Article
Java Memory Model Deep Dive: From Happens-Before to Safe Publication
A production-grade deep dive into JMM, happens-before, volatile, final fields, optimistic locking, memory barriers, cache coherence, lock semantics, HotSpot implementation, and concurrency diagnostics.
Verification date: 2026-05-14. Version baseline: JDK 26 GA, JDK 25 LTS, and JDK 27 EA. This article follows the Java Language Specification, Chapter 17, and the JSR-133 memory model revision. HotSpot implementation snippets are conceptual unless explicitly identified as source excerpts.
Abstract
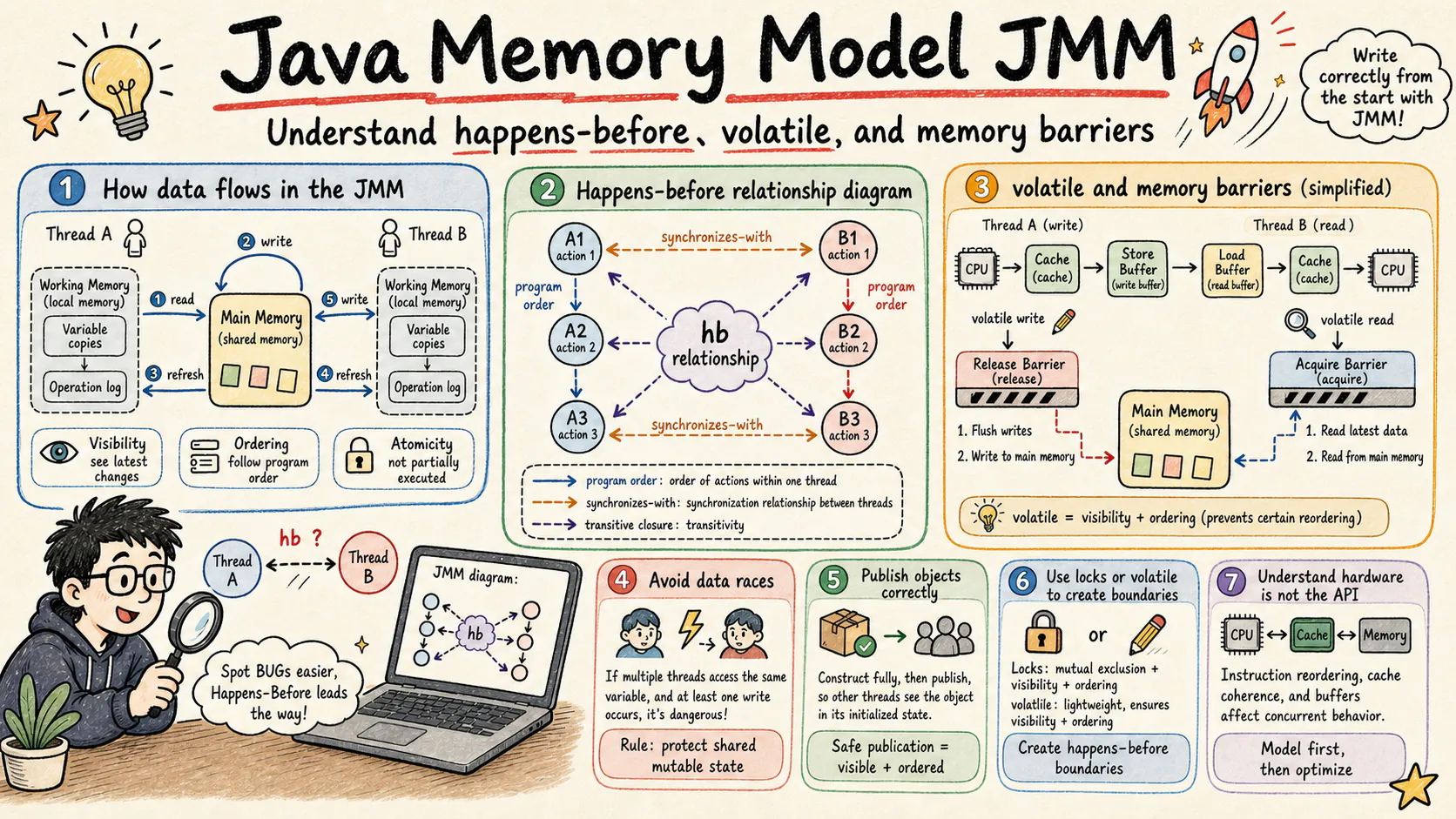
The Java Memory Model, usually shortened to JMM, is the contract that makes Java concurrency portable. It does not expose every store buffer, cache-coherence message, compiler scheduling decision, or CPU pipeline detail. Instead, it defines which writes are allowed to be observed by which reads, which reordering is legal, and which synchronization actions create cross-thread visibility.
This article builds the model from the bottom up: multi-core cache behavior, execution actions, synchronizes-with edges, happens-before closure, volatile release/acquire semantics, final-field safe publication, memory barriers, cache-coherence protocols, instruction reordering, lock semantics, false sharing, production bug diagnosis, and the HotSpot implementation boundary.
The goal is not to memorize rules. The goal is to develop a reliable mental model:
- A data race is not a performance smell. It is a correctness boundary.
volatileis a publication and ordering tool, not a compound-operation lock.finalhelps safe construction, but it does not make object graphs deeply immutable.synchronizedis both mutual exclusion and a memory-ordering construct.- Hardware mechanisms explain why barriers are expensive, but JMM remains the language-level authority.
Table of Contents
- Why a Memory Model Exists
- JSR-133 and the Modern JMM
- Happens-Before: Formal Definition and Derivation
- Optimistic Locking and Microservice Concurrency
- Volatile Semantics and Implementation
- Final Fields and Safe Publication
- Memory Barriers and Hardware Mapping
- Cache Coherence Protocols
- Instruction Reordering and As-If-Serial Semantics
- Synchronized and Lock Memory Semantics
- False Sharing and Cache-Line Optimization
- Classic Case Studies
- Benchmarking Padding and Contention
- JSR-133 Formal Semantics Supplement
- Processor Memory Models
- Production Diagnosis and Case Studies
- HotSpot VM Implementation Reading Guide
- Performance Practices and Checklists
- Summary and Outlook
1. Why a Memory Model Exists
1.1 Multi-Core Memory Consistency Is Not Intuitive
A single-threaded Java program gives the illusion that instructions execute in source order. Modern hardware does not actually work that way. Each CPU core has registers, private caches, store buffers, invalidate queues, branch predictors, reorder buffers, and multiple execution units. The compiler also rewrites code aggressively as long as it preserves allowed behavior.

Figure: Modern CPU cache hierarchy. Access latency rises from registers and L1 to shared L3 and DRAM, which is why processors hide memory latency with buffering and reordering.
The practical consequence is simple: two threads can execute code that looks obvious, yet observe different orders of writes unless the program establishes a synchronization relationship.
Consider this unsafe publication example:
final class UnsafeFlag {
private int value;
private boolean ready;
void writer() {
value = 42;
ready = true;
}
int reader() {
if (ready) {
return value;
}
return -1;
}
}Without synchronization, the reader is not guaranteed to observe value = 42 after it observes ready = true. The compiler and CPU may expose the writes in an order that is legal for a data-racy program. Even when it works in a test, the result is not a Java guarantee.

Figure: Store buffers can delay when a write becomes visible to other cores. JMM synchronization actions define when such writes must become visible at the language level.
1.2 Thread Working Memory Is an Access Path, Not an Object Copy
The phrase “working memory” in JMM is often misunderstood. It does not mean that every Java object is copied into a per-thread heap. It is an abstraction for the local state through which a thread observes shared variables: registers, compiler temporaries, CPU caches, store buffers, and other implementation-level mechanisms.

Figure: JMM uses the working-memory abstraction to reason about visibility between threads. The actual implementation may involve registers, caches, write buffers, and invalidation queues.
If two threads execute count = count + 1 without synchronization, the operation is a read-modify-write sequence. The threads can read the same old value, compute the same new value, and overwrite each other. JMM does not repair that race. It only defines the consequences of programs that establish synchronization correctly.
1.3 JMM Design Goals
JMM balances three forces:
- Programmers need a model that is easier to reason about than every CPU architecture.
- Compilers and processors need enough freedom to optimize.
- Correctly synchronized programs need portable behavior.

Figure: JMM sits between sequential consistency and maximum optimization freedom. The central guarantee is data-race-free programs behaving as if they were sequentially consistent.
Sequential consistency is easy to explain: all operations appear to run in one global order that is consistent with each thread’s program order. It is also too restrictive for modern processors and optimizing compilers. JMM chooses a more practical model: it gives strong guarantees to correctly synchronized programs and deliberately gives fewer guarantees to data-racy programs.
1.4 Actions, Executions, and Relations
JMM reasons about actions. An action can be a normal read, normal write, volatile read, volatile write, monitor lock, monitor unlock, thread start, thread termination detection, interruption detection, or another synchronization-related event.
The model then defines relations between actions:
- Program order orders actions inside one thread.
- Synchronization order is a total order over synchronization actions.
- Synchronizes-with is a subset of synchronization-order-derived edges that have memory meaning.
- Happens-before is the transitive closure built from program order and synchronizes-with.
A useful shorthand is this: if action A happens-before action B, then A’s effects are visible to B according to the JMM visibility rules. The reverse is not automatically true; a write can sometimes be observed without being a synchronization guarantee, but a program should not rely on that accident.
2. JSR-133 and the Modern JMM
2.1 Historical Motivation
The original Java memory model was not precise enough for real-world concurrent libraries. It made common patterns such as double-checked locking ambiguous and left too much room for different JVMs to behave differently. JSR-133 revised the model for Java 5 and became the foundation for java.util.concurrent, modern volatile semantics, final-field semantics, and lock-based publication.

Figure: JMM evolved from the early Java model to the JSR-133 revision and later APIs such as VarHandle.
The revision did not make all concurrency easy. It made the rules precise enough for libraries, virtual machines, and application engineers to reason about correctness.
2.2 The Core Design Choice
JSR-133 did not choose pure sequential consistency for all programs. It chose a happens-before model.

Figure: The happens-before model is a compromise: stronger and more portable than raw hardware behavior, less restrictive than sequential consistency for every program.
The decision matters because Java code runs on x86, ARM, POWER, RISC-V, virtualized cloud hardware, JIT-compiled code, interpreted code, and ahead-of-time compiled code. The same source program needs a language-level contract that survives all of those targets.

Figure: The DRF guarantee says that correctly synchronized programs can be understood through sequential consistency, even though the implementation may use aggressive optimization.
2.3 Core Improvements
JSR-133 clarified four major areas:
volatilereads and writes participate in happens-before.finalfields receive special construction-time guarantees.- monitor unlock and monitor lock establish synchronization on the same monitor.
- thread start and termination rules become part of the memory model.
The volatile publication pattern is the smallest useful example:
public final class FixedVolatile {
private int x = 0;
private volatile boolean flag = false;
public void writer() {
x = 42; // (1)
flag = true; // (2) volatile write
}
public void reader() {
if (flag) { // (3) volatile read
System.out.println(x); // (4)
}
}
}The visibility chain is:
This chain is valid when the volatile read observes the volatile write, or more precisely when the volatile write is earlier in the synchronization order for the same volatile variable. The important point is that (1) is an ordinary write, but it is published through the volatile write (2).
The monitor example is equally important:
// Thread A
synchronized (monitor) {
x = 1; // A
} // B: unlock
// Thread B
synchronized (monitor) {
// C: lock
int r = x; // D
}JSR-133 gives this chain:
Therefore D must be able to observe the write from A, assuming both synchronized blocks use the same monitor object and the second lock happens after the first unlock.
Thread start has a similar rule:
Thread t = new Thread(() -> {
System.out.println(x); // B
});
x = 42; // A
t.start(); // CThe start rule gives:
2.4 Limits of the Specification
JMM is a correctness model, not a performance model. It does not promise that volatile is cheap, that lock implementation details stay fixed across JDK versions, or that one CPU instruction is always emitted for one Java action.

Figure: The compiler may reorder ordinary operations as long as it does not violate required Java semantics. Synchronization actions form optimization boundaries.
This distinction prevents a common mistake: reading a HotSpot assembly dump and then treating it as the Java specification. HotSpot is an implementation. JMM is the contract.
2.5 What “Correctly Synchronized” Means
In engineering terms, a program is correctly synchronized when every shared mutable access that can race is ordered by a synchronization mechanism. Sequential consistency is not an extra premise. It is the guarantee that JMM gives to data-race-free programs.
The boundary is:
- no data race means the program can be reasoned about in a sequentially consistent way;
- a data race means the program has left that reasoning zone;
- accidental behavior on one architecture is not a guarantee.
2.6 A Transitive Example and Its Limit
Volatile can act as a bridge across threads:
final class VolatileBridge {
int x;
volatile int v1;
volatile int v2;
int y;
void threadA() {
x = 1; // A
v1 = 1; // B
}
void threadB() {
int r1 = v1; // C
y = r1 + 1; // D
v2 = 1; // E
}
void threadC() {
int r2 = v2; // F
}
}If all intermediate reads and writes actually occur in the required synchronization order, the chain can be written as:
The limit is important: the chain is not magic. If threadB never reads v1, or if threadC reads an earlier value of v2, the intended transitive bridge is not established.
3. Happens-Before: Formal Definition and Derivation
3.1 Symbol Conventions
This article uses the following notation:
- capital letters such as
A,B, andCrepresent actions; - lower-case names such as
t1andt2represent threads; pomeans program order;someans synchronization order;swmeans synchronizes-with;hbmeans happens-before.
The arrows appear inside formulas so that the rendered page remains readable and mobile-safe.
3.2 The Core Rules
Program order: within one thread, each action happens-before later actions in that thread.
Monitor lock rule: an unlock on a monitor happens-before a later lock on the same monitor.
Volatile variable rule: when a volatile write is earlier in synchronization order than a read of the same volatile variable, the write happens-before the read:
Thread start rule: actions before Thread.start() happen-before actions in the started thread:
Thread termination rule: all actions in a thread happen-before a successful termination detection such as join() returning:
Interruption rule: a call to interrupt() happens-before the interrupted thread detects the interruption:
Finalizer rule: completion of an object’s constructor happens-before the start of its finalizer:
The finalizer rule is mostly historical and should not be used as a modern resource-management technique. Prefer try-with-resources, Cleaner where appropriate, explicit ownership, or structured lifecycle management.
3.3 Hasse and DAG Views

Figure: A volatile write can connect ordinary writes before it to ordinary reads after a matching volatile read.

Figure: The monitor rule only applies when both sides use the same monitor object.

Figure: Happens-before is built from program order and synchronizes-with edges, then closed under transitivity.

Figure: A Hasse-style view removes redundant transitive edges and helps engineers see the minimal ordering structure.

Figure: Happens-before can be visualized as an acyclic directed graph over actions.
3.4 Closure Definition
The compact definition is:
Here, po is program order, sw is synchronizes-with, and the superscript plus means transitive closure.
3.5 Data Race Definition
Two accesses A and B form a data race when all of the following are true:
AandBare from different threads.AandBaccess the same memory location.- At least one of them is a write.
- Neither access happens-before the other.
Let D = DR(A,B) mean that the two actions form a data race, T = T(A,B) mean that they belong to different threads, L = L(A,B) mean that they access the same location, and W_A / W_B mean that A / B is a write:
This is a full equivalence because it is defining the data-race predicate in this article’s local notation. The “different threads” condition is essential: two actions in the same thread are ordered by program order and therefore cannot form this kind of data race.
3.6 A Minimal Fix
final class FixedDataRace {
private volatile int sharedVar;
void writer() {
sharedVar = 1; // (1) volatile write
}
int reader() {
return sharedVar; // (2) volatile read
}
}When volatile read (2) is later than volatile write (1) in the synchronization order for the same variable, the core relation is:
This fixes visibility for the read of sharedVar. It does not turn arbitrary compound operations on sharedVar into atomic transactions.
3.7 From Single-JVM Correctness to Distributed Concurrency
JMM stops at the boundary of one Java execution. It does not order messages across Kafka partitions, database updates, Redis writes, RPC retries, or cross-service workflows. In distributed systems, an application must add stronger mechanisms:
- database constraints and transaction isolation;
- compare-and-set updates with version columns;
- idempotency keys;
- message ordering by key;
- optimistic locking with retry budgets;
- external linearizable stores when necessary.
JMM prevents unsafe reasoning inside a JVM. It does not replace distributed concurrency control.
3.8 Engineering Patterns for Happens-Before
In production code, happens-before is less useful as a theorem to memorize than as a review technique. A reviewer should be able to point to the exact edge that publishes a write and the exact edge that makes the reader acquire it. If the edge cannot be named, the design is usually relying on timing, CPU behavior, or accidental implementation details.
| Pattern | Publishing edge | Reading edge | What it protects | What it does not protect |
|---|---|---|---|---|
volatile reference to immutable snapshot | volatile write | later volatile read of the same field | visibility of the constructed snapshot and prior ordinary writes | multi-field mutation after publication |
synchronized critical section | monitor unlock | later monitor lock on the same monitor | invariants guarded by that monitor | code that reads the same state without that monitor |
Thread.start() handoff | actions before start() | first action in started thread | data prepared before thread start | later unsynchronized mutation |
Thread.join() completion | all actions in worker thread | successful return from join() | results written before termination | background work not joined |
| Blocking queue handoff | enqueue operation inside library synchronization | dequeue operation inside library synchronization | message object visibility | external ordering across unrelated queues |
CompletableFuture completion | completion action | dependent stage execution | completion result visibility | shared mutable data captured by callbacks without discipline |
A small safe-publication example shows the intended review style:
final class SnapshotRegistry {
private volatile Snapshot current = Snapshot.empty();
void refresh(Map<String, String> source) {
Snapshot next = Snapshot.copyOf(source);
current = next;
}
Snapshot current() {
return current;
}
}The happens-before edge is the volatile write to current followed by a later volatile read of current. The snapshot itself must be immutable. If Snapshot stores a mutable HashMap and later mutates it, the volatile edge only publishes the reference safely; it does not serialize future map updates.
The same technique exposes common bugs:
final class BrokenRegistry {
private Snapshot current = Snapshot.empty();
void refresh(Map<String, String> source) {
current = Snapshot.copyOf(source);
}
Snapshot current() {
return current;
}
}There is no volatile field, no lock, no thread start or join boundary, and no library handoff. The fact that a reader “usually sees” the new snapshot on one machine is not a correctness argument.
3.9 From Local Data Safety to System-Level Race Safety
The most common enterprise mistake is to treat a Java lock as if it protected a business fact. A Java lock protects only the heap of the current JVM. It cannot protect the same database row from another service instance, a scheduled job, a message consumer, or an operational script.
| Question | Single JVM answer | Multi-instance answer |
|---|---|---|
| Who can write the state? | Threads inside one process | All replicas, batch jobs, consumers, and administrative paths |
| Where is the fact stored? | Java heap object | Database row, log, queue, object store, or external coordination service |
| Which edge orders writes and reads? | volatile, monitor, atomic class, thread lifecycle, or library synchronization | transaction isolation, conditional update, unique constraint, partition ordering, external CAS, or linearizable store |
| What is the retry boundary? | Method call or local task | idempotency key, request log, transaction id, outbox event, or saga step |
| What must be monitored? | contention, blocked threads, allocation, and latency | lock wait, deadlock, conflict rate, duplicate request rate, outbox lag, and retry amplification |
For a microservice, the right mental model is layered:
- Use JMM to make each service instance internally correct.
- Use database constraints and transactions to protect the durable fact.
- Use idempotency to survive client retries and message redelivery.
- Use partitioning, queues, or locks only to reduce contention, not as the only correctness boundary.
This is why an account deduction service may still use thread-safe Java components while putting the actual “balance must not become negative” invariant into a conditional SQL update. JMM makes the in-process implementation safe; the database update makes the business fact safe across replicas.
4. Optimistic Locking and Microservice Concurrency
4.1 The Boundary: JMM Safety Is Not Business Consistency
Happens-before answers a precise language-level question: if thread B reads a value, which writes is it allowed or required to observe? That is enough for safe publication, volatile handoff, lock-protected invariants, concurrent collections, and in-process queues. It is not enough for questions such as “can two service replicas deduct the same inventory item”, “can a retried payment callback be applied twice”, or “can a cache rebuild overwhelm the database”.
The production boundary is this: JMM is a thread memory contract; optimistic locking is a fact-source concurrency-control pattern; idempotency and outbox are distributed workflow patterns. They often appear in the same service, but they protect different things.
| State owner | Typical problem | Correct control point | Incorrect shortcut |
|---|---|---|---|
| One JVM heap | safe publication, counters, local caches | final, volatile, locks, CAS, concurrent collections | database lock for purely local state |
| One database row | balance deduction, inventory deduction, versioned config | conditional update, version column, row lock | read-check-write without a predicate |
| Multiple rows in one database | transfer, order state transition, batch inventory | local transaction, unique constraint, isolation level | several SQL statements outside one transaction |
| Cross-service state | payment, fulfillment, points, shipment | idempotency key, outbox, saga, compensation | wrapping remote calls in a Java lock |
| Cache state | stampede, duplicate load, hot key | single-flight loading, short TTL, async refresh | treating cache as the source of money or inventory |
| Message state | duplicate delivery, reordering, at-least-once delivery | consumer idempotency, partition by aggregate key, outbox | assuming broker-level exactly-once solves business effects |
4.2 What Optimistic Locking Really Means
Optimistic locking is not “no locking”. It is conditional submission. A caller reads a state snapshot, computes a change, and asks the fact source to accept that change only if the snapshot is still current and the business invariant still holds.
For a database aggregate, the shape is:
Here is the aggregate state, is the requested business change, is the version read by the caller, and is a business rule such as “balance must not become negative” or “inventory must not oversell”. The arrow is not a happens-before edge. It is a business rule saying that the fact source must reject stale or invalid writes.
Different layers have similar syntax but different safety boundaries:
| Layer | Common implementation | Protected object | Failure signal | Typical response |
|---|---|---|---|---|
| JVM memory | AtomicReference, VarHandle.compareAndSet | one address or reference inside one process | CAS returns false | spin, back off, or fall back to a lock |
| Database row | version column or updated_at condition | one aggregate row | updated row count is 0 | reread, bounded retry, conflict response |
| Database invariant | conditional SQL, unique constraint, transaction | balance, inventory, idempotency, legal state transition | predicate fails or unique key conflicts | business failure or historical idempotent result |
| HTTP resource | ETag and If-Match | one resource representation | 412 Precondition Failed | reload and resubmit |
| Message workflow | request ID, command ID, consumer log | one business effect | key already exists | return old result or skip duplicate |
The common accident is to protect the wrong layer: a local CAS succeeds, but another replica updates the row; a Redis lock is acquired, but the SQL update has no invariant predicate; a retry succeeds twice because the API has no idempotency key.
4.3 Single-Instance Services Still Need Fact-Source Protection
A single service instance is not a reason to keep business consistency in a Java lock. If the durable fact is in a database, the invariant belongs in the database update, a transaction, a unique constraint, or a versioned write. synchronized, ReentrantLock, and AtomicReference protect only one JVM’s heap.
The distinction is practical:
| Scenario | Safe inside the JVM | Must be protected by the fact source |
|---|---|---|
| local rate limiter | token bucket state for one instance | global quota, billing, inventory |
| local batch buffer | pending writes before flush | processed request log and durable result |
| local cache | account display snapshot | account balance and settlement status |
| local lock | one instance rebuilding a cache entry | all replicas deducting one account |
| local metric | approximate counter, latency histogram | audit amount and transaction history |
Designing single-instance services with fact-source protection has three long-term benefits. First, scaling from one replica to many does not rewrite the write path. Second, scheduled jobs, message consumers, admin operations, and compensation tasks reuse the same safety boundary. Third, the system has durable evidence for success, failure, conflict, and idempotent replay instead of relying only on process logs.
4.4 Multi-Instance Elastic Scaling: Race at the Shared Boundary
When a service scales horizontally, the race moves from “many threads entering one object” to “many processes writing the same row, aggregate key, or downstream resource”. No replica-local Java lock can coordinate that. All replicas must compete at the shared fact source.
For inventory, a typical boundary is:
UPDATE inventory
SET available = available - :quantity,
version = version + 1,
updated_at = CURRENT_TIMESTAMP
WHERE sku_id = :skuId
AND available >= :quantity
AND version = :expectedVersion;This statement is the multi-replica compare-and-set. sku_id identifies the same fact, available >= :quantity protects the “do not oversell” invariant, version = :expectedVersion prevents a stale snapshot from overwriting a newer state, and the affected row count tells the service whether the submission won.
If the invariant spans multiple rows or aggregates, a single version column is no longer enough. A two-account transfer needs a local transaction, row locks or a serializable constraint, unique ledger entries, and a clear audit trail. A cross-service order-payment-inventory workflow needs command idempotency, outbox events, saga state, retries, and compensations. A “global version number” across services is usually a design smell, not a distributed transaction protocol.
4.5 Retry Policy, Hot Keys, and When Optimism Fails
Optimistic locking is efficient when conflicts are rare and retries are bounded. It becomes dangerous when a hot key creates a retry storm. A high-demand flash-sale item, a celebrity account, or a popular coupon can turn every failed write into another read-compute-write loop against the same row.
Business failures and technical conflicts must be separated:
| Outcome | Retry? | Reason |
|---|---|---|
| insufficient balance | no | the business predicate is false |
| account frozen | no | the requested transition is illegal |
| version mismatch | maybe | another writer won first; reread may succeed |
| deadlock retry exception | maybe | the database aborted a conflicting schedule |
| short lock timeout | maybe | contention may clear after backoff |
| duplicate request ID | no new effect | return the historical result |
Bounded retry means: reread the latest state, recompute the command if needed, retry only a small number of times, apply exponential backoff with jitter, and emit conflict metrics. Retrying with the old version is not resilience. It is a deterministic conflict loop.
A useful decision matrix is:
| Conflict shape | Better strategy | Avoid |
|---|---|---|
| low conflict and user can wait | version optimistic lock plus 2 or 3 jittered retries | global pessimistic lock |
| medium conflict over many keys | partition by aggregate key, local queue, bounded retry | unlimited retry across all keys |
| hot inventory item | admission tokens, inventory buckets, reservation, queueing | every request retrying one versioned row |
| financial transfer | transaction, row locks, unique ledger, audit table | pretending one-row CAS protects a multi-row invariant |
| cross-service workflow | outbox, saga, idempotent commands, compensation | global version number or remote calls inside one local transaction |
4.6 Architecture View: Pair Optimistic Locking with Idempotency, Outbox, and Observability
Optimistic locking protects the aggregate owned by one service. It does not publish messages safely, deduplicate retried commands, coordinate remote services, or decide overload policy. A production-grade write path usually needs four layers:
- Admission control: rate limiting, bulkheads, queueing, and degradation prevent a hot key from destroying the database.
- Idempotency: every command, callback, and message has a business key protected by a unique constraint or log.
- Atomic fact update: the core invariant is enforced by conditional SQL, a version column, a transaction, a unique index, or a row lock.
- Recoverable side effects: outbox, transaction log, consumer idempotency, and compensation jobs handle asynchronous effects after commit.
The operational signals are part of the design, not an afterthought:
| Metric | Meaning | Bad signal |
|---|---|---|
optimistic_lock_conflict_total | version or conditional-update conflicts | sudden growth means a hot row or retry amplification |
deduct_retry_attempts | retry attempts per business request | high P95/P99 means optimism is no longer cheap |
idempotency_hit_total | repeated request keys | upstream timeout, client retry, or MQ redelivery spike |
outbox_lag_seconds | delay from outbox insert to publish | relay backlog or broker problem |
deduct_processing_stuck_total | logs stuck in PROCESSING | exception path or compensator is incomplete |
The concise rule is: protect invariants where facts live, design idempotency where duplication can occur, and add admission control where overload can be amplified. JMM keeps each JVM instance internally correct; optimistic locking and its surrounding patterns keep the business fact correct across replicas.
5. Volatile Semantics and Implementation
5.1 What Volatile Guarantees
volatile gives two practical guarantees:
- Visibility: a write to a volatile variable becomes visible to later reads of the same variable.
- Ordering: ordinary writes before a volatile write cannot be moved after that volatile write in a way that breaks the JMM rule, and ordinary reads after a volatile read cannot be moved before that volatile read in a way that breaks the rule.
The release/acquire analogy is useful:
- volatile write is close to release;
- volatile read is close to acquire;
- Java volatile also participates in a single synchronization order for volatile actions.
5.2 Correct Use Cases
Use volatile for:
- stop flags;
- publication of immutable or safely constructed state;
- simple state transitions where the transition itself is a single write;
- double-checked locking when the reference field is volatile;
- low-contention read-mostly configuration snapshots.
Do not use volatile for:
- counters with
++; - check-then-act sequences;
- multi-field invariants;
- compound state transitions;
- coordination that needs blocking, queuing, fairness, or ownership.
final class StopFlag {
private volatile boolean stopped;
void stop() {
stopped = true;
}
boolean shouldStop() {
return stopped;
}
}5.3 Double-Checked Locking
public final class SingletonHolder {
private static volatile Service instance;
public static Service get() {
Service local = instance;
if (local == null) {
synchronized (SingletonHolder.class) {
local = instance;
if (local == null) {
local = new Service();
instance = local;
}
}
}
return local;
}
}The volatile reference is the publication boundary. Without it, another thread could observe a reference to an object whose constructor effects are not safely visible.
Another correct pattern is publishing a complete immutable configuration snapshot:
public final class ConfigCenter {
private volatile RuntimeConfig config = RuntimeConfig.empty();
public RuntimeConfig get() {
return config;
}
public void reload(ConfigSource source) {
RuntimeConfig next = RuntimeConfig.from(source);
validate(next);
config = next;
}
}The update is a single reference assignment. Readers either see the old complete snapshot or the new complete snapshot. They never need to lock if RuntimeConfig is immutable. This pattern is common for feature flags, route tables, read-mostly rule sets, and local cache metadata.
The pattern breaks when the published object is mutated after publication:
public final class BrokenConfigCenter {
private volatile Map<String, String> config = new HashMap<>();
public void put(String key, String value) {
config.put(key, value);
}
public String get(String key) {
return config.get(key);
}
}The volatile field only protects the reference read and write. It does not make HashMap operations atomic, ordered, or safe. Fix the design by publishing immutable copies, using a concurrent collection with documented invariants, or guarding the mutable map with a lock.
The decision table is usually more useful than a slogan:
| Need | Good fit | Poor fit | Reason |
|---|---|---|---|
| stop flag | volatile boolean | ordinary boolean | one writer publishes a one-bit state |
| read-mostly immutable config | volatile reference to immutable object | mutable object behind volatile reference | volatile publishes the reference, not future mutation |
| counter | AtomicLong, LongAdder, lock | volatile long++ | increment is read-modify-write |
| two-field invariant | lock or immutable aggregate replacement | two independent volatile fields | readers can observe mixed versions |
| owner handoff with blocking | queue, latch, future, lock | volatile busy spin by default | libraries encode ordering and back pressure |
| cross-service asset update | database conditional update, transaction, version column | JVM volatile or local lock | other replicas do not share the same heap |
5.4 x86 and ARM Implementation Boundaries
The Java source code says volatile. The generated machine code depends on architecture, JDK version, compiler tier, and optimization phase. On x86, the memory model is relatively strong, so volatile reads often need no explicit fence-like instruction. Volatile writes usually require a stronger ordering point, historically implemented with locked instructions or equivalent mechanisms. On ARM, explicit barriers are usually more visible because the hardware memory model is weaker.
The key rule for engineers: reason from JMM first, use assembly only for performance investigation.
5.5 Performance Cost
Volatile is cheaper than a contended lock but more expensive than an ordinary field access. The cost comes from restricting compiler optimization, interacting with CPU ordering, and potentially affecting cache traffic. Always benchmark with JMH when volatile is on a hot path.
A useful performance review separates three costs:
| Cost source | What happens | Symptom |
|---|---|---|
| compiler constraint | the JIT cannot freely move ordinary accesses across the volatile boundary | fewer optimization opportunities |
| hardware ordering | the generated code may need acquire, release, or stronger ordering | higher latency per access on weakly ordered CPUs |
| coherence traffic | many cores repeatedly read or write the same cache line | degraded throughput and higher tail latency |
Do not replace a clear lock with volatile solely because a microbenchmark shows lower average latency. If the invariant is multi-field, the volatile version may be faster and wrong. If the code is a hot read-mostly path with immutable snapshots, volatile may be exactly the right tool. The deciding question is still semantic: what state is being published, who can mutate it, and which operation must be atomic?
For extreme read paths, prefer a benchmark shape that matches the real access pattern:
@State(Scope.Group)
public class VolatileReadBenchmark {
private volatile RuntimeConfig config = RuntimeConfig.empty();
@Benchmark
@Group("readMostly")
public String read() {
return config.lookup("feature");
}
@Benchmark
@Group("readMostly")
public void write() {
config = RuntimeConfig.next();
}
}The benchmark must model reader/writer ratio, object size, allocation rate, CPU topology, and expected contention. A single-threaded volatile benchmark mainly measures a different program.
6. Final Fields and Safe Publication
6.1 Final Field Semantics
final fields receive special treatment at the end of object construction. If the constructor completes normally and this does not escape during construction, another thread that obtains the object reference through a valid publication path can reliably see the final fields as initialized by the constructor.
public final class SafePoint {
private final int x;
private final int y;
public SafePoint(int x, int y) {
this.x = x;
this.y = y;
}
}6.2 Final Is Not Deep Immutability
public final class Catalog {
private final List<String> names;
public Catalog(List<String> names) {
this.names = new ArrayList<>(names);
}
public List<String> names() {
return List.copyOf(names);
}
}The reference is final. The object behind the reference must still be protected through immutability, defensive copying, confinement, or synchronization.
6.3 This Escape
public final class BadEscape {
private final int value;
public BadEscape(EventBus bus) {
bus.register(this); // this escapes before construction finishes
this.value = 42;
}
}Publishing this from the constructor breaks the safe-construction premise. This includes registering listeners, starting threads, submitting tasks, exposing this through lambdas, and storing the reference in a static field.
6.4 Cache Lines and Object Layout
Final-field semantics are about visibility and initialization safety. They are not a cache-line placement guarantee. Object layout, field packing, compressed oops, alignment, and padding are JVM implementation details. Use JOL or JFR-style evidence when layout matters.
7. Memory Barriers and Hardware Mapping
7.1 What a Barrier Does
A memory barrier constrains the ordering of memory operations. It does not necessarily “flush everything to RAM”; that phrase is often misleading. Real implementations coordinate compiler ordering, store buffers, cache coherence, and load visibility.

Figure: Out-of-order execution improves pipeline utilization, but synchronization boundaries restrict which reorderings are legal.
The four common abstract barrier categories are:
- LoadLoad: loads before the barrier complete before later loads.
- LoadStore: loads before the barrier complete before later stores.
- StoreStore: stores before the barrier become ordered before later stores.
- StoreLoad: stores before the barrier are ordered before later loads; this is often the most expensive category.
The names are abstract. They describe constraints, not necessarily one machine instruction. A JIT compiler can satisfy a Java-level ordering requirement through an instruction, a locked operation, a compiler barrier, a dependency, a platform-specific acquire or release access, or by proving that no emitted barrier is needed in that context.
| Abstract barrier | Intuition | Typical Java source that may require it | Engineering warning |
|---|---|---|---|
| LoadLoad | earlier reads stay before later reads | acquire-style read, volatile read path | not a cache refresh button |
| LoadStore | earlier reads stay before later writes | monitor enter, acquire boundary | often bundled with other constraints |
| StoreStore | earlier writes stay before later writes | release-style write, volatile publication | common for safe publication |
| StoreLoad | earlier writes stay before later reads | full-fence-like boundary, some volatile write paths | usually the strongest and most expensive category |
The phrase “flush to main memory” hides too much. A barrier may stop compiler motion, drain or order a store buffer, make invalidations visible before later loads, or participate in a locked instruction protocol. The observable Java guarantee is still defined by JMM, not by a simplified RAM metaphor.
7.2 x86 TSO

Figure: x86 TSO is relatively strong. Store-to-load reordering through store buffers is the most important remaining case.
On x86, many Java ordering requirements map to ordinary loads and stores plus locked operations when a stronger boundary is needed. That does not mean volatile has zero cost. It still constrains compiler motion and can cause coherence traffic.
The important nuance is store buffering. A core can place a store into its local store buffer and continue executing later loads before the store becomes visible to other cores. That is why store-load ordering remains special even on a relatively strong architecture. Java code should not try to exploit the exact x86 behavior; it should express the required ordering through JMM constructs.
7.3 ARM Weak Ordering

Figure: ARM allows more reorderings, so JVMs must use explicit ordering instructions more often.

Figure: ARM barrier families such as DMB, DSB, and ISB serve different ordering and synchronization purposes.
ARM makes the abstraction cost easier to see. Independent loads and stores can be observed in more orders unless the implementation uses the right acquire, release, or barrier instructions. That does not make Java weaker on ARM. It means the JVM has more work to do to preserve the same Java-level contract.
| Platform intuition | x86-like target | ARM-like target |
|---|---|---|
| ordinary read ordering | often already strong enough | may need acquire-style support depending on context |
| ordinary write publication | relatively strong store ordering | release-style ordering is more visible |
| volatile read | often ordinary load plus compiler constraints | acquire load or barrier-backed sequence |
| volatile write | ordinary store plus stronger boundary when needed | release store and additional ordering when required |
| monitor enter/exit | locked operations can provide ordering | explicit barriers are more common |
7.4 JMM Mapping

Figure: JVMs map Java-level volatile and monitor operations to architecture-specific ordering mechanisms.
The mapping is not one-to-one. A Java volatile write is a semantic event. The generated implementation may use different instruction sequences depending on the CPU, JIT tier, and JDK.
When reading JIT output, use this checklist:
- Identify the Java semantic event: volatile read, volatile write, monitor enter, monitor exit, CAS, final-field publication, or VarHandle mode.
- Identify the target CPU and JDK build.
- Check whether the ordering is carried by an explicit fence, a locked operation, an acquire/release access, or a compiler scheduling constraint.
- Avoid generalizing one emitted sequence into a language rule.
- Confirm the performance claim with JMH and production telemetry.
8. Cache Coherence Protocols
8.1 Visibility Starts with Coherence, but Does Not End There
Cache coherence protocols keep copies of cache lines from becoming permanently contradictory. They do not by themselves define Java-level synchronization. JMM uses synchronization actions to define what Java code can rely on.

Figure: Without timely coherence and ordering, one core can observe stale data from another core’s write.
8.2 MESI

Figure: MESI models cache-line states as Modified, Exclusive, Shared, and Invalid.
MESI is useful for understanding invalidation and ownership. It should not be used as a direct programming model. Java programs synchronize through locks, volatile, atomic classes, and higher-level concurrency constructs.
The key MESI states are:
| State | Meaning | Why Java engineers care |
|---|---|---|
| Modified | this core has the only dirty copy | later sharing requires coherence work |
| Exclusive | this core has the only clean copy | local writes can often become cheaper |
| Shared | multiple cores may hold the line | writes require invalidation |
| Invalid | local copy cannot be used | a later read must fetch a valid copy |
False sharing follows directly from cache-line granularity. Two unrelated Java fields can occupy the same cache line; if different cores write them frequently, the whole line bounces even though the variables are logically independent.
8.3 MESIF

Figure: MESIF adds a Forward state to reduce duplicated cache-line responses on some architectures.
8.4 MOESI

Figure: MOESI adds an Owned state so a modified cache line can be shared without immediate write-back.
8.5 Store Buffers and Invalidate Queues

Figure: Store buffers can expose writes to other cores later than the issuing core observes its own writes.

Figure: Delayed invalidation processing can make a core temporarily read stale cache-line contents.
These mechanisms explain why volatile and monitor boundaries need real implementation support. They also explain why “it passed a stress test on my laptop” is not a proof.
Store buffers and invalidate queues are especially important for mental models:
| Mechanism | Performance reason | Correctness risk without ordering |
|---|---|---|
| store buffer | lets a core continue before a store is globally visible | another core may observe a flag before observing the data it was meant to publish |
| invalidate queue | lets a core defer processing coherence invalidations | a core may temporarily read a stale cache line |
| speculation | keeps pipelines busy | results must be retired only when legal under the memory model |
| write combining | improves bandwidth for adjacent writes | can obscure simple “one write immediately visible everywhere” intuition |
JMM does not require developers to reason about every queue. It requires developers to use language-level constructs that give the JVM enough information to insert the right constraints.
9. Instruction Reordering and As-If-Serial Semantics
9.1 Layers of Reordering
Reordering can happen at several layers:
- source-to-bytecode compilation;
- bytecode-to-machine-code JIT compilation;
- CPU instruction scheduling;
- store buffering;
- speculative execution;
- cache-coherence timing.
As-if-serial semantics protect the result of a single-threaded program. They do not protect data-racy communication between threads.
9.2 Allowed and Forbidden Reordering
Compilers may reorder independent ordinary operations if no single-threaded result changes and no JMM ordering rule is violated. They must not move operations across volatile, monitor, final-field freeze, or other synchronization boundaries in a way that changes the required memory semantics.
int a = x + 1;
int b = y + 1;If x and y are ordinary independent variables, the compiler has freedom. If a volatile write or monitor unlock sits between the two operations, the freedom is constrained.
9.3 JMM Reordering Table
| Earlier action | Later action | Can reorder freely? | Engineering note |
|---|---|---|---|
| ordinary read | ordinary read | often yes | subject to dependencies and single-thread semantics |
| ordinary write | ordinary write | often yes | unsafe for cross-thread publication without synchronization |
| ordinary write | volatile write | no if it breaks release ordering | volatile write publishes prior ordinary writes |
| volatile read | ordinary read | no if it breaks acquire ordering | reads after acquire must remain after it |
| monitor unlock | later monitor lock on same monitor | no | establishes synchronizes-with |
10. Synchronized and Lock Memory Semantics
10.1 Mutual Exclusion plus Visibility
synchronized does two jobs:
- mutual exclusion: only one thread owns the monitor at a time;
- memory ordering: unlock releases, later lock on the same monitor acquires.
final class GuardedState {
private final Object lock = new Object();
private int value;
void set(int newValue) {
synchronized (lock) {
value = newValue;
}
}
int get() {
synchronized (lock) {
return value;
}
}
}10.2 Lock Boundary
The same monitor object is required. Two different lock objects do not form the monitor rule’s synchronization edge.
final class BrokenLocking {
private final Object writeLock = new Object();
private final Object readLock = new Object();
private int value;
void set(int newValue) {
synchronized (writeLock) {
value = newValue;
}
}
int get() {
synchronized (readLock) {
return value;
}
}
}This code has locking syntax, but it does not establish the intended lock-based happens-before edge.
10.3 Modern Lock Implementation Notes
Implementation details have changed across JDK releases. Biased locking is historical and should not be treated as the default modern tuning path. For current systems, focus on:
- critical-section size;
- lock granularity;
- lock striping only when measurement supports it;
- replacing high-contention counters with
LongAdder; - using concurrent containers correctly;
- JFR lock profiling and allocation profiling.
10.4 ReentrantLock
ReentrantLock has the same kind of memory effect as monitor locking: a successful unlock happens-before a subsequent successful lock on the same lock object.
Use ReentrantLock when you need features such as timed lock acquisition, interruptible lock acquisition, multiple conditions, or explicit fairness settings. Do not use it merely because it looks more advanced.
11. False Sharing and Cache-Line Optimization
11.1 What False Sharing Is
False sharing happens when independent variables used by different threads occupy the same cache line. The variables are logically independent, but the cache-coherence protocol moves the entire line between cores.
final class Counters {
volatile long left;
volatile long right;
}If one thread updates left and another updates right, both fields can still fight over the same cache line.
11.2 Padding
Padding separates hot fields into different cache lines. It can improve throughput in low-level concurrent structures, but it also increases memory footprint and can be JVM-layout-sensitive.
11.3 Contended Annotation
@Contended is the JVM-supported route for padding in selected cases, but it normally requires JVM flags and should be validated with benchmarks. Do not cargo-cult padding into application code.
12. Classic Case Studies
12.1 Double-Checked Locking
Double-checked locking is correct only when the shared reference is volatile or publication is otherwise safely established.
final class LazyService {
private static volatile Service service;
static Service get() {
Service local = service;
if (local == null) {
synchronized (LazyService.class) {
local = service;
if (local == null) {
local = new Service();
service = local;
}
}
}
return local;
}
}12.2 Modern ConcurrentHashMap
Java 7’s segmented-lock design is primarily historical. Java 8 and later use a different design centered around bins, CAS, synchronized bin locking, tree bins, cooperative resize, and control fields such as sizeCtl.
Interview answers should reflect the modern design:
- CAS initializes the table.
- CAS inserts into empty bins.
- Bin-level locking handles non-empty bins.
- Treeification depends on table size.
- resize can be assisted by multiple threads.
mappingCount()is a better high-concurrency estimate thansize().
13. Benchmarking Padding and Contention
13.1 Benchmarking Rules
Concurrency performance should be measured with tools that understand JVM warmup, dead-code elimination, compiler tiers, and blackholes. JMH is the default tool for microbenchmarks.
Bad benchmarking pattern:
long start = System.nanoTime();
runOnce();
System.out.println(System.nanoTime() - start);Better practice:
- use JMH;
- include warmup iterations;
- isolate state with JMH scopes;
- inspect generated code only after a benchmark shows a real bottleneck;
- validate with production telemetry when possible.
13.2 Padding Tradeoff
Padding can reduce coherence traffic, but it can also waste memory and reduce cache locality. Use it for high-frequency shared counters, ring buffers, or runtime primitives. Do not use it for ordinary domain objects.
13.3 Disruptor-Style Layout
The Disruptor pattern popularized cache-line-aware sequencing. The important lesson is not “add dummy fields everywhere”; it is “understand the ownership and update frequency of each field.”
14. JSR-133 Formal Semantics Supplement
14.1 Program Order
Program order defines the order of actions inside one thread during a concrete execution, not merely line numbers in source code.
Let p(a,b) mean that action a precedes action b in program order. In this simplified notation:
SameThread(a,b) means the two actions belong to the same thread. Earlier(a,b) is a short name for “earlier in this thread’s executed action order.” It covers branches, loops, method calls, and inlined code, so it is more precise than “textually earlier.”
14.2 Happens-Before as a Generated Relation
Happens-before is not obtained by putting every synchronization-order edge directly into visibility order. Synchronization order is used to define selected synchronizes-with edges. Happens-before is the smallest transitive relation that contains program order and synchronizes-with.
The generating rules can be written as:
Here, c ranges over actions in the execution and represents the intermediate action used by transitivity.
Equivalently:
14.3 Monitor Rule
For monitor m, unlock action u, and lock action l, an unlock synchronizes-with a later lock on the same monitor:
Equivalently:
14.4 Volatile Rule
For volatile variable v, volatile write w, and volatile read r:
This is not the same as saying every synchronization-order edge becomes happens-before. Only the specified synchronizes-with edges enter the happens-before closure.
14.5 Correctness Guarantee
The DRF guarantee is the bridge from formal semantics to engineering practice. If the program has no data race, the programmer can reason as if actions were interleaved in a sequentially consistent order. That is the practical payoff of paying the synchronization cost.
15. Processor Memory Models
15.1 Classification
Processor memory models differ in how much reordering they allow:
- strongly ordered models allow less reordering;
- weakly ordered models allow more reordering;
- JVMs compensate by using the right barriers or instruction sequences for each target.
15.2 x86 and x86_64
x86 TSO mostly preserves load-load, load-store, and store-store ordering. Store-load behavior is the important exception caused by store buffers. Java volatile and monitor implementation must still respect JMM, even if the hardware is relatively strong.
15.3 ARM64
ARM64 is weaker and therefore makes the cost model more visible. The JVM must insert ordering instructions for cases that x86 may satisfy with ordinary loads, stores, or locked operations.
15.4 Cross-Platform Guidance
Do not write Java code that is only correct on x86. If a pattern relies on hardware accidentally making a write visible soon enough, it is not portable Java. Use Java synchronization constructs and let the JVM map them to the target architecture.
16. Production Diagnosis and Case Studies
16.1 Common Bug Patterns
Common production bugs include:
- unsafely published singleton;
- volatile counter used as if increment were atomic;
HashMapshared without synchronization;- mutable object stored in a final field and then modified without discipline;
- separate locks used for read and write paths;
- cache invalidation message published before data commit;
- optimistic locking implemented without retry limits.
Two diagnostic questions quickly separate JMM bugs from distributed consistency bugs:
| Symptom | Likely local JVM issue | Likely system-level issue |
|---|---|---|
| value is stale inside one process | missing volatile, lock, final-safe publication, or library handoff | stale cache replica or delayed invalidation |
| duplicate ID | non-atomic local counter | missing worker id, sequence, database sequence, or uniqueness constraint |
| lost account update | read-check-write race in process | database update not conditional, no version check, no transaction boundary |
| duplicate side effect | callback executed twice in one process | client retry, MQ redelivery, no idempotency key |
| order-dependent failure | executor reorders tasks | messages are on different partitions or consumers bypass the storage ordering rule |
Start with the smallest scope that explains the bug, but do not stop there. A fix that protects one JVM can still fail after horizontal scaling.
16.2 Order Number Generator
final class BrokenOrderId {
private long next;
long nextId() {
return ++next;
}
}This loses updates under concurrency. Fixes depend on business semantics:
AtomicLongfor a single JVM;- database sequence for cross-instance ordering;
- Snowflake-like ID generator for distributed uniqueness;
- versioned updates when the ID is attached to mutable business state.
A single-instance service can use an AtomicLong when all requirements are local:
final class LocalOrderIdGenerator {
private final AtomicLong next = new AtomicLong();
long nextId() {
return next.incrementAndGet();
}
}This is thread-safe inside one process. It is not globally unique across replicas, because each process has its own heap and its own counter. Once the service is deployed with multiple instances, the ID design must include a shared source of uniqueness.
public final class SnowflakeStyleOrderIdGenerator {
private static final long EPOCH = 1_700_000_000_000L;
private static final long WORKER_BITS = 10L;
private static final long SEQUENCE_BITS = 12L;
private static final long MAX_SEQUENCE = (1L << SEQUENCE_BITS) - 1L;
private final long workerId;
private long lastMillis = -1L;
private long sequence;
public SnowflakeStyleOrderIdGenerator(long workerId) {
if (workerId < 0 || workerId >= (1L << WORKER_BITS)) {
throw new IllegalArgumentException("workerId out of range");
}
this.workerId = workerId;
}
public synchronized long nextId() {
long now = System.currentTimeMillis();
if (now < lastMillis) {
throw new IllegalStateException("clock moved backwards");
}
if (now == lastMillis) {
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0) {
now = waitUntilNextMillis(lastMillis);
}
} else {
sequence = 0;
}
lastMillis = now;
return ((now - EPOCH) << (WORKER_BITS + SEQUENCE_BITS))
| (workerId << SEQUENCE_BITS)
| sequence;
}
private static long waitUntilNextMillis(long lastMillis) {
long now;
do {
now = System.currentTimeMillis();
} while (now <= lastMillis);
return now;
}
}The local synchronized block protects lastMillis and sequence inside one generator object. Global safety still depends on unique workerId assignment, clock discipline, and a database unique constraint on the final order ID. A production review should treat the database uniqueness constraint as the last safety net, not as optional documentation.
16.3 Account Balance Deduction
In a microservice, synchronized protects only one JVM instance. If the service scales to many replicas, the race moves to the database or shared store.
Correct patterns include:
- single SQL conditional update such as “deduct where balance is sufficient”;
- optimistic locking with a version column and bounded retry;
- pessimistic row lock when business constraints require strict serialization;
- idempotency key to survive retries;
- outbox or transaction log for message publication.
Optimistic locking is not a replacement for JMM. It is a distributed concurrency-control mechanism. The two solve different layers.
The broken version usually looks harmless:
@Service
public class BrokenAccountService {
private final AccountRepository accountRepository;
public boolean deduct(long accountId, BigDecimal amount) {
Account account = accountRepository.findById(accountId).orElse(null);
if (account == null) {
return false;
}
if (account.balance().compareTo(amount) < 0) {
return false;
}
account.setBalance(account.balance().subtract(amount));
accountRepository.save(account);
return true;
}
}The race is the split between read, check, and write. Two transactions can read the same balance and both save a derived value. Adding synchronized only serializes calls inside one service instance:
public synchronized boolean deductWithLocalLock(long accountId, BigDecimal amount) {
return doReadCheckWrite(accountId, amount);
}That local lock does not protect the fact source. Another replica, a consumer, or a batch job can still update the same row. The invariant “balance cannot become negative” belongs in the fact source.
For a simple one-row deduction, a conditional update is often the strongest and simplest solution:
public interface AccountRepository extends JpaRepository<Account, Long> {
@Modifying
@Query("""
UPDATE Account a
SET a.balance = a.balance - :amount,
a.version = a.version + 1,
a.updatedAt = :now
WHERE a.id = :accountId
AND a.balance >= :amount
""")
int deductIfEnough(@Param("accountId") long accountId,
@Param("amount") BigDecimal amount,
@Param("now") Instant now);
}The check and the mutation happen in one database update. Concurrent requests may race, but only requests that still satisfy the predicate update a row. The method returns 0 when the account does not exist, the balance is insufficient, or another transaction won the race first. The service can then read the current row and map the result to a business response.
Optimistic locking is useful when the update must read a richer aggregate before writing:
CREATE TABLE account (
id BIGINT PRIMARY KEY,
balance DECIMAL(18, 2) NOT NULL,
version BIGINT NOT NULL DEFAULT 0,
updated_at TIMESTAMP NOT NULL
);
CREATE TABLE account_deduct_log (
id BIGINT PRIMARY KEY,
account_id BIGINT NOT NULL,
request_id VARCHAR(64) NOT NULL,
amount DECIMAL(18, 2) NOT NULL,
status VARCHAR(16) NOT NULL,
result_code VARCHAR(32) NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
UNIQUE (request_id)
);
CREATE TABLE account_outbox (
id BIGINT PRIMARY KEY,
aggregate_id BIGINT NOT NULL,
event_type VARCHAR(64) NOT NULL,
payload TEXT NOT NULL,
status VARCHAR(16) NOT NULL,
created_at TIMESTAMP NOT NULL
);The idempotency log is not an afterthought. It prevents duplicate client retries or message redelivery from executing the same business request twice. A robust transaction first claims the request by inserting a PROCESSING row under a unique constraint:
@Transactional
public DeductResult deductWithOptimisticLock(DeductCommand command) {
DeductClaim claim = deductLogRepository.tryInsertProcessing(
command.requestId(),
command.accountId(),
command.amount());
if (!claim.isNew()) {
return DeductResult.fromExisting(claim.existingLog());
}
Account account = accountRepository.findById(command.accountId()).orElse(null);
if (account == null) {
deductLogRepository.markFailed(command.requestId(), "ACCOUNT_NOT_FOUND");
return DeductResult.accountNotFound(command.requestId());
}
if (account.balance().compareTo(command.amount()) < 0) {
deductLogRepository.markFailed(command.requestId(), "INSUFFICIENT_BALANCE");
return DeductResult.insufficientBalance(command.requestId());
}
int updated = accountRepository.deductByVersion(
account.id(),
command.amount(),
account.version(),
Instant.now());
if (updated == 0) {
deductLogRepository.markConflict(command.requestId());
return DeductResult.retryableConflict(command.requestId());
}
deductLogRepository.markSuccess(command.requestId(), "OK");
outboxRepository.append(AccountDeductedEvent.from(command));
return DeductResult.success(command.requestId());
}The versioned update must include both the expected version and the business invariant:
@Modifying
@Query("""
UPDATE Account a
SET a.balance = a.balance - :amount,
a.version = a.version + 1,
a.updatedAt = :now
WHERE a.id = :accountId
AND a.version = :expectedVersion
AND a.balance >= :amount
""")
int deductByVersion(@Param("accountId") long accountId,
@Param("amount") BigDecimal amount,
@Param("expectedVersion") long expectedVersion,
@Param("now") Instant now);Do not check idempotency with existsByRequestId() followed by an insert. Two duplicate requests can both observe absence. The unique constraint is the serialization point. Different databases expose different syntax for “insert if absent”; the required semantic is one winner per business request ID.
Outbox solves a different failure: the service can commit the deduction and crash before publishing the message. By storing the event in the same transaction, a relay can publish it later. The database transaction covers the balance, deduct log, and outbox row; it does not cover a remote broker or another microservice.
The decision boundary is:
| Scenario | Recommended concurrency control | Why |
|---|---|---|
| local in-memory metric | AtomicLong or LongAdder | fact is local and approximate or process-scoped |
| single-account deduction | conditional SQL update | invariant is one row and can be checked atomically |
| rich aggregate update | version column optimistic lock | read model is needed, conflict can be retried |
| two-account transfer | transaction plus row locks or serializable constraint | invariant spans multiple rows |
| hot inventory item | conditional update plus queueing, token bucket, or sharding | optimistic retries can become a storm |
| cross-service workflow | idempotency plus outbox or saga | no single local transaction covers all services |
Optimistic locking also needs a retry policy. Unlimited retry is a production bug, not resilience.
public DeductResult deductWithPolicy(DeductCommand command) {
return idempotencyGuard.execute(command.requestId(), () -> {
String resourceKey = "account:" + command.accountId();
if (!rateLimiter.tryAcquire(resourceKey)) {
return DeductResult.rejected("too_many_requests");
}
return bulkhead.execute(resourceKey, () ->
retryWithJitter.execute(
attempt -> deductWithOptimisticLock(command),
result -> result.isRetryableConflict()));
});
}The policy is intentionally layered. JMM makes idempotencyGuard, rateLimiter, bulkhead, and retry state thread-safe inside the process. The database unique constraint and conditional update protect the business fact across all replicas.
Operationally, monitor these signals:
| Metric | Meaning | Bad signal |
|---|---|---|
optimistic_lock_conflict_total | version or conditional-update conflict count | sudden growth means a hot row or retry storm |
deduct_retry_attempts | attempts per business request | high P95/P99 means optimistic lock is no longer cheap |
idempotency_hit_total | repeated request keys | upstream timeout, client retry, or MQ redelivery spike |
outbox_lag_seconds | delay between outbox insert and publish | relay is stuck or broker is slow |
deduct_processing_stuck_total | logs stuck in PROCESSING | exception path or compensator is incomplete |
Business failures and technical conflicts must be separated. Insufficient balance, frozen account, and invalid amount are not retryable. Version mismatch, deadlock retry exception, and short lock timeout may be retryable with a small attempt limit and jitter.
16.4 Cache Breakdown
Cache stampedes and cache breakdowns are not fixed by volatile alone. The shared state is not just a Java field; it is the database load created by many replicas missing the same key at the same time.
public final class LocalCacheLoader<K, V> {
private final ConcurrentHashMap<K, CompletableFuture<V>> inflight = new ConcurrentHashMap<>();
public CompletableFuture<V> loadOnce(K key, Function<K, V> loader) {
return inflight.computeIfAbsent(key, ignored ->
CompletableFuture.supplyAsync(() -> loader.apply(key))
.whenComplete((value, error) -> inflight.remove(key)));
}
}The local coalescing map prevents duplicate rebuilds inside one process. In a cluster, you still need expiry jitter, request shedding, refresh-ahead, distributed coordination for the hottest keys, or a cache product that supports single-flight behavior across nodes.
| Technique | Scope | Useful when | Boundary |
|---|---|---|---|
| local single-flight | one JVM | many threads miss the same key | does not coordinate replicas |
| distributed lock | cluster entry control | rebuild is expensive and rare | lock expiry and owner death must be handled |
| refresh-ahead | cache service | data is predictable and hot | may serve slightly stale data |
| negative cache | application/cache | missing keys are repeatedly queried | TTL must be short enough for creation flows |
| jittered TTL | cache fleet | many keys expire together | does not help one extremely hot key alone |
16.5 Message Ordering
Message ordering is normally scoped to a key or partition. If state updates depend on order, put the same aggregate key on the same partition or enforce ordering at the consumer’s storage boundary.
public void publishOrderEvent(OrderEvent event) {
kafkaTemplate.send("order-events", event.orderId().toString(), event);
}Using the aggregate ID as the key keeps events for the same order on the same partition, assuming the producer and topic configuration are stable. The consumer should still make the state transition idempotent and monotonic:
@Transactional
public void apply(OrderEvent event) {
int updated = orderRepository.transitionIfVersionMatches(
event.orderId(),
event.expectedVersion(),
event.nextStatus(),
event.eventId());
if (updated == 0) {
duplicateOrOutOfOrderEventRepository.record(event.eventId());
}
}Thread pools can preserve partition ordering only if they do not scatter records from the same partition into unrelated workers. When a consumer hands each record to a generic executor, it may destroy the broker’s ordering guarantee.
16.6 ThreadLocal Leaks
Thread pools reuse threads. A ThreadLocal that is not cleared can retain request state and cause memory leaks or data bleed between requests.
try {
context.set(requestContext);
handle(request);
} finally {
context.remove();
}A servlet or reactive boundary should centralize cleanup:
public final class RequestContextFilter implements Filter {
@Override
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain) throws IOException, ServletException {
try {
RequestContextHolder.set(extract(request));
chain.doFilter(request, response);
} finally {
RequestContextHolder.clear();
SecurityContextHolder.clearContext();
MDC.clear();
}
}
}InheritableThreadLocal is not a general fix for executors. Thread pools create worker threads once and then reuse them; inherited values can be stale or surprising. For tracing, prefer framework-supported context propagation. For business state, pass explicit parameters unless a framework boundary requires contextual storage.
16.7 Diagnostic Toolkit
Use:
- JFR for lock contention, allocation pressure, and thread state;
jstackfor deadlocks and blocked threads;- JMH for microbenchmarks;
- JCStress for concurrency litmus tests;
- logs with request IDs and idempotency keys for distributed races;
- database deadlock reports and slow query logs for storage-level contention.
A practical incident workflow:
- Reconstruct the invariant that was violated.
- Identify every writer path, including jobs, consumers, manual tools, and compensators.
- Determine whether the violated fact is heap-local or stored externally.
- For heap-local races, inspect missing volatile, lock, atomic, safe publication, or library handoff.
- For external races, inspect transaction boundaries, conditional updates, unique constraints, message keys, idempotency, and retries.
- Add a regression test at the right layer: JCStress for local memory-model behavior, integration tests for database races, and chaos or replay tests for message redelivery.
JCStress is useful for local memory-model litmus tests:
@JCStressTest
@Outcome(id = "1, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 0", expect = Expect.ACCEPTABLE)
@Outcome(id = "1, 0", expect = Expect.FORBIDDEN)
@State
public class PublicationOrderingTest {
int data;
volatile boolean ready;
@Actor
public void writer() {
data = 1;
ready = true;
}
@Actor
public void reader(II_Result result) {
result.r1 = ready ? 1 : 0;
result.r2 = data;
}
}The forbidden outcome says the reader observed the volatile flag but did not observe the ordinary write that happened before the volatile write. If such an outcome appears, either the test is wrong or the runtime violates the JMM contract.
17. HotSpot VM Implementation Reading Guide
17.1 OrderAccess
HotSpot abstracts memory-ordering operations behind platform-specific layers. Conceptually:
// Conceptual shape only, not a quoted OpenJDK source excerpt.
inline void acquire();
inline void release();
inline void fence();
inline void loadload();
inline void storestore();
inline void loadstore();
inline void storeload();The names are useful for learning, but real implementations change across platforms and JDK versions.
Read HotSpot implementation code with two boundaries in mind. First, the Java Language Specification defines the portable semantics. Second, HotSpot chooses a platform-specific implementation that can change between JDK versions, CPU targets, and compiler tiers. Source reading is therefore evidence for “how this build implements the contract”, not a substitute for the contract itself.
Useful places to inspect in an OpenJDK tree include the platform order-access layer, macro assembler implementations, C2 barrier nodes, template interpreter access paths, object monitor code, and VarHandle access-mode plumbing. Names move over time, so treat this as a reading map rather than a stable API.
| Area | What to look for | Question to ask |
|---|---|---|
| order access abstraction | acquire, release, full fence, load/store barriers | which semantic boundary is being represented? |
| platform macro assembler | locked operations, DMB, acquire/release forms | how does this CPU satisfy the boundary? |
| template interpreter | bytecode-level volatile and monitor handling | what happens before JIT compilation? |
| C1/C2 compiler | memory nodes and barrier elimination | which barriers are proven redundant? |
| object monitor runtime | fast path, inflation, enter, exit | where does mutual exclusion meet memory ordering? |
| VarHandle implementation | plain, opaque, acquire, release, volatile modes | how strong is each access mode? |
17.2 x86 Mapping
On x86, ordinary loads and stores already provide many ordering properties. Stronger boundaries can use locked instructions or fences. The exact sequence is an implementation detail, so performance claims must be tied to a JDK version, CPU, and benchmark.
When reading x86 output, avoid two common mistakes:
- “No explicit fence” does not mean “no memory semantics”; a locked instruction, TSO property, or compiler constraint may be carrying the requirement.
- “A fence appeared” does not mean every volatile access always has that fence; the JIT may use different sequences for different contexts.
The useful artifact is a benchmark-plus-disassembly note:
JDK: 26
CPU: x86_64, model and microcode recorded
Benchmark: read-mostly volatile snapshot, 99:1 read/write ratio
Observation: volatile read path does not emit an explicit full fence in this build
Conclusion: valid only for this benchmark shape and this runtime17.3 ARM Mapping
On ARM, explicit barriers such as DMB variants are more common. This makes the cost of release/acquire and full barriers easier to see in generated code.
On ARM-like targets, the reading question changes from “where is the fence?” to “which access strength was selected?” A volatile read may map to an acquire-style load or a barrier-backed sequence. A volatile write may map to release-style ordering and additional constraints when the Java semantics require them. The Java rule is the same; the machine path is different.
17.4 Volatile Template Generation
The template or compiler-generated code for volatile access is responsible for preserving JMM semantics. Engineers should understand the conceptual path:
volatile_write:
order prior ordinary writes before publication
perform volatile store
maintain required store-load boundary
volatile_read:
perform volatile load
order later ordinary reads after acquisitionThis is conceptual pseudocode, not an OpenJDK source excerpt.
The generated path is allowed to differ as long as the observable Java semantics hold. That is why source comments, generated assembly, and benchmarks must be interpreted together. A correct performance investigation normally includes:
- a small source example that isolates the construct;
- a JMH benchmark that prevents dead-code elimination;
- JIT compilation logs or disassembly for the relevant method;
- a comparison across at least two contention levels;
- a conclusion phrased in terms of the tested JDK and CPU.
17.5 Monitor Implementation
Modern monitor implementation includes fast paths, inflated monitors, object headers, and runtime support. The memory rule remains stable: unlock releases, later lock on the same monitor acquires.
The implementation is optimized heavily:
| Path | Typical situation | Memory-model view |
|---|---|---|
| fast uncontended path | one thread enters and exits quickly | still an acquire/release boundary |
| inflated monitor | contention or wait/notify involvement | runtime object tracks ownership and waiters |
wait() | thread releases monitor and parks | reacquisition after wakeup re-enters the monitor protocol |
notify() / notifyAll() | moves waiters toward reacquisition | notification alone is not ownership transfer |
The happens-before rule is tied to unlock and subsequent lock on the same monitor. notify() affects scheduling of waiters, but the protected data is safely observed when the waiting thread reacquires the monitor.
17.6 CAS Memory Semantics
Compare-and-swap operations used by atomic classes provide atomicity for one location and include ordering semantics defined by their Java APIs. Use VarHandle modes when you need precise access strength, but document the reasoning.
A CAS loop is still a protocol:
public final class VersionedReference<T> {
private final AtomicReference<State<T>> state =
new AtomicReference<>(new State<>(0, null));
public boolean update(long expectedVersion, T nextValue) {
State<T> current = state.get();
if (current.version() != expectedVersion) {
return false;
}
State<T> next = new State<>(expectedVersion + 1, nextValue);
return state.compareAndSet(current, next);
}
}This protects one in-memory reference. It does not protect a database row, a remote cache entry, or a Kafka partition. It also does not make a multi-step object graph update atomic unless the entire state is represented by the one swapped reference.
17.7 Final Field Barrier
Final-field safe construction is implemented through rules around constructor completion and object publication. The programmer-facing rule is still simpler: do not let this escape during construction.
Unsafe construction patterns include registering listeners, starting threads, submitting tasks, or publishing the object to a static collection from inside the constructor:
public final class EscapingService {
private final int port;
public EscapingService(EventBus bus) {
bus.register(this);
this.port = 8080;
}
}Another thread may call back into the object before construction has completed. Build the object first, then publish it from a factory or lifecycle method.
17.8 JIT Barrier Optimization
The JIT may remove redundant barriers when it proves the resulting code still satisfies JMM. Do not infer that a source-level synchronization construct is useless because one benchmark emits fewer instructions in one build.
Barrier optimization is correctness-preserving only when the compiler has a proof. Engineers should not manually remove synchronization because “the JIT would remove it anyway.” If the synchronization is redundant, express the ownership model more clearly, add tests, and then let the compiler optimize.
18. Performance Practices and Checklists
18.1 Core Principles
Use the weakest construct that still expresses the correct ownership and ordering:
- immutable object for read-only shared state;
- confinement for single-owner mutable state;
- volatile for one-field publication or stop flags;
- atomic classes for single-variable atomic updates;
- locks for invariants across multiple fields;
- concurrent collections for shared containers;
- database or external coordination for multi-instance races.
The word “weakest” means semantically weakest, not visually shortest. A plain field is weaker than volatile but may be wrong. A volatile field is weaker than a lock but may be wrong for multi-field invariants. A database conditional update is stronger than a JVM lock at the system boundary because it protects the shared fact.
| Shared-state shape | Recommended primitive | Review question |
|---|---|---|
| immutable data | final fields plus safe publication | can the object graph mutate after publication? |
| one-writer stop flag | volatile | is the operation only a single state publication? |
| single numeric counter | AtomicLong or LongAdder | do readers require exact instantaneous value? |
| compound invariant | lock or immutable aggregate swap | are all fields read and written under one rule? |
| shared collection | concurrent collection or external lock | are iteration and compound operations safe? |
| external business fact | database constraint, transaction, or external CAS | does every writer go through the same fact source? |
Measure after correctness is established. The usual sequence is correctness proof, stress test or JCStress where appropriate, JMH for micro hot spots, JFR or production telemetry for real workload evidence, then a targeted optimization.
18.2 Checklist
Before approving concurrent Java code, ask:
- Which shared state can be written by more than one thread?
- Which edge publishes the write to the reader?
- Is the same lock object used on both sides?
- Is volatile being mistaken for atomic increment?
- Can
thisescape during construction? - Does a final reference hide a mutable object graph?
- Does the design still work with multiple service instances?
- Is performance evidence based on JMH, JFR, or production telemetry?
For production microservices, add these review gates:
| Gate | Required evidence |
|---|---|
| fact-source boundary | database, queue, cache, or external store that owns the fact is named |
| idempotency | request ID or event ID has a uniqueness guarantee |
| retry policy | retryable and non-retryable failures are separated |
| conflict metric | lock wait, version conflict, duplicate request, or outbox lag is observable |
| fallback behavior | timeout, circuit breaker, or rejection path is defined |
| scaling assumption | behavior with two or more service replicas is explicitly described |
18.3 Common Misconceptions
Misconception: “Volatile flushes everything to main memory.”
Better: volatile establishes Java-level ordering and visibility for the volatile variable and related ordinary accesses through happens-before.
Misconception: “Synchronized is always slow.”
Better: uncontended locking can be cheap; contention, blocking, and lock granularity determine cost.
Misconception: “Final means immutable.”
Better: final fixes the reference or primitive field after construction. Object graph immutability requires more design.
Misconception: “It works on x86, so it is safe.”
Better: JMM correctness must hold across JVMs and architectures.
Misconception: “CAS solves distributed concurrency.”
Better: Java CAS solves one memory location inside one JVM. Distributed concurrency needs a shared fact source, such as a database conditional update, a unique constraint, a compare-and-set operation in a linearizable store, or a partitioned log discipline.
Misconception: “Optimistic locking is always faster.”
Better: optimistic locking is fast under low conflict and controlled retry. Under a hot key, it can become a retry amplifier. Use queueing, sharding, pessimistic locking, or admission control when conflicts dominate useful work.
Misconception: “A final field makes the object immutable.”
Better: final stabilizes the field assignment and helps safe construction. Deep immutability requires immutable referenced objects, defensive copies, and no backdoor mutation.
18.4 Learning Path
Recommended progression:
- Learn actions, data races, happens-before, and safe publication.
- Learn volatile, final, synchronized, atomics, and concurrent collections.
- Learn cache lines, barriers, and processor memory models as explanations, not as the primary programming interface.
- Use JFR, JMH, and JCStress to validate assumptions.
- Extend the model to distributed concurrency with database and messaging guarantees.
For teams, turn the learning path into engineering practice:
- Require every concurrency-sensitive design to name its publication edge.
- Ban “probably visible” and “works on my machine” from design reviews.
- Prefer library-level concurrency utilities before handwritten low-level protocols.
- Keep local synchronization and distributed consistency in separate sections of design docs.
- Add incident metrics before the first large-scale traffic event, not after the first outage.
19. Summary and Outlook
19.1 Core Takeaways
JMM is the reason Java concurrency can be portable. It defines a contract above hardware and compiler behavior. The central workflow is:
- identify shared mutable state;
- identify writes and reads;
- establish a happens-before edge;
- avoid data races;
- verify performance with evidence rather than folklore.
19.2 Evolution
The model introduced by JSR-133 remains the foundation. Later APIs such as VarHandle give more explicit access modes, but they do not remove the need to reason about publication, ordering, and ownership.
19.3 Advice for Developers
For application code, prefer clarity over cleverness:
- immutable values and clear ownership first;
- library-level concurrent components second;
- low-level memory-ordering tricks last;
- distributed consistency handled at the storage and messaging boundary.
If a design cannot clearly name the happens-before edge, it should not pass a production review.
References
- Java Language Specification, Chapter 17: Threads and Locks.
- JSR-133: Java Memory Model and Thread Specification.
- OpenJDK JDK Project: https://openjdk.org/projects/jdk/
- Doug Lea, JSR-133 Cookbook for Compiler Writers.
- JCStress: OpenJDK concurrency stress tests.
Series context
You are reading: Java Core Technologies Deep Dive
This is article 1 of 8. Reading progress is stored only in this browser so the full series page can resume from the right entry.
Series Path
Current series chapters
Chapter clicks store reading progress only in this browser so the series page can resume from the right entry.
- Java Memory Model Deep Dive: From Happens-Before to Safe Publication A production-grade deep dive into JMM, happens-before, volatile, final fields, optimistic locking, memory barriers, cache coherence, lock semantics, HotSpot implementation, and concurrency diagnostics.
- Modern Java Garbage Collection: Production Judgment, Evidence Collection, and Tuning Paths Use symptoms, GC logs, JFR, container memory, and rollback discipline to choose and tune G1, ZGC, Shenandoah, Parallel GC, and Serial GC without cargo-cult flags.
- Concurrency Governance with Virtual Threads in Production Systems Understand throughput, blocking, resource pools, downstream protection, pinning, structured concurrency, observability, and migration boundaries for Project Loom.
- Valhalla and Panama: Java's Future Memory and Foreign-Interface Model Separate delivered FFM API capabilities from evolving Valhalla value-type work, and reason about object layout, data locality, native interop, safety boundaries, and migration governance.
- Java Cloud-Native Production Guide: Runtime Images, Kubernetes, Native Image, Serverless, Supply Chain, and Rollback A production-oriented Java cloud-native guide covering runtime selection, container resources, Kubernetes contracts, Native Image boundaries, Serverless, supply chain evidence, diagnostics, governance, and rollback.
- Spring AI and LangChain4j: Enterprise Java AI Applications and AI Agent Architecture A production-grade guide to Spring AI, LangChain4j, RAG, tool calling, memory, governance, observability, reliability, security, and enterprise AI operating boundaries.
- JIT and AOT: From Symptoms to Diagnosis to Optimization Decisions A production decision guide for HotSpot, Graal, Native Image, PGO, and JVM diagnostics.
- Java Ecosystem Outlook: JDK 25 LTS, JDK 26 GA, and JDK 27 EA An enterprise architecture view of Java's next decade: version strategy, roadmap status, ecosystem boundaries, cloud-native operations, AI governance, and performance evolution.
Reading path
Continue along this topic path
Follow the recommended order for Java instead of jumping through random articles in the same topic.
Next step
Go deeper into this topic
If this article is useful, continue from the topic page or subscribe to follow later updates.
Loading comments...
Comments and discussion
Sign in with GitHub to join the discussion. Comments are synced to GitHub Discussions