API, supports manual and automatic tracking, and integrates more smoothly with various programming languages and frameworks.
It’s worth noting that Dynatrace is also now an active supporter of OpenTelemetry, with new versions of its product that can natively receive OTLP data. This validates the trend toward standardization—even commercial APM vendors must embrace open standards to remain competitive.
4.5 Deep patterns behind technological evolution
Looking back at the evolution of these four aspects, we can summarize some common deep patterns:
**Mode 1: Responsibilities are decentralized from the application layer to the infrastructure layer. **
Service discovery has evolved from CF platform routing (infrastructure layer capabilities) to Kubernetes DNS (infrastructure layer standards); circuit breaker has moved from Hystrix (application layer library) to Service Mesh (infrastructure layer); configuration management has moved from Config Server (application layer services) to GitOps (infrastructure layer tools).
This drive to sink is a natural extension of the separation of concerns principle. Governance capabilities in microservice architecture are cross-cutting concerns and should not be implemented by each service individually, but should be provided uniformly by the infrastructure. This allows application developers to focus on business logic and allows governance capabilities to evolve independently of applications.
**Mode 2: Capability implementation from library to sidecar to kernel layer. **
The implementation method of service governance capabilities has experienced the evolution of “Application Library → Sidecar Proxy → eBPF Core”. Each generation of solutions attempts to find a better balance between “intrusiveness” and “performance”.
- Application libraries (such as Hystrix, Eureka Client): good performance, but highly intrusive and difficult to support multiple languages
- Sidecar Proxy (like Envoy): less intrusive but adds latency and resource overhead
- eBPF kernel solution: low intrusion, performance close to native, but dependent on newer kernel versions
**Mode 3: From proprietary solutions to open standards. **
The field of observation has moved from Dynatrace proprietary format to the OpenTelemetry standard; the field of service discovery has moved from CF platform routing to Kubernetes standard DNS; and the configuration management field has moved from Spring Cloud Config’s REST API to Kubernetes standard ConfigMap/Secret.
The driving force for this standardization is the fragmentation of the cloud native ecosystem—enterprises use multiple technology stacks and require unified standards across stacks. Open standards reduce the risk of vendor lock-in and facilitate tool chain interoperability.
5. Looking at today’s governance landscape from the practical perspective of enterprise-level CF platforms
5.1 2019 concerns vs 2026-03 reality
In 2019, the enterprise-level CF platform architecture has entered a period of transformation, and the industry has some concerns about the future of the CF + Spring Cloud architecture. Looking back in 2026-03, some of these concerns have come true, while others have proven to be unfounded.
| areas of concern | Forecast for 2019 | The reality of 2026-03 | Evaluate |
|---|---|---|---|
| Kubernetes dominance | K8s will become mainstream and CF share will decline | Kubernetes continues to serve as the de facto container orchestration base, with Gateway API v1.4 already GA and extending ingress, routing, and role boundary expressions | Prediction accurate |
| Service Mesh Popularity | Istio will become the standard | Istio 1.29 continues to promote the production availability of Ambient Mesh; Linkerd, Cilium and other solutions complement each other under different constraints, and Sidecar-less becomes a clear branch | partially accurate |
| Spring Cloud Netflix Decline | Netflix components will be replaced | Hystrix is in maintenance mode; the mainline implementation of Spring Cloud Circuit Breaker has moved to Resilience4j and Spring Retry | Prediction accurate |
| Multi-cloud architecture requirements | Enterprises will require cross-cloud deployment capabilities | Multi-cloud and hybrid cloud have become the norm in platform engineering. Enterprises pay more attention to the consistency of policies, identities, observations and delivery paths, rather than just cluster abstraction consistency. | Prediction accurate |
| Complete disappearance of CF | CF may be phased out completely | The CF idea has not gone away, but has been remixed in the form of Cloud Native Buildpacks, internal developer platforms, Golden Path, and Kubernetes extension platforms | Forecasts are too pessimistic |
This comparison table reflects a basic law of technology evolution: paradigm shifts will occur, but old technologies will not disappear immediately; mainstream technologies will be replaced by new standards, but enterprise-level scenarios will always have legacy systems that need to be maintained. **
5.2 Kubernetes extension platform: from PaaS thinking to platform engineering
The key lessons learned from the enterprise-level CF platform era are not a product or project name, but three platform engineering principles: platform hosting runtime complexity, application teams only exposing business capabilities, and governance capabilities delivered through a unified control plane. Entering the Kubernetes era, these principles have not disappeared, but have been recombined into Buildpacks, Operators, Gateway APIs, Service Mesh, OpenTelemetry, GitOps, and internal developer platforms.
The core value of this transformation lies in bridging: existing applications do not have to be rewritten as “pure Kubernetes native applications” at once. The platform team can first provide standard construction, unified entrance, identity access, telemetry collection and release pipeline, and then gradually migrate runtime scheduling, policy governance and expansion mechanisms to the underlying Kubernetes capabilities.
**Runtime bridging. ** Cloud Native Buildpacks continues the developer experience of CF buildpack: developers submit code, and the platform is responsible for building images, injecting runtime dependencies, and generating deployable artifacts. The difference from the early CF is that the product form has changed from a controlled droplet to a standard OCI image, and can subsequently enter Kubernetes, GitOps and image security scanning links.
**Governance bridging. ** Ingress management gradually shifts from platform routers to Gateway API, and east-west management shifts from application libraries and centralized gateways to Service Mesh or sidecarless data plane. Governance capabilities are still provided uniformly by the platform, but the expression mode shifts from platform private configuration to Kubernetes standard resources and policies as code.
**Observation bridge. ** The log, indicator and event system in the CF era solve the problem of “whether the platform can see the application.” OpenTelemetry, Prometheus, Profiling and eBPF in the Kubernetes era further solve the problem of “whether different runtimes, different languages, and different clusters can use the same semantics to understand the system.”
The judgment revealed by this evolution is: **Cloud Foundry’s platform concept still has value, but the implementation layer must move to open standards and composable control surfaces. ** Layered governance, separation of concerns, and developer experience priority still hold true, but the underlying runtime has shifted from Diego to Kubernetes, and the governance layer has shifted from the in-application framework to the Gateway API, Mesh, Policy, and OTel ecosystem.
5.3 The inevitable trend of enterprise-level PaaS
The evolution from CF to Kubernetes platform engineering reflects a broader industry trend: **Enterprise-grade PaaS will not disappear, but it will change shape. **
PaaS (such as CF) around 2015 was a “walled garden” - applications had to follow the constraints of the platform and use the runtime and middleware provided by the platform. This uniformity brings management convenience, but it also limits flexibility.
PaaS (platform engineering based on Kubernetes) in 2026-03 is “assemblyable platform” - the platform team provides standardized capabilities (through CRD, Operator, Policy, Gateway API, OpenTelemetry and GitOps workflow), and the application team maintains the flexibility of technology choices within these constraints. The scalability of Kubernetes makes this model possible.
The driving force behind this shift is the need for developer productivity. Enterprises need platforms to reduce operational complexity, but developers don’t want to go back to restricted “walled gardens.” Platform engineering based on Kubernetes attempts to strike a balance between the two:
- Golden Path: The platform team provides recommended technology stacks and templates, but their use is not mandatory
- Self-Service: Developers can obtain resources by themselves through Portal or GitOps without submitting a work order.
- Guardrails: Enforce security compliance constraints with Policy-as-Code (OPA, Kyverno) instead of relying on manual approvals.
More and more companies are building their own Internal Developer Platform (IDP). The rise of IDP tools such as Backstage, Port, and Cortex has verified this trend: the goal of the platform is not to make all technical choices for the development team, but to front-end security, delivery, observation, and compliance constraints into a clear self-service path.
6. Architect Insight: Separation of Principles and Tools
6.1 Essential issues of microservice governance
Industry practice from 2015 to 2026 (to date) shows that the core issue of microservice governance is not technology selection, but the matching of organizational capabilities and technical complexity.
Microservices architecture introduces all the complexities of distributed systems: network partitioning, eventual consistency, cascading failures, deployment coordination. The role of governance tools and platforms is to control these complexities so that development teams can reliably build and run distributed applications.
But this control comes at a cost. Every time a governance component (service discovery, circuit breaker, tracing) is introduced, a failure point is added to the system and a concept that needs to be learned and mastered. The architect’s job is to find a balance between “governance capabilities” and “system complexity”.
The balance around 2015 is Cloud Foundry + Spring Cloud Netflix. This platform provides sufficient governance capabilities while keeping complexity within manageable limits. This is a reasonable choice for enterprise-grade CF platforms with thousands of Java developers.
The balance point for 2026-03 is Kubernetes + Gateway API + Service Mesh or sidecar-less data plane + OpenTelemetry + GitOps. The cloud platform natively provides more powerful governance capabilities, but also introduces more concepts and components. Architects need to evaluate the team’s learning ability and operation and maintenance capabilities, and choose the appropriate governance level.
6.2 Eternal design principles vs. obsolete implementation tools
How to distinguish between “eternal design principles” and “implementation tools that will be obsolete”? The following are several judgment criteria:
Features of Timeless Design Principles:
-
**Not related to specific technology. ** Layered governance, separation of concerns, configuration externalization - these principles do not depend on any specific tool and are as applicable in the CF era as they are in the Kubernetes era.
-
**Resolve structural issues. ** Observability first, fault isolation, zero-downtime deployment - these principles solve the inherent problems of distributed systems and need to be considered whenever building distributed systems.
-
**Proven through multiple generations of technology. ** The idea of layered architecture has been used from monolithic applications to SOA to microservices; the circuit breaker mode keeps the core logic unchanged from Hystrix to Service Mesh.
Characteristics of implementation tools that will be obsolete:
-
**Tightly coupled to a specific runtime. ** Hystrix’s thread pool model is bound to Java’s thread model and is not suitable for the coroutine/asynchronous model.
-
**Weakened vendor or community support. ** Hystrix enters maintenance mode, Spring Cloud Netflix is marked as obsolete; Dynatrace is still evolving, but its proprietary formats are being squeezed out by open standards.
-
**Replaced by standardized solutions. ** Config Server’s REST API is replaced by Kubernetes’ ConfigMap/Secret standard; Eureka’s registration protocol is replaced by Kubernetes DNS standard.
6.3 Practical advice for architects
Based on the industry experience from 2015-2026 (to date), here are some suggestions for architects who are making technology selection:
**Recommendation 1: Give priority to standardized solutions. **
When faced with technology choices, give priority to solutions that comply with industry standards and have an active community. Proprietary solutions may have advantages in some aspects, but in the long run, standardized solutions have better maintainability and talent availability. OpenTelemetry is replacing various proprietary APMs, Prometheus is becoming the metrics standard, and Kubernetes is becoming the container orchestration standard—these trends should influence your selection decisions.
**Recommendation 2: Control the breadth of the technology stack. **
Microservice governance involves many areas: service discovery, load balancing, circuit breaker, current limiting, authentication, authorization, tracking, measurement, and logging. Don’t try to choose the “best” tool in every area, which can lead to an overly complex technology stack. Instead, choose a well-integrated combination (like Kubernetes + Istio + Prometheus + Grafana + Jaeger) and accept the trade-offs.
**Recommendation three: Reserve space for migration. **
Technology evolves, and the best option today may need to be replaced five years from now. Portability should be considered when designing the architecture: avoid deep coupling with specific tools, use abstraction layers to encapsulate external dependencies, and keep domain logic independent. In this way, when the service discovery or circuit breaker scheme needs to be replaced, the impact scope can be controlled at the boundary layer.
**Recommendation 4: Invest in platform engineering capabilities. **
Whether using Cloud Foundry, Kubernetes, or a self-developed platform, enterprise-level microservice governance requires a dedicated “platform engineering” team. This team is responsible for maintaining governance infrastructure, developing best practices, and providing developer support. Treating the platform as a product and providing a good user experience (documentation, tools, automation) for internal developers is more important than the specific technology chosen.
7. Conclusion: Dialectical perspective of technological evolution
Looking back at the enterprise-level CF platform practices from 2015 to 2020, there are both affirmations of the decisions made that year and feelings about the evolution of technology.
To be sure, the architects back then made reasonable choices with incomplete information. Cloud Foundry was the most mature enterprise-level PaaS at the time, Spring Cloud Netflix was a reliable encapsulation of Netflix’s production practices, and the three-tier routing architecture clearly separated concerns. These decisions supported the microservice transformation of the core products of the enterprise-level CF platform and laid the foundation for the subsequent cloud-native evolution.
Sadly, the speed and depth of technological evolution have exceeded expectations back then. Kubernetes has grown from a 0.x experimental project to the cornerstone of the cloud native ecosystem, Service Mesh has changed from a concept to a production standard, and eBPF has changed from a kernel feature to a platform for infrastructure innovation. What seemed like an advanced solution back then has obvious limitations from today’s perspective.
But this sentiment should not turn into a denial of the past. Technology selection is always the optimal solution at a specific point in time, not the eternal truth. The architect’s responsibility is not to predict the future but to make sustainable decisions within current constraints while leaving room for future evolution.
The next article in this series will discuss how observability evolves from surveillance screens to governance decision-making systems. Subsequent articles will continue to summarize traffic governance, elastic fault tolerance, release governance, and the architect’s perspective to help readers connect CF practices from 2015 to 2020 with the cloud native governance landscape from 2026 to 03.
About the author
Milome has more than ten years of experience in enterprise-level architecture design. He has served as a senior architect for enterprise-level CF platforms and has led the architecture design and implementation of multiple large-scale microservice platforms. Currently focusing on the research and practice of cloud native technology architecture and governance system.
Preview of series of articles:
- Part 2: Observability-driven governance—from large monitoring screens to precise decision-making systems
- Part 3: The evolution of traffic management—from Spring Cloud Gateway to Gateway API and Ambient Mesh
- Part 4: Redefining elastic fault tolerance—from Hystrix to adaptive governance
- Part 5: The evolution of release governance—from manual approval to progressive delivery
- Part 6: Summary—An architect’s perspective on enterprise-level microservice governance
Reference and further reading
- Cloud Foundry official documentation: https://docs.cloudfoundry.org/
- Spring Cloud Netflix Documentation (archived): https://spring.io/projects/spring-cloud-netflix
- NETFLIX Hystrix project status: https://github.com/NETFLIX/Hystrix
- Spring Cloud Circuit Breaker Documentation: https://spring.io/projects/spring-cloud-circuitbreaker
- Gateway API project documentation: https://gateway-api.sigs.k8s.io/
- Gateway API v1.4 Release Notes: https://kubernetes.io/blog/2025/11/06/gateway-api-v1-4/
- Istio 1.29 Release Notes: https://istio.io/latest/news/releases/1.29.x/announcing-1.29/
- OpenTelemetry Specification Status: https://opentelemetry.io/docs/specs/status/
- Cilium Service Mesh Documentation: https://docs.cilium.io/en/stable/network/servicemesh/
- Cloud Native Buildpacks Documentation: https://buildpacks.io/docs/
- Backstage Documentation: https://backstage.io/docs/
- CNCF Cloud Native Landscape: https://landscape.cncf.io/
- Martin Fowler - Microservices Resource Guide: https://martinfowler.com/microservices/
- Brendan Burns - Designing Distributed Systems (O’Reilly, 2018)
*This article is based on the author’s personal practice in the field of enterprise-level microservice governance. All technical opinions represent only personal experience and observations and do not constitute an official evaluation of any product or technology. *
Series context
You are reading: From enterprise-level CF platform to cloud native: more than ten years of evolution of enterprise-level microservice governance
This is article 1 of 6. Reading progress is stored only in this browser so the full series page can resume from the right entry.
Series Path
Current series chapters
Chapter clicks store reading progress only in this browser so the series page can resume from the right entry.
- From enterprise-level CF platform to cloud native (1): Architect's review - the gains and losses of microservice governance in the era of enterprise-level CF platform Based on the front-line architecture practice of enterprise-level CF platforms from 2015 to 2020 and industry observations from 2015 to 2026 (to date), we review the microservice governance design decisions in the Cloud Foundry era and analyze which ones have withstood the test of time and which ones have been reconstructed by the cloud native wave.
- From enterprise-level CF platform to cloud native (2): Observability-driven governance—from monitoring large screens to precise decision-making systems With 6 years of practical experience as an enterprise-level platform architect, we analyze the core position of observability in microservice governance, from data islands to OpenTelemetry unified standards, and build a governance system for accurate decision-making.
- From enterprise-level CF platform to cloud native (3): The evolution of traffic management - from Spring Cloud Gateway to Gateway API and Ambient Mesh Review the practice of Spring Cloud Gateway in the enterprise-level CF platform, analyze the standardization value of Kubernetes Gateway API, explore the evolution logic from Service Mesh to Ambient Mesh, and provide a decision-making framework for enterprise traffic management selection.
- From enterprise-level CF platform to cloud native (4): Redefining elastic fault tolerance—from Hystrix to adaptive governance Review Hystrix's historical position in microservice elastic governance, analyze Resilience4j's lightweight design philosophy, explore new paradigms of adaptive fault tolerance and chaos engineering, and provide practical guidance for enterprises to build resilient systems.
- From enterprise-level CF platform to cloud native (5): The evolution of release governance—from manual approval to progressive delivery Review the manual approval model of traditional release governance, analyze the evolution of blue-green deployment and canary release, explore the new paradigm of GitOps and progressive delivery, and provide practical guidance for enterprises to build an efficient and secure release system.
- From enterprise-level CF platform to cloud native (6): Summary—an architect’s perspective on enterprise-level microservice governance Review the evolution of microservice governance over the past ten years from 2015 to 2026 (to date), refine the first principles of architects, summarize the implementation paths and common pitfalls of enterprise-level governance, look forward to future trends, and provide a systematic thinking framework for technical decision-makers.
Reading path
Continue along this topic path
Follow the recommended order for Microservice governance instead of jumping through random articles in the same topic.
Next step
Go deeper into this topic
If this article is useful, continue from the topic page or subscribe to follow later updates.
Loading comments...
Comments and discussion
Sign in with GitHub to join the discussion. Comments are synced to GitHub Discussions