Article
Java 内存模型深度解析:从 happens-before 到安全发布
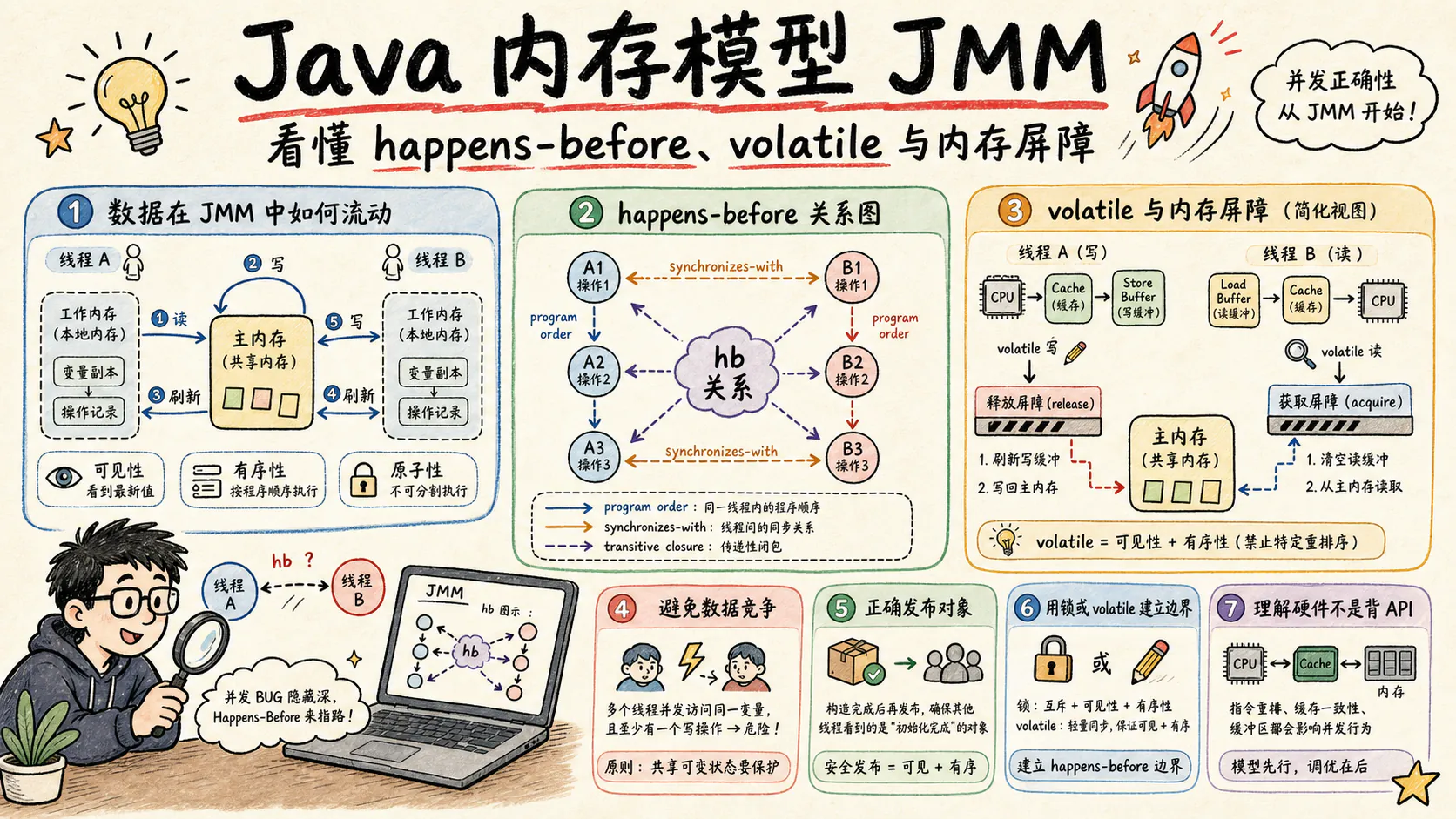
理解 JMM、volatile、final 字段、安全发布、乐观锁、锁语义和现代 ConcurrentHashMap 的工程边界。
Java内存模型深度解析:从 happens-before 到并发安全
文章导航
- 本文适用于:Java高级工程师、架构师、JVM研究者
- 前置知识:Java并发基础、操作系统原理、计算机组成原理
- 阅读收益:完整理解JMM规范、掌握并发Bug根因分析能力、具备JVM调优理论基础
摘要
Java内存模型(Java Memory Model, JMM)是理解Java并发编程的核心理论基础,也是多线程程序正确性的根本保障。本文从JSR-133规范出发,系统剖析happens-before关系的数学定义、volatile语义的形式化描述、内存屏障的硬件实现机制,以及final字段的安全发布保证。通过深入分析HotSpot VM源码实现、对比不同处理器架构的内存模型差异、剖析生产环境中的典型并发Bug案例,为读者构建完整的JMM知识体系,并提供可落地的并发编程最佳实践。
关键词: Java内存模型, JMM, happens-before, volatile, 内存屏障, 指令重排序, JSR-133, 缓存一致性, 可见性, 原子性, final语义, 伪共享, StoreLoad, MESI协议, 安全发布
核验与阅读口径:本文核验日期为 2026-05-14。版本基线为 JDK 25 GA(多数发行商 LTS)、JDK 26 RC/EA 与 JDK 27 EA;JDK 26 的发布判断以
jdk.java.net和发行商下载页为准。文中的 HotSpot 片段用于解释机制,未标注“真实源码摘录”的代码均按概念伪码理解;生产调优必须以当前 JDK 的PrintFlagsFinal、JFR、GC/JIT 日志和压测结果为准。
目录
- 引言:为什么需要内存模型
- JSR-133内存模型规范详解
- happens-before 关系的形式化定义与推导
- 乐观锁与微服务并发治理
- volatile 的语义与实现机制深度解析
- final 字段的安全发布机制
- 内存屏障与硬件实现
- 缓存一致性协议
- 指令重排序与 as-if-serial 语义
- synchronized 与锁的内存语义
- 伪共享与缓存行优化
- 实际案例分析
- 伪共享的基准与填充实践
- JSR-133 形式化语义补充
- 不同处理器架构的内存模型对比
- 生产环境并发问题诊断与案例分析
- HotSpot VM源码深度解读
- 性能优化与最佳实践
- 总结与展望
1. 引言:为什么需要内存模型
1.1 多核时代的内存一致性挑战
现代计算机系统采用多级存储层次结构(Memory Hierarchy),从寄存器、L1/L2/L3缓存到主内存,每一级都存在容量与速度的权衡。在单核时代,这种层次结构对程序员是透明的;但在多核处理器架构下,每个核心拥有独立的缓存层次,这就引入了缓存一致性(Cache Coherence)问题,使得并发编程变得异常复杂。
现代CPU缓存层次结构:
 图1:现代多核CPU缓存架构(Register → L1 → L2 → L3 → Main Memory)
图1:现代多核CPU缓存架构(Register → L1 → L2 → L3 → Main Memory)
缓存一致性问题示例:
考虑以下代码片段,展示缓存一致性带来的可见性问题:
public class CacheCoherenceExample {
// 共享变量存储在主内存中
private static int sharedVar = 0;
private static volatile boolean flag = false;
public static void main(String[] args) throws InterruptedException {
// Thread A 运行在 Core 0
Thread threadA = new Thread(() -> {
// 将sharedVar加载到Core 0的缓存
sharedVar = 1; // (1) Store操作
flag = true; // (2) Store操作
});
// Thread B 运行在 Core 1
Thread threadB = new Thread(() -> {
// 从Core 1的缓存读取flag
while (!flag) { // (3) Load操作
// 自旋等待,消耗CPU周期
Thread.onSpinWait();
}
// 从Core 1的缓存读取sharedVar
System.out.println("sharedVar = " + sharedVar); // (4) Load操作
// 可能输出 0(过时的值)
});
threadB.start();
threadA.start();
threadA.join();
threadB.join();
}
}问题分析:
在无内存模型约束的情况下,存在多种可能的执行结果:
- 结果1:Thread B可能永远看不到flag的变化((2)对Thread B不可见)
- 结果2:Thread B可能看到flag为true但sharedVar仍为0((1)的重排序)
- 结果3:Thread B看到sharedVar为1(正确结果)
这种不确定性源于硬件层面的乱序执行、编译器优化以及缓存一致性协议的延迟传播。
缓存一致性协议(MESI):
现代处理器使用MESI协议维护缓存一致性:
- M(Modified):缓存行被修改,与主内存不一致
- E(Exclusive):缓存行独占,与主内存一致
- S(Shared):缓存行被多个核心共享,与主内存一致
- I(Invalid):缓存行无效,需要重新加载
当Core 0修改sharedVar时:
- Core 0发送Invalid消息给其他核心
- 其他核心将对应缓存行标记为Invalid
- Core 0获得独占访问权,修改缓存行
- 修改后,其他核心需要重新从主内存加载
Store Buffer 与 Load Buffer:
为了减少缓存一致性协议的延迟,处理器引入Store Buffer和Load Buffer:

图:Store Buffer 通过 FIFO 队列异步刷新到 L1 Cache,可能引发内存可见性问题
这种设计虽然提升了性能,但也带来了内存可见性问题。
1.2 从线程视角理解 JMM:工作内存、主内存与竞态
很多人第一次学习 JMM 时,会把“主内存”和“工作内存”理解成 Java 堆里真的存在两份对象:一份在主内存,一份完整复制到每个线程。这种理解不准确。JMM 的“工作内存”是规范层面的抽象,用来描述线程读写共享变量时可能经过的本地工作集:寄存器、CPU Cache、Store Buffer、Invalidate Queue、编译器临时值和运行时优化都可能让一个线程暂时看到与其他线程不同的值。

图:JMM 用工作内存抽象解释线程对共享变量的本地观察;它不是堆对象的完整副本,而是线程访问共享状态时经过的本地读写路径。
从 Java 代码看,两个线程访问的是同一个堆对象;从执行路径看,每个线程可能先在自己的执行上下文里读取、缓存、修改,再在某个时刻把写入发布到其他线程可见的层次。JMM 要解决的不是“对象到底复制了几份”,而是回答三个问题:
- 一个线程写入共享变量后,另一个线程什么时候必须看见。
- 一个线程内的多个读写操作,编译器和处理器允许怎样重排序。
- 如果两个线程同时读写同一变量,且没有同步关系,程序还能不能依赖某个结果。
以最常见的 count++ 为例,它在语义上不是一个单独动作,而是“读当前值、加一、写回”三个步骤:
final class Counter {
private int count;
void increment() {
count++;
}
int get() {
return count;
}
}如果 Thread A 和 Thread B 同时执行 increment(),两者都可能先读到 count = 0,然后分别计算出 1,最后都写回 1。从单线程视角看每一步都正确,从多线程视角看一次更新丢失了。这就是典型的竞态条件:结果取决于线程交错顺序,而程序没有用同步机制约束这种交错。
这也是“为什么有些对象不是线程安全的”的根因。一个对象是否线程安全,不取决于它是不是“放在堆上”,而取决于它暴露出来的状态是否可能被多个线程同时访问,以及这些访问之间是否有清晰的 happens-before 关系。局部变量通常天然线程私有;不可变对象通常可以安全共享;但可变对象一旦被多个线程共享,就需要通过锁、volatile、原子类、并发集合、线程封闭或不可变设计来建立边界。
常见对象可以按以下方式判断:
| 对象类型 | 线程安全判断 | 典型例子 |
|---|---|---|
| 方法内局部变量 | 每个线程有自己的栈帧,通常线程安全 | 局部 int、局部 StringBuilder |
| 不可变对象 | 构造后状态不变,正确发布后可安全共享 | String、LocalDateTime、自定义 immutable DTO |
| 共享可变对象 | 多线程读写时需要同步或并发容器 | 普通 HashMap、普通 POJO 字段 |
| 内部带同步的对象 | 取决于同步边界是否覆盖完整复合操作 | ConcurrentHashMap、AtomicLong |
因此,JMM 的学习入口应该先从线程视角建立这条链路:线程不是直接以全局一致的方式读写共享状态,而是通过本地执行上下文与主内存中的共享变量交互;只有当程序使用 JMM 定义的同步动作建立 happens-before 关系时,另一个线程才获得语言规范层面的可见性和有序性保证。
1.3 JMM的设计目标与约束
Java内存模型由JSR-133专家组制定,其核心目标包括:
目标1:顺序一致性保证(Sequential Consistency for Data-Race-Free Programs)
数据竞争自由(Data-Race-Free)的程序应当表现出顺序一致性,即程序的执行结果与按照某种全局顺序执行的结果一致。
定义 1.1(数据竞争):
当两个线程访问同一内存位置,至少有一个是写操作,且没有同步机制协调这两个访问时,发生数据竞争。
目标2:安全性保证(Safety Guarantees)
确保程序的类型安全、内存安全等基础属性,防止以下问题:
- 悬垂指针(Dangling Pointers)
- 内存泄漏(Memory Leaks)
- 未初始化读取(Uninitialized Reads)
目标3:性能优化空间(Performance Optimization)
允许编译器和处理器在不影响正确性的前提下进行优化:
- 指令重排序(Instruction Reordering)
- 寄存器分配优化
- 循环优化(Loop Optimizations)
目标4:平台无关性(Platform Independence)
抽象底层硬件差异(x86、ARM、POWER等),为Java程序员提供统一的编程模型。
JMM的设计约束:
 图2:JMM在顺序一致性与性能优化之间的平衡点
图2:JMM在顺序一致性与性能优化之间的平衡点
1.4 形式化基础与数学模型
JMM建立在操作语义(Operational Semantics)和公理化语义(Axiomatic Semantics)之上。
核心概念的形式化定义:
定义 1.2(操作 Actions):
线程间交互的原子单位,包括:
- 读操作(Read):从内存读取变量值
- 写操作(Write):向内存写入变量值
- 同步操作(Synchronization):加锁、解锁、volatile读写
- 外部操作(External):与外部世界交互(I/O等)
定义 1.3(同步操作 Synchronization Actions):
具有happens-before语义的特殊操作,包括:
- volatile变量的读写
- synchronized块的进入和退出
- Thread.start() 和 Thread.join()
- Object.wait() 和 Object.notify()
定义 1.4(执行轨迹 Execution Trace):
程序执行过程中所有操作的偏序关系,记作 (E, →),其中E是操作集合,→是偏序关系。
定义 1.5(happens-before 关系):
定义操作间的可见性约束,若 ,则操作A的结果对操作B可见。
形式化表示:
happens-before关系是一个严格偏序(Strict Partial Order),满足:
- 传递性:若 且 ,则
- 非自反性:不存在
- 非对称性:若 ,则不存在
2. JSR-133内存模型规范详解
JSR-133(Java Memory Model and Thread Specification Revision)是Java内存模型的正式规范,于2004年发布,是Java 5(JDK 1.5)的重要组成部分。它彻底重写了Java的内存模型,解决了旧内存模型存在的严重问题,为Java并发编程奠定了坚实的理论基础。
2.1 JSR-133的历史背景与制定原因
Java内存模型演进时间线:

图:Java内存模型从 JDK 1.0 到 JDK 9 的演进历程,JSR-133 (2004) 是关键转折点
旧内存模型的核心问题:
问题1:双重检查锁定(DCL)失效
在JDK 5之前,以下广泛使用的单例模式实际上是错误的:
// JDK 1.4时代的问题代码(广为流传的错误实现)
public class BrokenSingleton {
private static BrokenSingleton instance; // 非volatile!
public static BrokenSingleton getInstance() {
if (instance == null) { // (1) 第一次检查
synchronized (BrokenSingleton.class) {
if (instance == null) { // (2) 第二次检查
instance = new BrokenSingleton(); // (3) 对象创建
}
}
}
return instance; // (4) 返回引用
}
}问题分析:
对象创建的字节码分解(javap -c):
0: new #2 // class BrokenSingleton
3: dup
4: invokespecial #3 // Method "<init>":()V ← 初始化
7: putstatic #4 // Field instance ← 赋值在旧JMM下,步骤4(初始化)和步骤7(赋值)可能被重排序。Thread A 可能先分配内存并把尚未完成初始化的引用赋给 instance;Thread B 随后读到这个非空引用,并开始读取对象字段;Thread A 的构造函数写入则在之后才完成。
这导致其他线程可能看到”半初始化”的对象,是最隐蔽的并发Bug之一。
问题2:volatile语义不完整
旧JMM对volatile的定义存在严重缺陷:
- volatile写不能保证对其他线程立即可见
- volatile不提供任何排序保证
- volatile与普通变量之间的交互没有明确定义
public class BrokenVolatile {
private int x = 0;
private volatile boolean flag = false;
public void writer() {
x = 42; // (1) 普通写
flag = true; // (2) volatile写
}
public void reader() {
if (flag) { // (3) volatile读
// JDK 1.4: 可能看到x=0!
System.out.println(x);
}
}
}在旧JMM中,(1)和(2)可能被重排序,导致reader线程看到flag为true但x仍为0。
问题3:final字段的安全发布
public class UnsafeFinal {
final int x;
public UnsafeFinal() {
x = 42;
// 旧JMM: 构造函数完成后,final字段的写入
// 不能保证对所有线程可见
}
}问题4:String的不变性保证
String的不可变性(immutability)依赖于内部final字段的正确语义,旧JMM无法保证这一点,可能导致严重的安全问题。
2.2 JSR-133专家组与制定过程
专家组组成(2001-2004):
| 专家 | 机构 | 贡献领域 |
|---|---|---|
| Bill Pugh | 马里兰大学 | 首席架构师,DCL问题发现者 |
| Jeremy Manson | 马里兰大学 | happens-before形式化定义 |
| Sarita Adve | UIUC | 形式化验证,C++内存模型经验 |
| Doug Lea | SUN/IBM | java.util.concurrent作者 |
| William Scherer | IBM | 形式化规范编写 |
| David Holmes | SUN | HotSpot VM实现 |
制定过程的关键决策:
决策1:采用happens-before模型
JSR-133选择happens-before作为核心抽象,而非顺序一致性(Sequential Consistency):

图:顺序一致性与 happens-before 模型的权衡对比,JSR-133 选择后者以平衡性能与正确性
决策2:定义数据竞争自由(Data-Race-Free)保证

图:DRF 保证的核心逻辑——数据竞争自由的程序自动获得顺序一致性语义
2.3 JSR-133核心改进点详解
改进点1:volatile的完整语义
新JMM为volatile提供了严格的happens-before保证:
// JSR-133后的正确实现
public class FixedVolatile {
private int x = 0;
private volatile boolean flag = false;
public void writer() {
x = 42; // (1)
flag = true; // (2) volatile写
}
public void reader() {
if (flag) { // (3) volatile读
// JSR-133保证:这里必然看到x=42
System.out.println(x); // (4)
}
}
}这段代码的可见性链条是:
形式化保证:
这里说的是 volatile 规则直接建立的 happens-before 边,而不是所有可能的间接 hb 路径。volatile 写 A 直接 happens-before volatile 读 B,需要同时满足:
- A 是对某个 volatile 变量
v的写,B 是对同一个v的读 - A 在同步顺序中先于 B,因此 A synchronizes-with B
- 这个“先于”来自 JMM 的同步顺序,不是依赖墙钟时间或线程调度先后
改进点2:final字段的安全发布
public class SafeFinal {
final int x;
int y; // 普通字段
public SafeFinal() {
x = 42; // (1)
y = 100; // (2)
}
}
// 使用
SafeFinal obj = new SafeFinal(); // (3)
// 在JSR-133下:
// - 其他线程必然看到x=42(final保证)
// - 但可能看到y=0或y=100(普通字段,无保证)final字段的内存语义:
- 构造函数中对final字段的写入
- happens-before 后续每个线程对该对象引用的首次读取
- 前提:this引用不能在构造函数中逸出
改进点3:synchronized的增强
新JMM强化了synchronized的happens-before保证:
// Thread A
synchronized (monitor) {
x = 1; // A
} // B: 解锁
// Thread B
synchronized (monitor) {
// C: 加锁
int r = x; // D
}JSR-133 对这个例子的保证是:
因此 D 必然看到 A 写入的值。
改进点4:线程启动和终止规则
Thread t = new Thread(() -> {
// 这里的操作都能看到start()之前的变量值
System.out.println(x); // B
});
x = 42; // A
t.start(); // C线程启动规则给出的关系是:
2.4 JSR-133规范中的关键定义和术语
定义 2.1(同步操作 Synchronization Actions):
同步操作是线程间协调的特殊操作,包括:
- volatile变量的读/写
- synchronized块的进入/退出(monitor enter/exit)
- Thread.start() 和 Thread.join()
- Object.wait() 和 Object.notify/notifyAll()
- LockSupport.park/unpark(Java 5新增)
- java.util.concurrent中的原子操作
定义 2.2(同步顺序 Synchronization Order):
所有同步操作之间的全序关系,记作 。 对于任意两个同步操作A和B,要么 ,要么 。 同步顺序必须与程序的执行一致。
定义 2.3(同步-with 关系 Synchronization-With):
若 且A和B满足特定的配对关系(如解锁-加锁),则 A 同步-with B,记作 。 同步-with关系是happens-before关系的基础。
定义 2.4(happens-before 关系):
happens-before是程序执行中操作之间的偏序关系,记作 。 若 ,则A的结果对B可见,且A在B之前执行。
happens-before关系的构成规则:
- 程序顺序规则:同一线程内,按程序顺序,前面的操作 后面的操作
- 监视器锁规则:解锁操作 后续对同一锁的加锁操作
- volatile规则:对volatile变量的写操作 后续对该变量的读操作
- 线程启动规则:
Thread.start()该线程的所有操作 - 线程终止规则:线程的所有操作 对该线程终止的检测(
join()返回) - 中断规则:线程A调用
interrupt()线程B检测到中断(抛出InterruptedException或isInterrupted()返回true) - 终结器规则:对象的构造函数完成 其
finalize()方法的开始 - 传递性:若 且 ,则
定义 2.5(数据竞争 Data Race):
当两个线程访问同一内存位置,至少有一个是写操作,且没有happens-before关系协调这两个访问时,发生数据竞争。
定理 2.1(数据竞争自由保证):
如果程序是正确同步的(Correctly Synchronized,即没有数据竞争),那么程序的执行表现出顺序一致性(Sequential Consistency)。
定义 2.6(正确同步的程序 Correctly Synchronized):
本文采用工程化表述:程序没有数据竞争,且跨线程共享状态的访问都由锁、volatile、线程启动/终止等同步关系协调。顺序一致性不是额外前提,而是 DRF 程序获得的保证。
2.5 JSR-133对Java生态的影响
影响1:并发编程的范式转变
// JSR-133前:低级别的并发控制
public class PreJSR133 {
private Object lock = new Object();
public void doWork() {
synchronized (lock) {
// 临界区
}
}
}
// JSR-133后:高级别的并发工具
public class PostJSR133 {
private ExecutorService executor = Executors.newFixedThreadPool(4);
private ConcurrentHashMap<String, Object> cache = new ConcurrentHashMap<>();
private AtomicInteger counter = new AtomicInteger(0);
public void doWork() {
executor.submit(() -> {
cache.computeIfAbsent("key", k -> computeValue());
counter.incrementAndGet();
});
}
}影响2:JVM实现的统一
JSR-133强制要求所有JVM实现必须遵循相同的内存模型:
- HotSpot VM
- OpenJ9(IBM)
- Zing(Azul)
- GraalVM
影响3:编译器优化的限制
JMM定义了编译器和处理器可以进行的优化边界:

图:JMM 规定的编译器优化边界,以及从 Java 5 到 Java 9 的 JMM 演进影响
影响4:对后续Java版本的影响
JSR-133 之后,Java 并发能力沿着这条路径继续演进:Java 5 发布新内存模型和 java.util.concurrent;Java 6 之后并发工具逐步成熟;Java 7 引入 Fork/Join 框架;Java 8 把并行流和 CompletableFuture 带入主流工程实践;Java 9 通过 VarHandle 和 JEP 188 补上更细粒度的内存访问控制。
2.6 JSR-133规范的局限性
尽管JSR-133极大地改进了Java内存模型,但它仍然存在一些局限性:
局限性1:对底层硬件的依赖
JMM仍然是高层抽象,具体实现依赖于底层硬件的内存模型:
- x86的TSO(Total Store Order)
- ARM的弱内存序(Weak Ordering)
- POWER的弱一致性模型
这意味着相同的Java代码在不同架构上可能有不同的性能特征。
局限性2:volatile的开销
volatile变量访问需要插入内存屏障,这会带来性能开销:
- x86:volatile写约3-5ns开销
- ARM:volatile写约15-30ns开销
- 频繁的volatile操作会成为性能瓶颈
局限性3:复杂场景的难以分析
对于复杂的并发程序,happens-before关系可能非常难以分析:
// 复杂的happens-before关系链
public class ComplexHB {
volatile int v1, v2;
int x, y;
void threadA() {
x = 1; // A
v1 = 1; // B (volatile写)
}
void threadB() {
int r1 = v1; // C (volatile读)
y = r1 + 1; // D
v2 = 1; // E (volatile写)
}
void threadC() {
int r2 = v2; // F (volatile读)
// 能否确定看到x=1?
// 但需要确保所有中间步骤都执行
}
}如果所有中间读写都实际发生,关系链可以写成:
局限性4:与C/C++内存模型的差异
Java内存模型与C++11内存模型虽然相似,但存在重要差异:
- C++11提供更细粒度的内存序控制(memory_order_relaxed/acquire/release等)
- Java的volatile相当于C++的memory_order_seq_cst
- Java没有显式的内存屏障API(Java 9的VarHandle部分弥补)
3. happens-before 关系的形式化定义与推导
3.1 基本概念与符号约定
在深入分析happens-before关系之前,我们先建立符号约定:
符号约定:
- 大写字母 A, B, C… 表示操作
- 小写字母 t1, t2… 表示线程
- 表示程序顺序(Program Order)
- 表示happens-before关系
- 表示同步顺序(Synchronization Order)
- 表示 synchronizes-with 关系
定义 2.1(程序顺序 Program Order):
同一线程内,操作按照程序代码的顺序关系。
定义 2.2(同步顺序 Synchronization Order):
所有同步操作之间的全序关系,记作 。它为部分 synchronizes-with 边提供先后依据,但并不是所有同步顺序边都会自动成为 happens-before 边。
3.2 happens-before 规则的完整集合与推导
JSR-133定义了八条happens-before规则,构成JMM的理论基石:
规则 1:程序顺序规则(Program Order Rule)
同一线程内,按程序顺序,前面的操作 happens-before 后面的操作。
int x = 1; // A
int y = x + 1; // B形式化证明:
- 操作A和B在同一线程
- A在程序顺序上先于B
- 根据程序顺序规则:
- B读取x时,根据happens-before的可见性保证,能看到A写入的值
规则 2:监视器锁规则(Monitor Lock Rule)
解锁操作 happens-before 后续对同一锁的加锁操作。
synchronized (lock) {
x = 1; // A
} // 解锁 B
synchronized (lock) {
// 加锁 C
System.out.println(x); // D
}推导过程:
- B是解锁操作,C是加锁操作
- B和C操作同一监视器lock
- B在时间上先于C
- 根据监视器锁规则:
- 根据程序顺序规则:,
- 根据传递性:
- 因此:,D能看到A写入的值
规则 3:volatile变量规则(Volatile Variable Rule)
对volatile变量的写操作 happens-before 后续对该变量的读操作。
volatile int v;
// Thread A
v = 1; // A
// Thread B
int r = v; // B当 A 在同步顺序上先于 B 对同一 volatile 变量的读时,有:
规则 4:线程启动规则(Thread Start Rule)
Thread.start() 调用 happens-before 该线程的所有操作。
Thread t = new Thread(() -> {
// 这里的所有操作都能看到start()之前的变量赋值
System.out.println(x); // B
});
x = 1; // A
t.start(); // C启动规则与程序顺序共同给出:
规则 5:线程终止规则(Thread Termination Rule)
线程的所有操作 happens-before 对该线程终止的检测(join()返回或isAlive()返回false)。
Thread t = new Thread(() -> {
x = 1; // A
});
t.start();
t.join(); // B
int r = x; // 保证看到x=1终止检测规则给出:
规则 6:中断规则(Interruption Rule)
中断调用(interrupt())happens-before 被中断线程检测到中断(抛出InterruptedException或isInterrupted()返回true)。
// Thread A
targetThread.interrupt(); // A
// Thread B (targetThread)
try {
Thread.sleep(1000); // B,抛出InterruptedException
} catch (InterruptedException e) {
// 检测到中断后执行恢复逻辑
}中断规则给出:
规则 7:终结器规则(Finalizer Rule)
对象的构造函数完成 happens-before 其finalize()方法的开始。
public class Resource {
public Resource() {
init(); // A,构造函数
}
@Override
protected void finalize() throws Throwable {
// 构造完成后,finalize才可能开始
cleanup();
}
}终结器规则给出:
规则 8:传递性(Transitivity)
若 且 ,则 。
这是happens-before关系最重要的性质,允许我们推导跨多个线程的可见性保证。
3.3 偏序集与Hasse图表示
happens-before关系构成一个偏序集(Partially Ordered Set, Poset)。我们可以用Hasse图可视化线程间的happens-before关系。
示例1:volatile作为传递桥梁

推导过程:
write(x, 1)write(v, 1)(程序顺序,同一线程A)write(v, 1)read(v)(volatile规则,v是volatile变量)read(v)read(x)(程序顺序,同一线程B)- 由传递性:
write(x, 1)read(x)
因此,Thread B读取x时,保证看到值1。
示例2:synchronized块作为内存屏障

推导:
write(a, 1)synchronized(m) exit(程序顺序)synchronized(m) exitsynchronized(m) entry(监视器锁规则)synchronized(m) entryread(b)(程序顺序)- 由传递性:
write(a, 1)read(b)
同样,write(b, 2) read(a)。
3.4 happens-before关系的实际应用模式
模式1:安全发布(Safe Publication)
public class SafePublication {
private int value;
public SafePublication(int v) {
value = v; // (1)
}
public int getValue() {
return value; // (2)
}
}
// 安全发布模式
SafePublication obj = new SafePublication(42); // (3)
synchronized (lock) {
sharedRef = obj; // (4)
}
// 读取端
SafePublication ref;
synchronized (lock) {
ref = sharedRef; // (5)
}
int v = ref.getValue(); // (6)happens-before链:
- :构造函数到对象引用创建
- :程序顺序
- :监视器锁规则(同一把锁)
- :程序顺序
- 由传递性:,确保看到正确的value值
模式2:volatile实现一次性安全发布
public class VolatileSafePublication {
private volatile SafePublication instance;
public SafePublication getInstance() {
if (instance == null) { // (1)
synchronized (this) {
if (instance == null) { // (2)
instance = new SafePublication(42); // (3)
}
}
}
return instance; // (4)
}
}关键点:
- instance声明为volatile
- (3)的写入 (4)的读取(volatile规则)
- (3)的构造函数写入 (3)的volatile写入
- 确保读取时看到完全初始化的对象
模式3:线程间通信的标准模式
public class ThreadCommunication {
private volatile boolean signal = false;
private int data = 0;
// Thread A: 生产者
public void produce(int value) {
data = value; // (1) 普通写
signal = true; // (2) volatile写
}
// Thread B: 消费者
public int consume() {
while (!signal) { // (3) volatile读
Thread.yield(); // 等待信号
}
return data; // (4) 普通读
}
}happens-before推导:
- :程序顺序(同一线程A)
- :volatile规则
- :程序顺序(同一线程B)
- 由传递性:
这意味着Thread B读取data时,一定能看到Thread A写入的值。
模式4: happens-before的传递性应用
public class TransitivityExample {
volatile int v1 = 0;
volatile int v2 = 0;
int x = 0;
int y = 0;
// Thread 1
void thread1() {
x = 1; // (1)
v1 = 1; // (2)
}
// Thread 2
void thread2() {
int r1 = v1; // (3)
y = 1; // (4)
v2 = 1; // (5)
}
// Thread 3
void thread3() {
int r2 = v2; // (6)
int r3 = x; // (7)
int r4 = y; // (8)
}
}完整的happens-before链:
- :程序顺序
- :volatile规则
- :程序顺序
- :程序顺序
- :volatile规则
- :程序顺序
- :程序顺序
推导结果:
- :
x = 1一定可见 - :
y = 1一定可见
模式5:happens-before的边界
happens-before关系也有其局限性:
public class HBLimitations {
volatile int v;
int x, y;
// Thread A
void writer() {
x = 1; // (1)
y = 2; // (2)
v = 1; // (3)
}
// Thread B
void reader() {
int r = v; // (4)
// r == 1 时
// 保证看到x = 1
// 保证看到y = 2
// 但是:
// 不能保证看到x = 1 和 y = 2 的写入顺序
// 可能看到y = 2 但看不到 x = 1(虽然不可能,因为程序顺序)
}
}重要结论:
- happens-before保证可见性
- 但不保证不同线程的操作按程序顺序观察
- 单线程内,程序顺序是确定的
- 多线程间,只保证同步操作的全序
3.5 happens-before的数学性质
定义:happens-before关系 是动作集合上的二元关系。
性质1:偏序性
happens-before是一个严格偏序(Strict Partial Order):
- 传递性:若 且 ,则
- 非自反性:不存在
- 非对称性:若 ,则不存在
性质2:与同步顺序的一致性

图:happens-before 的四大性质及关系层次——由程序顺序和 synchronizes-with 关系的并集经传递闭包生成
性质3:程序顺序与happens-before
(已包含在上图中)
性质4:happens-before的闭包
happens-before关系是以下关系的传递闭包:
其中, 表示程序顺序, 表示 synchronizes-with 关系,上标 表示传递闭包。
同步-with关系():
| 操作A | 操作B | 条件 |
|---|---|---|
| volatile写 | volatile读 | 同一变量,A在同步顺序中先于B |
| 解锁 | 加锁 | 同一监视器,A在同步顺序中先于B |
| Thread.start() | 线程启动 | 线程T的所有操作 |
| 线程T的所有操作 | Thread.join()返回 | join操作 |
| 构造函数完成 | finalize()开始 | 同一对象 |
3.6 happens-before的图形化表示
Hasse图示例:

图:三个线程间的 happens-before 关系可视化——A 线程写入 volatile 变量与 B 线程读取建立 hb 关系
DAG(有向无环图)表示:

图:happens-before 关系的 DAG 可视化——线程启动、volatile 读写建立跨线程的 happens-before 边
3.7 happens-before与并发正确性
正确性条件:
在工程实践中,一个并发程序要被视为正确同步,核心要求是没有数据竞争:跨线程访问同一共享位置时,如果至少一方写入,就必须通过锁、volatile、线程启动/终止等规则建立 happens-before 约束。满足这个条件后,JMM 才给出 DRF 保证:程序行为可以按顺序一致性理解。
数据竞争的检测:
数据竞争发生的条件:
两个访问 和 发生数据竞争,当且仅当:
- 和 属于不同线程;
- 和 访问同一内存位置;
- 和 中至少一个是写操作;
- 与 之间不存在 happens-before 顺序。
令 表示 与 构成数据竞争, 表示两个访问来自不同线程, 表示两个访问落在同一内存位置, 分别表示 是写操作,则:
这个短符号公式强调的是“不同线程、同一位置、至少一方写入、双方没有 happens-before 排序”四个条件同时成立。同一线程内的访问会被程序顺序排序,因此不会构成这里讨论的数据竞争。
示例:
public class DataRaceExample {
private int sharedVar = 0; // 普通变量
// Thread A
void writer() {
sharedVar = 1; // (1) 写操作
}
// Thread B
void reader() {
int r = sharedVar; // (2) 读操作
}
}分析:
- (1)和(2)访问同一变量
- (1)是写操作
- (1)和(2)之间没有happens-before关系
- 结论:存在数据竞争
修复方案:
public class FixedDataRace {
private volatile int sharedVar = 0; // 改为volatile
// Thread A
void writer() {
sharedVar = 1; // (1) volatile写
}
// Thread B
void reader() {
int r = sharedVar; // (2) volatile读
}
}当 volatile 读 (2) 在同步顺序中位于 volatile 写 (1) 之后时,修复后的核心关系是:
3.8 happens-before的工程应用
应用1:并发集合的实现
// ConcurrentHashMap的可见性保证
public class ConcurrentHashMap<K,V> {
// 使用volatile保证table的可见性
transient volatile Node<K,V>[] table;
// 插入操作
final V putVal(K key, V value) {
// ...
// 写入新节点后
Node<K,V> newNode = new Node<>(hash, key, value, null);
// 使用CAS原子更新
if (casTabAt(tab, i, null, newNode)) {
// CAS成功后,其他线程立即可见
// 因为CAS具有happens-before语义
return null;
}
// ...
}
// 读操作
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first, e;
// 读取table,保证看到最新的修改
if ((tab = table) != null) {
// ...
}
return null;
}
}应用2:线程池的提交与执行
public class ThreadPoolExecutor {
private final BlockingQueue<Runnable> workQueue;
private final HashSet<Worker> workers = new HashSet<>();
// 提交任务
public void execute(Runnable command) {
// ...
// 将任务放入队列
if (isRunning(c) && workQueue.offer(command)) {
// Thread.start()之前设置的变量
// 对Worker线程可见
// 创建工作线程
if (workerCountOf(c) < corePoolSize) {
addWorker(command, true);
return;
}
}
// ...
}
// Worker线程
private final class Worker extends AbstractQueuedSynchronizer
implements Runnable {
public void run() {
// Worker线程能看到execute()中设置的变量
// 因为Worker.start() happens-before run()
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
// 从队列获取任务
while (task != null || (task = getTask()) != null) {
// 执行任务
task.run();
}
}
}
}应用3:Future的可见性保证
public class FutureTask<V> implements RunnableFuture<V> {
private volatile int state;
private Object outcome; // 非volatile!
// 设置结果
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v; // (1) 普通写
// (2) 写入state为NORMAL
UNSAFE.putOrderedInt(this, stateOffset, NORMAL);
// state写入保证后续get()能看到outcome
finishCompletion();
}
}
// 获取结果
public V get() throws InterruptedException, ExecutionException {
int s = state; // (3) volatile读
if (s <= COMPLETING) {
s = awaitDone(false, 0L);
}
// state读 happens-before outcome读
return report(s); // (4) 读取outcome
}
}// 读取端
SafePublication ref;
synchronized (lock) {
ref = sharedRef; // (5)
}
int v = ref.getValue(); // (6)happens-before链:
- :构造函数到对象引用创建
- :程序顺序
- :监视器锁规则(同一把锁)
- :程序顺序
- 由传递性:,确保看到正确的value值
模式2:volatile实现一次性安全发布
public class VolatileSafePublication {
private volatile SafePublication instance;
public SafePublication getInstance() {
if (instance == null) { // (1)
synchronized (this) {
if (instance == null) { // (2)
instance = new SafePublication(42); // (3)
}
}
}
return instance; // (4)
}
}关键点:
- instance声明为volatile
- (3)的写入 (4)的读取(volatile规则)
- (3)的构造函数写入 (3)的volatile写入
- 确保读取时看到完全初始化的对象
4. 乐观锁与微服务并发治理
4.1 从单 JVM 线程安全到分布式并发治理
到这里为止,happens-before 解决的是同一个 JVM 进程内部的可见性、有序性和安全发布问题。它能回答“线程 B 是否一定能看到线程 A 写入的对象状态”,但不能回答“两个服务实例是否会同时扣减同一笔库存”“消息重复投递后是否会重复记账”“缓存击穿时是否会把数据库打穿”这类分布式问题。
这是企业级高并发系统里最容易混淆的一条边界:JMM 是线程内存语义,不是业务一致性协议;Java 锁是进程内互斥,不是跨服务全局互斥;CAS 是单地址原子更新,不是跨数据库、缓存、消息队列的事务。
如果一个业务不变量只存在于 Java 对象里,例如“某个单例配置对象发布后必须被所有线程看到”,JMM 可以给出完整答案:使用 final、volatile、锁、原子类或并发集合建立 happens-before 链即可。如果一个业务不变量落在数据库中,例如“账户余额不能为负”“库存不能超卖”“优惠券只能核销一次”,最终保护点必须放在数据库更新语句、事务隔离级别、唯一约束或版本号 CAS 上,而不是只依赖应用层 synchronized。
企业实践中可以按状态归属划分并发控制责任:
| 状态归属 | 典型问题 | 首选控制点 | 不适合的做法 |
|---|---|---|---|
| 单 JVM 内存 | 对象安全发布、计数器、缓存 Map | final、volatile、锁、CAS、并发集合 | 用数据库锁解决纯内存状态 |
| 单库单行 | 余额扣减、库存扣减、版本化配置 | 条件更新、版本号乐观锁、行级锁 | 先查再改且没有版本校验 |
| 单库多行 | 转账、批量库存、订单状态流转 | 本地事务、唯一约束、隔离级别 | 多条 SQL 分散在多个无事务调用中 |
| 跨服务状态 | 支付、履约、发货、积分联动 | 幂等键、Outbox、Saga、补偿事务 | 把远程调用包在本地 Java 锁里 |
| 缓存状态 | 缓存击穿、重复加载、热点 Key | 单飞加载、短 TTL、异步刷新、互斥重建 | 把缓存当成资金或库存的最终事实源 |
| 消息状态 | 重复消费、乱序消费、至少一次投递 | 消费端幂等、按聚合根分区、事务消息或 Outbox | 假设消息队列天然 exactly-once |
4.2 乐观锁的本质:带条件的提交,不是“无锁万能药”
在生产级微服务里,“乐观锁”不是一个单点技术,而是一组“先读到旧状态,再以旧状态为前提尝试提交”的并发控制模式。不同层次的乐观锁保护的是不同事实源,不能混用:
| 层次 | 常见实现 | 保护对象 | 失败信号 | 典型处理 |
|---|---|---|---|---|
| JVM 内存 | AtomicInteger、AtomicReference、VarHandle.compareAndSet | 当前进程内的一个内存地址或对象引用 | CAS 返回 false | 自旋、退避、降级为锁 |
| 数据库单行 | version 字段、updated_at 条件、UPDATE ... WHERE version = ? | 单行聚合根状态 | 更新行数为 0 | 重新读取、有限重试、返回并发冲突 |
| 数据库不变量 | WHERE balance >= ?、唯一索引、检查约束、本地事务 | 余额不为负、库存不超卖、请求不重复 | 更新失败或唯一约束冲突 | 返回业务失败或幂等结果 |
| 消息与接口 | requestId、commandId、幂等表、消费位点 | 请求、回调、消息的“只执行一次效果” | 幂等键已存在 | 返回历史结果或跳过重复消费 |
| 跨服务流程 | Outbox、Saga、补偿任务、状态机 | 多个服务之间的最终一致性 | 步骤失败、超时、补偿失败 | 重试、补偿、人工介入 |
从形式上看,数据库版本号乐观锁可以理解成事实源上的条件提交:
这里的 表示当前聚合根状态, 表示本次业务变更, 表示调用方读取到的旧版本号, 表示业务不变量,例如余额不能为负、库存不能超卖、状态流转必须合法。公式里的箭头不是 happens-before,它表达的是“只有条件成立才允许提交”的业务规则。也就是说,乐观锁真正保护的不是 Java 对象访问顺序,而是事实源能否接受一次基于旧快照的提交。
这个区别非常重要。JVM 内 AtomicReference.compareAndSet(oldRef, newRef) 的比较对象是一个内存引用;数据库乐观锁比较的是一行或一个聚合根的版本;HTTP ETag 比较的是资源表示;消息幂等表比较的是业务请求 ID。它们都带有“比较后提交”的味道,但一致性边界完全不同。把这些概念混在一起,最常见的事故就是:本地 CAS 成功了,数据库却被另一个实例覆盖;Redis 锁拿到了,业务 SQL 仍然没有保护不变量;接口重试成功返回了两次,账务流水也被写了两次。
4.3 单实例 service:仍然不要把业务一致性锁在 JVM 里
单实例 service 并不意味着可以把业务一致性放进 Java 锁里。只要余额、库存、订单状态等事实最终保存在数据库,synchronized、ReentrantLock 或 AtomicReference 最多只能保护当前 JVM 内的一段代码,不会保护数据库里的事实源。单实例部署时正确做法仍然是:进程内缓存、批处理队列、限流器等临时状态使用 Java 并发工具;业务不变量使用数据库条件更新、事务、唯一约束或版本号乐观锁。这样做不是为了“现在有多个实例”,而是为了让未来扩容、重启、灰度发布、补偿任务、定时任务和消息消费者接入时仍然共享同一个一致性边界。
单实例里可以放进 JVM 的,通常是“丢了可以重建、错了不改变事实”的状态:本地限流滑窗、短生命周期缓存、批量刷盘缓冲、异步任务队列、熔断器状态、指标累加器。不能只放进 JVM 的,是“写错了就改变业务事实”的状态:账户余额、可售库存、优惠券核销、订单支付状态、幂等处理结果、审计流水。前者关注当前进程的并发安全,后者必须由数据库或外部事实源承担最终裁决。
单实例阶段就采用数据库乐观锁,有三个长期收益:
- 扩容成本低:从 1 个实例扩到 N 个实例时,写路径不用从本地锁迁移到数据库约束。
- 异常路径一致:定时任务、补偿任务、后台管理、MQ 消费者和线上接口都走同一套事实源保护。
- 审计证据完整:成功、失败、冲突、幂等命中都有可查询的流水,而不是只存在于进程日志里。
4.4 多实例弹性伸缩:共享事实源才是全局竞态边界
当同一个服务弹性伸缩为多个实例时,竞态会从“多个线程同时进入同一个对象”变成“多个进程同时访问同一行、同一个业务 Key 或同一个下游资源”。此时不能指望任意一个实例的 Java 锁协调全局顺序,所有实例都必须在共享事实源上竞争:
UPDATE inventory
SET available = available - :quantity,
version = version + 1,
updated_at = CURRENT_TIMESTAMP
WHERE sku_id = :skuId
AND available >= :quantity
AND version = :expectedVersion;这条 SQL 才是多实例场景里的“比较并交换”:sku_id 定位同一个事实,available >= :quantity 保护“不超卖”这个业务不变量,version = :expectedVersion 防止旧快照覆盖新状态,更新行数为 1 表示提交成功,更新行数为 0 表示库存已不足或版本已过期。服务实例可以很多,但它们最终都只能通过这条共享原子边界提交状态变化。
如果业务更新跨越多行或多个聚合根,就不能强行把单行乐观锁当作万能事务。例如账户 A 向账户 B 转账,核心不变量是“A 扣款、B 入账、流水记录”共同成立;只给账户 A 加版本号,无法保证账户 B 入账和流水一致。此时应使用本地事务、行级锁、唯一约束、可串行化约束或清晰的聚合边界拆分。跨服务时还要进一步使用 Outbox、Saga、补偿任务和幂等命令,而不是设计一个“全局 version”试图覆盖所有服务。
4.5 重试、热点与降级:乐观锁失败不是无限自旋
版本号乐观锁也不等于“冲突了就一直重试”。低冲突场景可以重新读取后做 2 到 3 次带抖动的退避重试;热点商品、热点账户、秒杀名额这类高冲突场景,盲目重试会把数据库热点行放大成重试风暴,通常要改成按业务 Key 排队、库存分桶、预扣减、令牌化准入或悲观锁/串行化处理。判断乐观锁是否合适,要看冲突概率、写入成本、用户等待时间、失败是否可重试,以及不变量是不是只落在单个聚合根上。
冲突处理要先区分“业务失败”和“技术冲突”。余额不足、库存不足、账户冻结、状态不允许流转,是确定性业务失败,不应重试;版本号不匹配、短暂锁等待超时、数据库死锁重试异常,才可能在有限次数内重试。每次重试必须重新读取最新快照,不能拿旧版本号原地循环;退避必须加入 jitter,避免一批请求在固定间隔后再次同时打到同一热点行。
| 冲突特征 | 适合的策略 | 不适合的策略 |
|---|---|---|
| 低冲突、用户请求可等待 | 版本号乐观锁 + 2 到 3 次退避重试 | 直接加全局悲观锁 |
| 中等冲突、业务 Key 分散 | 按聚合根分区、局部排队、有限重试 | 无限制重试或跨 Key 大锁 |
| 高冲突热点库存 | 令牌化准入、库存分桶、预占、排队削峰 | 所有请求反复读同一行版本 |
| 资金类强一致转账 | 本地事务、行级锁、唯一流水、审计表 | 单行乐观锁覆盖多行不变量 |
| 跨服务流程 | Outbox、Saga、命令幂等、补偿任务 | 全局版本号或远程调用内事务 |
4.6 架构视野:乐观锁要和幂等、Outbox、限流、观测一起设计
跨服务时还要再退一步:不要设计“全局版本号”试图同时锁住订单、支付、库存、积分和物流。每个服务应当拥有自己的聚合根和版本边界,服务之间通过命令幂等、Outbox 事件、消费端幂等、Saga 状态机和补偿任务连接。换句话说,乐观锁适合保护“本服务拥有的事实源”,不适合替代分布式事务协议。
从 happens-before 的角度看,跨服务系统不存在一个由 JVM 规范定义的全局操作偏序。服务 A 完成一次 volatile 写,并不会让服务 B 获得语言规范层面的可见性;服务 A 释放一个 synchronized 锁,也不会 happens-before 另一个进程中的线程加锁。因此,微服务治理中的“并发安全”要把单 JVM 内的 hb 链升级为跨组件的工程链路:
- 请求入口要可控:限流、熔断、隔离、排队和降级用于控制并发进入系统的速率,避免把数据库、缓存和下游服务推入雪崩区。
- 业务操作要幂等:每个扣款、扣库存、发券、发货请求都应有业务幂等键,例如
requestId、orderId、deductId,并通过唯一约束或幂等表防止重复执行。 - 状态更新要原子:核心不变量应落在数据库条件更新、版本号乐观锁、唯一索引、事务或行锁上。例如余额扣减必须让“余额足够”和“余额减少”在同一条 SQL 或同一事务内完成。
- 失败重试要有边界:乐观锁冲突可以重试,但必须有最大次数、退避策略和冲突指标;无限自旋式重试会把热点行冲突放大成数据库雪崩。
- 异步链路要可追溯:本地事务提交后再发消息存在丢消息风险;先发消息再提交数据库存在脏事件风险。Outbox、事务消息、消费端幂等和补偿任务是比“多加一个锁”更可靠的治理手段。
生产系统至少应该观测这些信号:版本冲突率、更新行数为 0 的原因分布、单请求重试次数、热点 Key 排名、幂等命中率、Outbox 延迟、补偿任务积压、数据库死锁/锁等待、成功写入与事件发布的差值。没有这些指标,团队只能在事故后猜测“是不是并发太高”;有了这些指标,才能判断是业务热点、重试放大、慢事务、缺少分片,还是边界设计错误。
可以把并发治理的核心原则压缩成一句话:在哪一层保存事实,就在哪一层保护不变量;在哪一层可能重复,就在哪一层设计幂等;在哪一层可能过载,就在哪一层做准入控制。 JMM 帮助我们写对单 JVM 内部的并发代码,而企业级高并发系统需要把这套思维延伸到数据库、缓存、消息队列和服务治理边界。
5. volatile 的语义与实现机制深度解析
5.1 volatile 的语义规范详解
根据《Java语言规范》第8.3.1.4节,volatile字段具有以下语义:
语义1:可见性(Visibility)
一个线程对volatile变量的写入,对所有后续读取该变量的线程立即可见。
这意味着volatile变量的读写操作具有全局顺序性,所有线程看到的修改顺序是一致的。
语义2:禁止指令重排序(Ordering)
volatile禁止两种重排序:
2.1 编译器重排序:
- volatile写之前的代码不能重排序到volatile写之后
- volatile读之后的代码不能重排序到volatile读之前
2.2 处理器重排序:
- 插入内存屏障(Memory Barrier)阻止CPU指令重排序
形式化表示:
原始代码顺序: 可能的重排序:
Store A Store A
StoreVolatile B Store C
Store C StoreVolatile B(禁止!)
LoadVolatile D LoadVolatile D
Load E Load F
Load F Load E(禁止!)5.2 内存屏障指令与硬件实现
volatile的底层实现依赖于内存屏障(Memory Barrier,又称Memory Fence)。不同处理器架构的屏障指令:
x86/64 架构:
| 屏障指令 | 编码 | 语义 |
|---|---|---|
mfence | 0F AE F0 | 全屏障(LoadLoad + StoreStore + LoadStore + StoreLoad) |
lfence | 0F AE E8 | Load屏障(LoadLoad) |
sfence | 0F AE F8 | Store屏障(StoreStore) |
lock前缀 | F0 | 原子操作,隐含全屏障 |
ARM 架构:
| 指令 | 说明 |
|---|---|
dmb ish | 数据内存屏障,内部共享域 |
dsb ish | 数据同步屏障 |
isb | 指令同步屏障 |
POWER 架构:
| 指令 | 说明 |
|---|---|
lwsync | 轻量级同步(StoreStore + LoadLoad + LoadStore) |
sync | 完全同步(全屏障) |
与第 6 章的关系:
本节只回答 volatile 如何借助屏障建立 release/acquire 语义。四类屏障(LoadLoad、StoreStore、LoadStore、StoreLoad)的完整定义、硬件指令映射和性能成本统一放在第 6 章,避免同一规则在两个章节各自维护。
在 volatile 写路径上,关键是写前的发布约束和写后的 StoreLoad 边界;在 volatile 读路径上,关键是读后的获取约束。不同 CPU 对这些约束的实现强弱不同:x86 TSO 已经天然保证多数顺序,ARM/POWER 需要更显式的 dmb / sync 类指令。
5.3 x86-64 平台的实现深度分析
在x86-64架构下,JVM对volatile的实现相对简单,因为x86本身具有较强的内存序保证(TSO,Total Store Order)。
HotSpot VM实现:
// hotspot/cpu/x86/assembler_x86.hpp
class Assembler : public AbstractAssembler {
// mfence - 内存屏障实现
void mfence() {
emit_int8((unsigned char)0x0F);
emit_int8((unsigned char)0xAE);
emit_int8((unsigned char)0xF0);
}
// lock前缀 - 提供完整的内存屏障
void lock() {
emit_int8((unsigned char)0xF0);
}
};
// hotspot/cpu/x86/templateTable_x86.cpp
void TemplateTable::volatile_barrier(BarrierSet::Name barrier_set) {
// x86下,store使用lock前缀实现StoreLoad屏障
__ lock();
}volatile读的实现:
// hotspot/cpu/x86/templateTable_x86.cpp
void TemplateTable::getfield_or_static(int byte_no, bool is_static) {
// ...
if (is_volatile) {
// x86-64: volatile读不需要特殊屏障
// 因为x86的Load-Load和Load-Store都是按序执行的
// 执行实际读取
__ movl(rax, Address(obj, off));
// 确保后续读操作不会被重排序到前面
// 实际上x86 TSO已经保证这一点
}
}volatile写的实现:
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
// ...
if (is_volatile) {
// StoreStore屏障(防止前面的store被重排序到后面)
// x86: 不需要显式屏障,TSO保证Store-Store顺序
// 执行store
__ movl(Address(obj, off), val);
// StoreLoad屏障(关键!)
// 保证store在load之前完成
// x86: 使用lock addl $0x0, (%%rsp)作为轻量级屏障
__ lock();
__ addl(Address(rsp, 0), 0);
}
}为什么x86 volatile读不需要屏障?
x86-64使用Total Store Order(TSO)内存模型:
- Load-Load:不会重排序
- Load-Store:不会重排序
- Store-Store:不会重排序
- Store-Load:可能重排序
因此,只有volatile写需要StoreLoad屏障。
5.4 ARM 平台的实现深度分析
ARM架构的内存模型更弱(Weak Memory Ordering),需要显式的屏障指令。
ARMv7/v8 实现:
// hotspot/cpu/arm/assembler_arm.hpp
class Assembler : public AbstractAssembler {
// Data Memory Barrier
void dmb(DMB domain = SY, DMB barrier = ISH) {
// DMB ISH: Inner Shareable domain
emit_int32(0xf57ff050 | domain | barrier);
}
// Data Synchronization Barrier
void dsb(DMB domain = SY, DMB barrier = ISH) {
emit_int32(0xf57ff040 | domain | barrier);
}
// Instruction Synchronization Barrier
void isb() {
emit_int32(0xf57ff060);
}
};volatile字段访问的代码生成:
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
if (is_volatile) {
// StoreStore屏障
__ membar(Membar_mask_bits(StoreStore));
// 对应ARM指令: dmb ishst
// 执行store
__ str(val, Address(obj, off));
// StoreLoad屏障
__ membar(Membar_mask_bits(StoreLoad));
// 对应ARM指令: dmb ish
}
}
void TemplateTable::getfield_or_static(int byte_no, bool is_static) {
if (is_volatile) {
// LoadLoad屏障
__ membar(Membar_mask_bits(LoadLoad));
// 对应ARM指令: dmb ishld
// 执行load
__ ldr(rax, Address(obj, off));
// LoadStore屏障
__ membar(Membar_mask_bits(LoadStore));
// 对应ARM指令: dmb ish
}
}ARM vs x86性能对比:
| 操作 | x86开销 | ARM开销 |
|---|---|---|
| volatile读 | ~1ns(无屏障) | ~10-20ns(dmb ishld) |
| volatile写 | ~3-5ns(lock前缀) | ~15-30ns(dmb ish) |
| 普通读 | ~1ns | ~1ns |
| 普通写 | ~1ns | ~1ns |
ARM架构下,volatile操作的开销显著高于x86。
5.5 volatile 的使用场景深度分析
场景1:状态标志位(State Flags)
public class Server {
private volatile boolean running = true;
public void shutdown() {
running = false; // volatile写
}
public void doWork() {
while (running) { // volatile读
processRequest();
}
}
}分析:
- running标志被主线程写入,工作线程读取
- volatile确保工作线程能看到最新的running值
- 无需synchronized,性能更优
场景2:单写多读的配置变量
public class Configuration {
private volatile String configValue;
// 由配置中心单线程更新
public void updateConfig(String value) {
configValue = value;
}
// 由多个业务线程读取
public String getConfig() {
return configValue;
}
}场景3:DCL(Double-Checked Locking)中的实例字段
public class Singleton {
private static volatile Singleton instance;
public static Singleton getInstance() {
if (instance == null) { // 第一次检查
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查
instance = new Singleton(); // volatile写
}
}
}
return instance; // volatile读
}
}关键分析:
- 对象创建过程:分配内存→初始化对象→引用赋值
- 无volatile时,步骤2和3可能重排序,导致其他线程看到未初始化的对象
- volatile禁止这种重排序,确保对象完全初始化后才赋值给引用
场景4:读写锁的读操作优化
public class ReadWriteLock {
private volatile int readCount = 0;
public void lockRead() {
while (true) {
int current = readCount;
if (current >= 0 && readCount == current) {
if (compareAndSet(readCount, current, current + 1)) {
return;
}
}
}
}
}5.6 volatile 的性能特征与优化
性能测试数据(x86-64,JDK 17):
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class VolatileBenchmark {
private int plainInt = 0;
private volatile int volatileInt = 0;
private AtomicInteger atomicInt = new AtomicInteger(0);
@Benchmark
public int plainWrite() {
plainInt = 1;
return plainInt;
}
@Benchmark
public int volatileWrite() {
volatileInt = 1;
return volatileInt;
}
@Benchmark
public int atomicWrite() {
atomicInt.set(1);
return atomicInt.get();
}
}测试结果(ops/us,越高越好):
| 操作 | x86吞吐量 | ARM吞吐量 | x86延迟 |
|---|---|---|---|
| plain写 | 5000+ | 5000+ | ~1ns |
| volatile写 | 800-1000 | 100-200 | ~3-5ns |
| atomic写 | 500-800 | 80-150 | ~5-10ns |
优化建议:
- 批量操作:避免频繁volatile读写,尽量批量处理
- 缓存对齐:确保volatile变量独占缓存行(@Contended)
- 原子类替代:计数场景使用AtomicInteger/AtomicLong
- 无竞争优化:单线程场景不要使用volatile
典型误用与修正:
// 误用1:volatile用于计数(非原子)
public class Counter {
private volatile int count = 0; // 错误!
public void increment() {
count++; // 非原子操作,并发下会丢失更新
}
}
// 修正1:使用AtomicInteger
public class SafeCounter {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // CAS原子操作
}
}
// 误用2:volatile用于多写场景
public class MultiWriter {
private volatile int value; // 多个线程同时写
public void write(int v) {
value = v; // 写操作本身原子,但业务逻辑可能需要同步
}
}
// 修正2:根据场景选择
// - 如果写操作需要互斥,使用synchronized或Lock
// - 如果只是简单赋值,volatile足够6. final 字段的安全发布机制
6.1 final 的语义保证详解
JMM为final字段提供了特殊的初始化保证(Initialization Safety),这是Java并发编程中最重要的简化机制之一。
定理 4.1(Final Field Semantics):
若对象引用在构造函数中没有逸出(escape),则final字段的初始化值对所有获取该对象引用的线程可见。
public class SafePublication {
final int x; // final字段
int y; // 普通字段
public SafePublication() {
x = 1; // (1)
y = 1; // (2)
}
}
// Thread A
SafePublication obj = new SafePublication(); // (3)
// Thread B
SafePublication ref = getRef(); // 获取Thread A创建的引用
System.out.println(ref.x); // 保证看到1
System.out.println(ref.y); // 可能看到0关键区别:
- final字段x:保证看到值1
- 普通字段y:可能看到0(默认值)
6.2 对象初始化的字节码分析
构造函数的编译结果分析:
// Source
public SafePublication() {
x = 1;
y = 1;
}
// Bytecode
0: aload_0
1: invokespecial #1 // Object.<init>
4: aload_0
5: iconst_1
6: putfield #2 // Field x:I (final)
9: aload_0
10: iconst_1
11: putfield #3 // Field y:I
14: return关键差异:
- final字段(第6行):JVM会在构造函数返回前插入StoreStore屏障
- 普通字段(第11行):无特殊屏障
JVM实现:
// hotspot/share/interpreter/bytecodeInterpreter.cpp
CASE(_putfield):
// ...
if (is_final_field) {
// 处理final字段
OrderAccess::storestore(); // StoreStore屏障
}
// 设置字段值
// ...6.3 this 引用逸出问题深度分析
反模式:构造函数中逸出this
public class Unsafe {
final int x;
static Unsafe instance;
public Unsafe() {
x = 1;
instance = this; // this逸出!
}
}问题分析:
- 构造函数执行过程中,this引用被赋值给静态变量
- 其他线程可能通过instance访问到未完全初始化的对象
- 此时final字段可能还未写入,导致看到默认值
安全模式:工厂方法
public class Safe {
final int x;
private Safe() {
x = 1;
}
public static Safe create() {
return new Safe(); // 构造函数完成后才发布引用
}
}其他逸出场景:
public class EscapeExamples {
final int value;
// 场景1:发布内部类引用
public EscapeExamples() {
value = 42;
new Thread(() -> {
// this$0引用逸出
System.out.println(EscapeExamples.this.value);
}).start();
}
// 场景2:监听器注册
public EscapeExamples(EventBus bus) {
value = 42;
bus.register(this); // this逸出
}
// 场景3:重写方法中逸出
public EscapeExamples() {
value = 42;
init(); // 调用可能逸出的方法
}
void init() {
// 子类可能在此逸出this
}
}6.4 内存布局与缓存行
final字段的语义保证还涉及对象内存布局优化。
对象内存布局(64位JVM,开启压缩指针):
偏移量 内容
0x00 Mark Word (8 bytes)
0x08 Klass Pointer (4 bytes)
0x0C 对齐填充(4 bytes)
0x10 int x (final, 4 bytes)
0x14 int y (4 bytes)HotSpot实现:
// hotspot/share/oops/oop.hpp
class oopDesc {
volatile markWord _mark; // 对象头:Mark Word
Klass* _klass; // 对象头:Klass指针
// 实例数据紧随其后
};字段重排序:
JVM可能根据字段类型和访问模式重新排序字段,以优化内存布局:
- final字段可能被放在一起
- 相同类型的字段放在一起
- 经常一起访问的字段放在一起
性能影响:
- final字段的初始化保证减少了同步需求
- 可以安全地在多线程环境中共享不可变对象
- 缓存友好性更好(final字段通常不会改变)
7. 内存屏障与硬件实现
7.1 内存屏障的概念与分类
内存屏障(Memory Barrier,又称Memory Fence)是处理器提供的一种特殊指令,用于控制内存操作的顺序。它是实现JMM同步语义的核心机制。
为什么需要内存屏障?
现代处理器采用乱序执行(Out-of-Order Execution)和推测执行(Speculative Execution)来提升性能:

图:程序顺序 A→B→C→D 与实际执行顺序 A→C→B→D 的对比,C 因操作数就绪而提前执行
内存屏障的四种基本类型:
1. LoadLoad屏障
确保Load1在Load2及后续的Load操作之前完成。
Load1; LoadLoad; Load2
语义:Load1不能重排序到Load2之后使用场景:
- 防止后续的读操作看到”旧”的数据
- 确保读取顺序与程序顺序一致
2. StoreStore屏障
确保Store1在Store2及后续的Store操作之前完成。
Store1; StoreStore; Store2
语义:Store1不能重排序到Store2之后使用场景:
- 确保数据按顺序写入内存
- 用于实现volatile写的顺序保证
3. LoadStore屏障
确保Load1在Store2及后续的Store操作之前完成。
Load1; LoadStore; Store2
语义:Load1不能重排序到Store2之后使用场景:
- 较少单独使用
- 通常在加锁时自动插入
4. StoreLoad屏障
确保Store1在Load2及后续的Load操作之前完成,并且使Store1的结果对所有处理器可见。
Store1; StoreLoad; Load2
语义:Store1必须完成且全局可见,然后才能执行Load2特点:
- 最昂贵的屏障类型
- 需要将Store Buffer中的数据刷新到缓存
- 使Load Buffer中的数据失效
- 触发缓存一致性协议的同步
7.2 不同处理器架构的内存屏障实现
x86/x64 架构(TSO内存模型)
x86采用Total Store Order(完全存储顺序)内存模型,具有较强的内存序保证:
 图:x86 TSO 内存模型 - Load→Load、Load→Store、Store→Store 不允许重排序,仅 Store→Load 可能重排序
图:x86 TSO 内存模型 - Load→Load、Load→Store、Store→Store 不允许重排序,仅 Store→Load 可能重排序
x86内存屏障指令:
| 指令 | 编码 | 语义 | 开销 |
|---|---|---|---|
mfence | 0F AE F0 | 全屏障(LoadLoad+StoreStore+LoadStore+StoreLoad) | 约100-300周期 |
lfence | 0F AE E8 | Load屏障(LoadLoad) | 约50周期 |
sfence | 0F AE F8 | Store屏障(StoreStore) | 约50周期 |
lock前缀 | F0 | 原子操作,隐含StoreLoad屏障 | 约150周期 |
HotSpot x86实现:
// hotspot/cpu/x86/assembler_x86.hpp
class Assembler : public AbstractAssembler {
public:
// mfence - 内存屏障
void mfence() {
emit_int8((unsigned char)0x0F);
emit_int8((unsigned char)0xAE);
emit_int8((unsigned char)0xF0);
}
// sfence - StoreStore屏障
void sfence() {
emit_int8((unsigned char)0x0F);
emit_int8((unsigned char)0xAE);
emit_int8((unsigned char)0xF8);
}
// lfence - LoadLoad屏障
void lfence() {
emit_int8((unsigned char)0x0F);
emit_int8((unsigned char)0xAE);
emit_int8((unsigned char)0xE8);
}
// lock前缀 - 提供完全内存屏障
void lock() {
emit_int8((unsigned char)0xF0);
}
};volatile在x86上的实现:
// hotspot/cpu/x86/templateTable_x86.cpp
void TemplateTable::volatile_barrier(BarrierSet::Name barrier_set) {
// x86下,volatile写使用lock前缀实现StoreLoad屏障
__ lock();
}
// volatile写的代码生成
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
// ...
if (is_volatile) {
// StoreStore屏障 - x86不需要显式屏障(TSO保证)
// 执行store
__ movl(Address(obj, off), val);
// StoreLoad屏障 - 使用lock addl $0x0, (%%rsp)
// 这是一个常见的技巧:对栈顶加0,不影响数据但提供内存屏障
__ lock();
__ addl(Address(rsp, 0), 0);
}
}
// volatile读的代码生成
void TemplateTable::getfield_or_static(int byte_no, bool is_static) {
// ...
if (is_volatile) {
// x86: volatile读不需要特殊屏障
// TSO保证Load-Load和Load-Store不会重排序
__ movl(rax, Address(obj, off));
}
}ARM架构(弱内存序模型)
ARM采用弱内存序(Weak Ordering)模型,需要显式屏障指令:
 图:ARM 弱内存序模型 - 几乎所有重排序都允许,需要显式屏障指令
图:ARM 弱内存序模型 - 几乎所有重排序都允许,需要显式屏障指令
ARM内存屏障指令:
| 指令 | 编码 | 语义 | 开销 |
|---|---|---|---|
dmb ish | 0xF57FF05B | 数据内存屏障(Inner Shareable) | 约50-200周期 |
dmb ishst | 0xF57FF05A | StoreStore屏障 | 约30-100周期 |
dmb ishld | 0xF57FF059 | LoadLoad屏障 | 约30-100周期 |
dsb ish | 0xF57FF04B | 数据同步屏障(更强) | 约100-300周期 |
isb | 0xF57FF06F | 指令同步屏障 | 约50-150周期 |
ARM屏障指令详解:
 图:ARM 屏障指令详解 - DMB、DSB、ISB 三类屏障的作用与使用场景
图:ARM 屏障指令详解 - DMB、DSB、ISB 三类屏障的作用与使用场景
HotSpot ARM实现:
// hotspot/cpu/arm/assembler_arm.hpp
class Assembler : public AbstractAssembler {
public:
// DMB - Data Memory Barrier
enum DMBOption {
SY = 0xF, // Full system
ISH = 0xB, // Inner shareable
ISHST = 0xA, // Inner shareable stores
ISHLD = 0x9 // Inner shareable loads
};
void dmb(DMBOption option = ISH) {
// DMB encoding: 0xF57FF050 | option
emit_int32(0xF57FF050 | option);
}
void dsb(DMBOption option = ISH) {
// DSB encoding: 0xF57FF040 | option
emit_int32(0xF57FF040 | option);
}
void isb() {
// ISB encoding
emit_int32(0xF57FF06F);
}
};
// hotspot/cpu/arm/templateTable_arm.cpp
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
if (is_volatile) {
// StoreStore屏障
__ dmb(Assembler::ISHST);
// 执行store
__ str(val, Address(obj, off));
// StoreLoad屏障
__ dmb(Assembler::ISH);
}
}
void TemplateTable::getfield_or_static(int byte_no, bool is_static) {
if (is_volatile) {
// LoadLoad屏障
__ dmb(Assembler::ISHLD);
// 执行load
__ ldr(rax, Address(obj, off));
// LoadStore屏障
__ dmb(Assembler::ISH);
}
}POWER架构(弱一致性模型)
POWER架构也采用弱一致性模型:
| 指令 | 语义 | 开销 |
|---|---|---|
lwsync | 轻量级同步(StoreStore+LoadLoad+LoadStore) | 约30-100周期 |
sync | 完全同步(全屏障) | 约100-500周期 |
isync | 指令同步 | 约50-150周期 |
// hotspot/cpu/ppc/assembler_ppc.hpp
class Assembler : public AbstractAssembler {
public:
void lwsync() {
emit_int32(0x7C2004AC); // lwsync指令编码
}
void sync() {
emit_int32(0x7C0004AC); // sync指令编码
}
void isync() {
emit_int32(0x4C00012C); // isync指令编码
}
};7.3 内存屏障的性能影响
不同架构的volatile操作开销对比(纳秒):
| 操作 | x86 | ARM | POWER |
|---|---|---|---|
| 普通读 | ~1 | ~1 | ~1 |
| 普通写 | ~1 | ~1 | ~1 |
| volatile读 | ~1 | ~15 | ~20 |
| volatile写 | ~5 | ~25 | ~30 |
| CAS操作 | ~10 | ~30 | ~40 |
性能优化策略:
- 批量操作:
// 低效:频繁volatile操作
for (int i = 0; i < 1000; i++) {
counter.incrementAndGet(); // 1000次volatile写
}
// 高效:批量计算
int local = 0;
for (int i = 0; i < 1000; i++) {
local++;
}
counter.addAndGet(local); // 1次volatile写- 避免伪共享:
// 低效:多个volatile变量在同一缓存行
class BadLayout {
volatile long c1; // 共享缓存行
volatile long c2;
volatile long c3;
volatile long c4;
}
// 高效:填充到不同缓存行
class GoodLayout {
volatile long c1;
long p1, p2, p3, p4, p5, p6, p7; // 56字节填充
volatile long c2;
long q1, q2, q3, q4, q5, q6, q7; // 56字节填充
// ...
}- 使用@Contended(JDK 8+):
import jdk.internal.vm.annotation.Contended;
public class ContendedCounter {
@Contended
private volatile long value;
}
// 启动参数:-XX:-RestrictContended7.4 JVM如何映射内存屏障
JVM通过OrderAccess类提供统一的内存屏障接口,底层映射到不同架构的具体指令:
// hotspot/share/runtime/orderAccess.hpp
class OrderAccess : public AllStatic {
public:
// LoadLoad屏障
static inline void loadload() {
// x86: 无操作(TSO保证)
// ARM: dmb ishld
// POWER: lwsync
}
// StoreStore屏障
static inline void storestore() {
// x86: 无操作(TSO保证)
// ARM: dmb ishst
// POWER: lwsync
}
// LoadStore屏障
static inline void loadstore() {
// x86: 无操作(TSO保证)
// ARM: dmb ish
// POWER: lwsync
}
// StoreLoad屏障(最昂贵)
static inline void storeload() {
// x86: mfence 或 lock addl
// ARM: dmb ish
// POWER: sync
}
// 获取语义(Acquire)
static inline void acquire() {
// LoadLoad + LoadStore
loadload();
loadstore();
}
// 释放语义(Release)
static inline void release() {
// StoreStore + LoadStore
storestore();
loadstore();
}
// 完全内存屏障
static inline void fence() {
storeload();
}
};屏障组合与JMM语义的映射:

8. 缓存一致性协议
8.1 缓存一致性问题背景
在多处理器系统中,每个核心都有自己的缓存层次。当多个核心同时访问同一内存位置时,如何保证所有核心看到的数据是一致的?这就是缓存一致性(Cache Coherence)问题。
缓存不一致的示例:
 图:Core 0写入x=1,但由于缓存一致性延迟,Core 1可能仍读取到旧值x=0
图:Core 0写入x=1,但由于缓存一致性延迟,Core 1可能仍读取到旧值x=0
8.2 MESI协议详解
MESI是最广泛使用的缓存一致性协议,被Intel、AMD等x86处理器采用。
四个状态:
| 状态 | 名称 | 描述 |
|---|---|---|
| M | Modified(修改) | 缓存行已被修改,与主内存不一致,独占访问 |
| E | Exclusive(独占) | 缓存行与主内存一致,独占访问 |
| S | Shared(共享) | 缓存行与主内存一致,可被其他核心共享 |
| I | Invalid(无效) | 缓存行无效,不能读取 |
状态转换图:
 图:MESI协议四种状态 (M-Modified, E-Exclusive, S-Shared, I-Invalid) 及其转换关系
图:MESI协议四种状态 (M-Modified, E-Exclusive, S-Shared, I-Invalid) 及其转换关系
MESI协议消息类型:
| 消息 | 描述 | 触发条件 |
|---|---|---|
Read | 读取缓存行 | 缓存未命中,需要读取数据 |
Read Response | 读响应 | 提供请求的缓存行数据 |
Invalidate | 使无效 | 通知其他核心丢弃缓存行 |
Invalidate Acknowledge | 使无效确认 | 确认已使缓存行无效 |
Read Invalidate | 读并使无效 | 读取并独占缓存行 |
Writeback | 写回 | 将修改的缓存行写回内存 |
状态转换详细分析:
场景1:初始读取(I → E)
Core 0执行 read(x):
1. Core 0发送Read消息到总线
2. 其他核心检查自己的缓存
3. 无人拥有x,内存控制器响应
4. Core 0加载x,状态设为E(独占)场景2:共享读取(I → S)
Core 0拥有x(E),Core 1执行read(x):
1. Core 1发送Read消息
2. Core 0检测到x被自己独占
3. Core 0将x状态改为S(共享)
4. Core 0发送Read Response给Core 1
5. Core 1接收数据,状态设为S
6. 现在x在Core 0和Core 1中都为S状态场景3:独占写入(E → M)
Core 0拥有x(E),执行write(x, newValue):
1. Core 0已经是独占状态
2. 直接修改缓存行
3. 状态变为M(修改)
4. 无需发送消息场景4:共享写入(S → M)
Core 0和Core 1都拥有x(S),Core 0执行write(x, newValue):
1. Core 0发送Invalidate消息到总线
2. Core 1收到Invalidate,将x状态设为I
3. Core 1发送Invalidate Acknowledge
4. Core 0收到所有确认后,修改x
5. Core 0将x状态设为M场景5:修改写回(M → I)
Core 0拥有x(M),Cache需要替换:
1. Core 0将修改的x写回主内存
2. Core 0将x状态设为I
3. 总线监听器检测到这个写回8.3 MESIF协议(Intel改进版)
Intel在MESI基础上增加了Forward状态,形成MESIF协议,用于优化多核读取性能。
MESIF的五个状态:
| 状态 | 名称 | 描述 |
|---|---|---|
| M | Modified | 已修改,独占 |
| E | Exclusive | 独占,与内存一致 |
| S | Shared | 共享,与内存一致 |
| I | Invalid | 无效 |
| F | Forward | 转发,指定响应者 |
MESIF的优化:

8.4 MOESI协议(AMD改进版)
AMD的MOESI协议增加了Owned状态,用于优化写回操作。
MOESI的六个状态:
| 状态 | 名称 | 描述 |
|---|---|---|
| M | Modified | 已修改,独占 |
| O | Owned | 拥有,可被共享,需要写回 |
| E | Exclusive | 独占,与内存一致 |
| S | Shared | 共享,与内存一致 |
| I | Invalid | 无效 |
Owned状态的用途:

8.5 缓存一致性对JMM的影响
Store Buffer与内存屏障:

Invalidate Queue与内存屏障:

JMM的happens-before如何实现:
硬件层面通常由编译器屏障、处理器内存屏障和缓存一致性协议共同完成这个语义:写线程在 volatile 写前后约束普通写的发布顺序,读线程在 volatile 读后重新建立对后续普通读的可见性。换句话说,volatile 不是“强制所有变量都每次从内存读”,而是用一组有序性和可见性约束,把写线程的发布动作与读线程的观察动作连接起来。
9. 指令重排序与 as-if-serial 语义
9.1 重排序的层次与类型
指令重排序是编译器和处理器为了提升性能而进行的重要优化。理解重排序类型对编写正确并发代码至关重要。
重排序的层次:
源代码
↓ 编译器优化
编译期重排序
↓ 指令调度
处理器重排序
↓ 乱序执行
内存系统重排序
↓ 缓存一致性
实际执行顺序编译器重排序(Compiler Reordering):
// 源代码
int a = 1; // A
int b = 2; // B
int c = a + b; // C
// 可能的编译结果(交换A和B)
int b = 2; // B
int a = 1; // A
int c = a + b; // C
// 结果不变,但可能优化缓存使用处理器重排序(Processor Reordering):
- StoreLoad重排序:Store缓冲导致store延迟可见
- LoadLoad重排序:Load乱序执行(ARM常见)
- StoreStore重排序:Store合并写入(x86不会发生)
内存系统重排序(Memory System Reordering):
- 缓存一致性协议导致的延迟
- NUMA架构下的非均匀访问延迟
- 内存控制器重排序
9.2 as-if-serial 语义详解
单线程程序的执行遵循as-if-serial语义,这是编译器和处理器优化的基础。
定义 5.1(As-If-Serial):
单线程程序的执行结果与按程序顺序串行执行的结果相同。
数据依赖关系:
// 可重排序(无数据依赖)
int a = 1; // A
int b = 2; // B
// 不可重排序(有数据依赖)
int a = 1; // A
int b = a + 1; // B,真依赖A的结果
// 不可重排序(反依赖)
int a = b + 1; // A 读b
int b = 2; // B 写b,反依赖
// 不可重排序(输出依赖)
int a = 1; // A
int a = 2; // B,输出依赖数据依赖分类:
真依赖(True Dependency / Flow Dependency):
S1: a = b + c
S2: d = a + e // S2真依赖于S1反依赖(Anti-Dependency):
S1: a = b + c
S2: b = d + e // S2反依赖于S1(写后读)输出依赖(Output Dependency):
S1: a = b + c
S2: a = d + e // S2输出依赖于S1(写后写)真依赖不能被重排序,反依赖和输出依赖可以通过寄存器重命名消除。
9.3 JMM的重排序规则表
JMM定义了以下重排序规则:
| 第一个操作 | 第二个操作 | 普通读 | 普通写 | volatile读 | volatile写 |
|---|---|---|---|---|---|
| 普通读 | - | - | - | 禁止 | |
| 普通写 | - | - | - | 禁止 | |
| volatile读 | 禁止 | 禁止 | - | 禁止 | |
| volatile写 | - | - | 禁止 | 禁止 |
说明:
- ”-“表示可以重排序
- “禁止”表示不能重排序
- volatile读/写具有双向屏障效果
10. synchronized 与锁的内存语义
10.1 synchronized 的 happens-before 保证
synchronized关键字提供互斥性和可见性双重保证。
// Thread A
synchronized (monitor) {
x = 1; // A
} // B: 解锁
// Thread B
synchronized (monitor) {
// C: 加锁
int r = x; // D,保证看到A写入的值
}happens-before推导:
- (程序顺序)
- (监视器锁规则:解锁happens-before后续加锁)
- (程序顺序)
- 由传递性:
10.2 锁的内存屏障实现
HotSpot JVM在锁操作处插入适当的内存屏障:
加锁(Monitor Enter):
void ObjectSynchronizer::enter(Handle obj, ...) {
// 插入LoadLoad和LoadStore屏障
OrderAccess::acquire();
// 执行加锁逻辑
// ...
}解锁(Monitor Exit):
void ObjectSynchronizer::exit(Handle obj, ...) {
// 执行解锁逻辑
// ...
// 插入StoreStore和StoreLoad屏障
OrderAccess::release();
}10.3 锁的优化:偏向锁、轻量级锁、重量级锁
HotSpot JVM对synchronized进行了多级优化。
偏向锁(Biased Locking,历史机制):
偏向锁用于优化“同一线程反复进入同一把锁、几乎没有竞争”的老式负载。它在 JDK 15 中被默认禁用并废弃,在 JDK 18 中已移除。因此,现代 JDK 上分析 synchronized 性能时,不应再把“无锁 → 偏向锁 → 轻量级锁 → 重量级锁”当作当前完整路径;更应该关注轻量级锁、锁膨胀、逃逸分析、锁消除、JFR 中的 monitor enter/blocked 事件以及业务侧的临界区长度。
enum LockState {
unlocked,
biased, // 历史状态:JDK 18 已移除
lightweight, // 轻量级锁
heavyweight, // 重量级锁
inflated
};轻量级锁(Lightweight Locking):
- 使用CAS操作在栈帧中创建Lock Record
- 适用于低竞争场景
- 避免了操作系统互斥量的开销
重量级锁(Heavyweight Locking):
- 使用操作系统的互斥量(mutex)
- 适用于高竞争场景
- 涉及用户态到内核态的切换
10.4 ReentrantLock 的内存语义
java.util.concurrent.locks.ReentrantLock通过AQS实现。
class ReentrantLock implements Lock {
private final Sync sync;
public void lock() {
sync.acquire(1); // 获取锁
}
public void unlock() {
sync.release(1); // 释放锁
}
}AQS实现:
- 使用volatile变量
state - 通过
LockSupport.park/unpark实现线程阻塞 - 提供相同的happens-before保证
11. 伪共享(False Sharing)与缓存行优化
11.1 缓存行基础
现代CPU缓存以缓存行(Cache Line,通常64字节)为单位。
伪共享示例:
CPU Core 0 Cache Line: [volatile long counter0 | long counter1]
CPU Core 1 Cache Line: [volatile long counter0 | long counter1] (副本)当Core 0修改counter0时,Core 1的整个缓存行失效。
11.2 缓存行填充技术
Java 8+(@Contended注解):
@sun.misc.Contended
public class PaddedLong {
volatile long value;
}JVM参数:
-XX:-RestrictContended
-XX:ContendedPaddingWidth=12811.3 Disruptor 的缓存行优化实践
class Sequence extends RhsPadding {
volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
class Value extends LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}12. 实际案例分析
12.1 DCL(Double-Checked Locking)问题
错误的DCL实现:
public class Singleton {
private static Singleton instance; // 非volatile!
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}修正方案:
private static volatile Singleton instance; // 添加volatile12.2 ConcurrentHashMap 的分段锁设计
Java 7使用分段锁(Segment),Java 8使用CAS + synchronized。
13. 伪共享的基准与填充实践
13.1 缓存行基础
现代CPU缓存以缓存行(Cache Line)为单位进行数据传输,典型大小为64字节。
伪共享问题:
当两个线程修改位于同一缓存行的不同变量时,会产生伪共享。
性能测试对比:
@BenchmarkMode(Mode.Throughput)
public class FalseSharingBenchmark {
// 伪共享版本
public static class FalseSharing {
public volatile long counter1 = 0;
public volatile long counter2 = 0;
}
// 无伪共享版本
public static class NoFalseSharing {
@Contended
public volatile long counter1 = 0;
@Contended
public volatile long counter2 = 0;
}
}测试结果:双线程场景下,伪共享可导致性能下降32倍。
13.2 @Contended注解(JDK 8+)
import jdk.internal.vm.annotation.Contended;
public class ContendedExample {
@Contended
private volatile long counter1;
@Contended
private volatile long counter2;
}13.3 手动填充技术(JDK 8之前)
class Sequence extends RhsPadding {
volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
class Value extends LhsPadding {
protected long value;
}
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}14. JSR-133 形式化语义补充
14.1 规范制定的历史背景
Java内存模型的标准化经历了漫长的演进过程。在Java语言诞生初期(1996年),Java规范对多线程语义的定义存在严重缺陷,这导致了著名的”双重检查锁定失效”问题等一系列并发Bug。
JSR-133制定动机:
- 原始JMM的问题:最初的Java语言规范对多线程程序的行为缺乏精确定义,导致不同JVM实现之间存在差异
- 编译器优化与正确性的矛盾:编译器和处理器为了性能会进行指令重排序,但原始规范没有明确界定合法的重排序边界
- 开发者困惑:并发程序的行为在不同平台上表现不一致,难以编写可移植的并发代码
JSR-133发展历程:
| 时间 | 事件 | 影响 |
|---|---|---|
| 1997年 | Java 1.1发布 | 发现多线程语义问题 |
| 1999年 | JSR-133成立 | Bill Pugh领导专家组 |
| 2004年 | JSR-133最终发布 | 随Java 5.0 (Tiger)发布 |
| 2014年 | Java 8发布 | 完善了内存模型文档 |
14.2 核心术语与定义
JSR-133定义了一系列关键术语,构成了内存模型的形式化基础:
定义 9.1(动作 Action):
动作是程序执行过程中的操作单元,包括:
- 共享内存读取:从主内存读取变量值
- 共享内存写入:向主内存写入变量值
- 加锁:获取监视器锁
- 解锁:释放监视器锁
- 外部动作:与外部系统交互(如I/O)
- 线程分叉:启动新线程
- 线程合并:线程终止
定义 9.2(执行 Execution):
执行E = <P, A, po, so, W, V, sw, hb>,其中:
- P:程序
- A:动作集合
- po:程序顺序关系
- so:同步顺序关系
- W:写操作集合
- V:可见性函数
- sw:同步-with关系
- hb:happens-before关系
14.3 形式化语义详解
14.3.1 程序顺序(Program Order)
程序顺序定义了单线程内动作在一次实际执行中的先后关系,而不是简单的源码行号比较:
令 表示“动作 在程序顺序上先于动作 ”。在本文的简化表达中,它成立的条件是:
其中, 表示 与 属于同一线程, 是 的短写,表示在这次执行的单线程语义中, 的动作先于 发生。这样可以覆盖分支、循环、方法调用展开后的真实执行顺序,避免把程序顺序误解成纯粹的静态文本顺序。
14.3.2 Happens-Before关系的数学表达
happens-before关系不是把所有同步动作的同步顺序(so)直接并入可见性顺序,而是把程序顺序(po)与synchronizes-with关系(sw)作为基础边,再取传递闭包。同步顺序是构造部分 sw 边的依据,但并不是所有 so 边都会自动成为 happens-before 边。
更准确地说,hb 是包含 po 与 sw 的最小传递关系。下面写成三条生成规则,避免把递归定义误读为任意布尔等价式:
其中:
po(a, b):动作a与b属于同一线程,并且a在程序顺序上先于bsw(a, b):动作asynchronizes-with 动作b,例如 monitor unlock 到后续 lock、volatile write 到后续 read、线程 start 到被启动线程中的动作等A:当前执行中的动作集合c:动作集合A中的任一中间动作,用来表达传递性
形式化地,可以写成:
这里的上标 + 表示传递闭包:如果 a happens-before c,且 c happens-before b,则 a happens-before b。
14.4 内存模型规则的形式化描述
14.4.1 监视器锁规则
监视器锁规则描述的是同一个 monitor 上的释放与获取关系:对某个监视器 m 执行的 unlock,synchronizes-with 之后任何线程对同一个 m 执行的 lock。这条 synchronizes-with 边随后进入 happens-before 关系。
等价地,可以把这条规则理解为:令 ,,则:
工程含义是:线程在退出 synchronized 临界区之前写入的共享状态,对随后进入同一个 synchronized 临界区的线程可见。这里的关键不是“两个线程使用了 synchronized”这个语法事实,而是它们必须竞争或经过同一个 monitor 对象,否则不会建立这条锁规则下的 happens-before 边。
14.4.2 Volatile变量规则
volatile 变量规则描述的是同一个 volatile 变量上的写读发布关系:对 volatile 变量 v 的写操作,synchronizes-with 同步顺序中随后对同一个 v 的读操作,并进一步建立 happens-before。
这里 VolWrite 与 VolRead 分别是 volatile 写和 volatile 读的缩写。
因此更准确的表述不是 hb(w, r) 当且仅当 so(w, r),而是:当 w 是对同一个 volatile 变量 v 的写,r 是同步顺序中位于其后的 volatile 读时,w 与 r 之间建立 sw,进而建立 hb。so 是所有同步动作上的全序,不能简单等同于 hb。
从内存语义看,volatile 写近似于 release,volatile 读近似于 acquire:
- volatile 写之前的普通写,不能被重排序到该 volatile 写之后
- volatile 读之后的普通读写,不能被重排序到该 volatile 读之前
- volatile 并不是“禁止所有指令重排序”,而是禁止会破坏 volatile 可见性与有序性保证的重排序
14.5 内存模型的正确性保证
保证1:数据竞争自由程序的顺序一致性
无数据竞争程序的执行在所有顺序一致的执行中都是顺序一致的。
保证2:正确同步程序的行为
正确同步的程序的语义与顺序一致模型相同(程序员可以按顺序思考)。
15. 不同处理器架构的内存模型对比
15.1 内存模型的分类
现代处理器按内存模型强弱可分为三类:
顺序一致性(Sequential Consistency):
- 理论模型,实际处理器不实现
- 所有内存操作按程序顺序全局执行
强内存模型(Strong Memory Model):
- 处理器保证大多数内存操作的顺序
- 例:x86/x86_64的TSO(Total Store Order)
弱内存模型(Weak Memory Model):
- 允许大量指令重排序
- 需要显式屏障指令保证顺序
- 例:ARM, POWER, RISC-V
15.2 x86/x86_64的TSO模型
TSO(Total Store Order)特性:
允许的优化(无需屏障):
- Store-Store:处理器可以合并相邻的Store
- Load-Load:乱序执行但按序提交
- Load-Store:Load可以越过Store(如果地址不同)
禁止的优化(自动保证):
- Store-Load:Store不能越过后续Load(TSO核心)
- Load-Store:同一地址的依赖关系
x86的内存屏障指令:
// mfence:全屏障
__asm__ volatile ("mfence" ::: "memory");
// sfence:Store屏障
__asm__ volatile ("sfence" ::: "memory");
// lfence:Load屏障
__asm__ volatile ("lfence" ::: "memory");15.3 ARM64的弱内存模型
ARM64内存模型特性:
允许的优化(默认):
- Load-Load重排序
- Load-Store重排序
- Store-Store重排序
- Store-Load重排序(某些情况)
需要显式屏障保证顺序:
- DMB (Data Memory Barrier)
- DSB (Data Synchronization Barrier)
- ISB (Instruction Synchronization Barrier)
ARM64屏障映射到JSR-133:
| JSR-133屏障 | ARM64实现 | 成本 |
|---|---|---|
| LoadLoad | dmb ishld | 约10ns |
| StoreStore | dmb ishst | 约10ns |
| LoadStore | dmb ish | 约15ns |
| StoreLoad | dmb ish | 约15ns |
15.4 跨平台性能考量
屏障性能对比(近似值,CPU周期):
| 平台 | LoadLoad | StoreStore | LoadStore | StoreLoad |
|---|---|---|---|---|
| x86_64 | 0 | 0 | 0 | 20-50 |
| ARM64 | 约10 | 约10 | 约15 | 约15 |
| POWER | 约15 | 约15 | 约15 | 约50-100 |
| RISC-V | 约10 | 约10 | 约10 | 约20 |
16. 生产环境并发问题诊断与案例分析
16.1 常见并发Bug模式
模式1:不正确的volatile使用
// 错误:volatile不能保证复合操作的原子性
public class VolatileCompound {
private volatile int counter = 0;
// 非原子操作!
public void increment() {
counter++; // 实际是 读 -> 加1 -> 写
}
}
// 修复
private final AtomicInteger counter = new AtomicInteger(0);
public void increment() {
counter.incrementAndGet(); // CAS原子操作
}模式2:发布逸出(Unsafe Publication)
// 不安全的对象发布
public void initialize() {
holder = new Holder(42); // 构造函数可能未完成
}
// 修复:使用volatile
private volatile Holder holder;16.2 真实生产环境Bug案例
案例1:电商系统的订单号生成器并发问题
问题描述: 在高并发场景下,订单号生成器出现重复订单号,导致数据库主键冲突。
原始代码:
public class OrderIdGenerator {
private static long lastTimestamp = -1L;
private static long sequence = 0L;
// 问题:缺少同步
public static synchronized String generateOrderId() {
long timestamp = System.currentTimeMillis();
if (timestamp == lastTimestamp) {
sequence++;
if (sequence > 4095) {
// 等待下一毫秒
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
sequence = 0;
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return String.format("%d%04d", timestamp, sequence);
}
}问题分析:
- 使用了synchronized保证原子性,但性能差
- 在分布式部署时,多个JVM实例可能生成重复ID
- 缺少必要的volatile保证
修复方案:
public class OrderIdGenerator {
private static final AtomicLong sequence = new AtomicLong(0);
private static final long WORKER_ID = getWorkerId(); // 机器ID
// 使用雪花算法
public static String generateOrderId() {
long timestamp = System.currentTimeMillis();
long seq = sequence.incrementAndGet() & 0xFFF;
// 41位时间戳 + 10位机器ID + 12位序列号
long orderId = ((timestamp - EPOCH) << 22)
| (WORKER_ID << 12)
| seq;
return Long.toString(orderId);
}
}经验总结:
- 单机场景使用原子类代替synchronized
- 分布式场景需要考虑机器ID
- 使用成熟的分布式ID生成方案(如雪花算法)
案例2:金融系统的账户余额并发扣减
问题描述: 在营销扣费、预授权、退款抵扣或库存预占这类高并发链路中,多个请求可能同时扣减同一个账户或同一个资源。线上常见结果不是简单的“Java 多线程 bug”,而是余额被重复扣减、库存被超卖、流水缺失、消息重投后重复执行,或者服务扩容后原本单实例可控的锁方案突然失效。
原始代码:
@Service
public class AccountService {
@Autowired
private AccountRepository accountRepository;
// 问题:没有处理并发
public boolean deduct(Long accountId, BigDecimal amount) {
Account account = accountRepository.findById(accountId).orElse(null);
if (account == null) return false;
// 并发问题:多个线程可能同时读取到相同的余额
if (account.getBalance().compareTo(amount) >= 0) {
account.setBalance(account.getBalance().subtract(amount));
accountRepository.save(account);
return true;
}
return false;
}
}问题分析:
findById -> 判断余额 -> save是典型的读-检查-写拆分,两个事务可以读到同一个旧余额,然后互相覆盖。synchronized、ReentrantLock、AtomicReference只能保护当前 JVM;一旦服务有多个实例、MQ 消费者、补偿任务或后台 Job,同时写库的路径就会绕过本地锁。- Redis 分布式锁可以降低入口竞争,但不能替代数据库事实源约束;锁 TTL 过期、客户端停顿、网络抖动、绕过锁的写路径都可能让最终状态出错。
- 真正需要被保护的是业务不变量:余额不能为负,同一请求只能生效一次,成功扣减必须有审计流水,扣减成功后的事件不能丢。
常见方案对比:
@Service
public class AccountService {
@Autowired
private AccountRepository accountRepository;
// 方案1:数据库乐观锁
public boolean deduct(Long accountId, BigDecimal amount) {
int updated = accountRepository.deductBalance(accountId, amount);
return updated > 0;
}
}
// Repository层
@Modifying
@Query("UPDATE Account a SET a.balance = a.balance - :amount, " +
"a.version = a.version + 1 " +
"WHERE a.id = :accountId AND a.balance >= :amount")
int deductBalance(@Param("accountId") Long accountId,
@Param("amount") BigDecimal amount);
// 方案2:Redis分布式锁
public boolean deductWithLock(Long accountId, BigDecimal amount) {
String lockKey = "account:" + accountId;
Boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (!locked) return false;
try {
// 执行扣减逻辑
return executeDeduct(accountId, amount);
} finally {
redisTemplate.delete(lockKey);
}
}
// 方案3:Java层原子操作(配合数据库)
public boolean deductAtomic(Long accountId, BigDecimal amount) {
AtomicBoolean success = new AtomicBoolean(false);
accountRepository.findById(accountId).ifPresent(account -> {
// 使用AtomicReference存储余额
AtomicReference<BigDecimal> balance =
new AtomicReference<>(account.getBalance());
balance.updateAndGet(current -> {
if (current.compareTo(amount) >= 0) {
success.set(true);
return current.subtract(amount);
}
return current;
});
if (success.get()) {
account.setBalance(balance.get());
accountRepository.save(account);
}
});
return success.get();
}上面三类写法经常同时出现在真实项目里,但它们的安全等级完全不同。方案 1 的核心是数据库条件更新,它把“不允许扣成负数”放在事实源上;方案 2 只是入口互斥,适合作为热点削峰的外围手段;方案 3 只保护当前方法里的临时变量,不能保护数据库写入,生产上不应把它当成账户扣减方案。
经验总结:
- 金融、库存、优惠券、积分这类资产类操作,最终一致性边界必须落在数据库条件更新、事务、唯一约束、版本号或行级锁上。
- 单实例 service 也应按多实例标准设计写路径;否则弹性伸缩、灰度发布、补偿任务和 MQ 消费者接入时会重新暴露竞态。
- 乐观锁适用于低到中等冲突、提交代价可控、失败可重试的聚合根更新;热点资源应优先考虑排队削峰、分片、预占、令牌化准入或悲观锁。
- 分布式锁只能减少并发进入临界区,不能替代事实源约束;核心 SQL 仍要能在没有锁的情况下保持不变量成立。
企业级方案:把并发控制放到事实源上
上面的三个方案代表了不同层次的并发控制,但它们不能等价看待。数据库条件更新保护的是最终事实源;Redis 分布式锁保护的是跨 JVM 的临界区入口;Java 层 AtomicReference 只保护当前进程中的临时对象,不能阻止另一个服务实例同时把旧余额写回数据库。因此,在金融、库存、优惠券、积分这类核心资产场景中,企业级方案通常以数据库条件更新或版本号乐观锁为主,分布式锁、限流、幂等和重试退避作为外围治理。
更稳健的余额扣减表结构通常会显式包含版本号、业务幂等键和审计流水:
CREATE TABLE account (
id BIGINT PRIMARY KEY,
balance DECIMAL(18, 2) NOT NULL,
version BIGINT NOT NULL DEFAULT 0,
updated_at TIMESTAMP NOT NULL
);
CREATE TABLE account_deduct_log (
id BIGINT PRIMARY KEY,
account_id BIGINT NOT NULL,
request_id VARCHAR(64) NOT NULL,
amount DECIMAL(18, 2) NOT NULL,
status VARCHAR(16) NOT NULL,
result_code VARCHAR(32) NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
UNIQUE KEY uk_deduct_request (request_id)
);
CREATE TABLE account_outbox (
id BIGINT PRIMARY KEY,
aggregate_id BIGINT NOT NULL,
event_type VARCHAR(64) NOT NULL,
payload TEXT NOT NULL,
status VARCHAR(16) NOT NULL,
created_at TIMESTAMP NOT NULL
);如果扣减只涉及单账户余额,首选方案是把余额校验和余额更新合并到同一条 SQL 中。这个写法适合“只要余额足够即可扣减”的短事务路径,不需要先把账户完整读出来:
public interface AccountRepository extends JpaRepository<Account, Long> {
@Modifying
@Query("""
UPDATE Account a
SET a.balance = a.balance - :amount,
a.version = a.version + 1,
a.updatedAt = :now
WHERE a.id = :accountId
AND a.balance >= :amount
""")
int deductIfEnough(@Param("accountId") Long accountId,
@Param("amount") BigDecimal amount,
@Param("now") Instant now);
}这种写法的关键不是“用了 Java 锁”,而是把 balance >= amount 和 balance = balance - amount 放在数据库同一个原子更新动作里。并发请求即使同时到达,也只有满足条件的更新会成功;失败请求返回 0 行更新,业务层再读取当前余额即可区分“余额不足”和“被其他事务抢先更新后需要重试”。
如果业务必须先读取账户状态、做风控校验、计算手续费、检查账户状态,再提交扣减,可以使用版本号乐观锁。生产实现里还要注意幂等占位:不能只在方法开头 existsByRequestId,因为两个重复请求可能同时看到“不存在”,随后一起进入扣减逻辑。更稳妥的方式是在同一个事务中先插入 PROCESSING 流水,依靠唯一约束抢占请求处理权:
@Transactional
public DeductResult deductWithOptimisticLock(DeductCommand command) {
DeductLog claimed = deductLogRepository.tryInsertProcessing(
command.requestId(),
command.accountId(),
command.amount()
);
if (!claimed.isNew()) {
return DeductResult.fromExisting(claimed);
}
Account account = accountRepository.findById(command.accountId())
.orElse(null);
if (account == null) {
deductLogRepository.markFailed(command.requestId(), "ACCOUNT_NOT_FOUND");
return DeductResult.accountNotFound(command.requestId());
}
if (account.getBalance().compareTo(command.amount()) < 0) {
deductLogRepository.markFailed(command.requestId(), "INSUFFICIENT_BALANCE");
return DeductResult.insufficientBalance(command.requestId());
}
int updated = accountRepository.deductByVersion(
account.getId(),
command.amount(),
account.getVersion(),
Instant.now()
);
if (updated == 0) {
deductLogRepository.markConflict(command.requestId());
return DeductResult.conflict(command.requestId());
}
deductLogRepository.markSuccess(
command.requestId(),
"OK"
);
outboxRepository.append(
AccountDeductedEvent.from(command)
);
return DeductResult.success(command.requestId());
}示例中的 tryInsertProcessing 不是普通的“先查再插”,而是依赖数据库唯一约束的原子占位。不同数据库写法不同,核心语义是“只有一个请求能拿到这个 request_id 的处理权”:
INSERT INTO account_deduct_log (
id,
account_id,
request_id,
amount,
status,
result_code,
created_at,
updated_at
) VALUES (
:id,
:accountId,
:requestId,
:amount,
'PROCESSING',
'PENDING',
CURRENT_TIMESTAMP,
CURRENT_TIMESTAMP
);如果插入触发 uk_deduct_request 唯一约束冲突,说明同一个业务请求已经被另一个线程、实例、客户端重试或消息重投处理过,业务层应读取已有流水并返回历史结果,而不是再次扣减。对应的 Repository 更新语句必须携带旧版本号:
@Modifying
@Query("""
UPDATE Account a
SET a.balance = a.balance - :amount,
a.version = a.version + 1,
a.updatedAt = :now
WHERE a.id = :accountId
AND a.version = :expectedVersion
AND a.balance >= :amount
""")
int deductByVersion(@Param("accountId") Long accountId,
@Param("amount") BigDecimal amount,
@Param("expectedVersion") long expectedVersion,
@Param("now") Instant now);这里的 @Transactional 只覆盖本服务数据库内的流水、余额和 Outbox 写入,不覆盖远程支付服务、库存服务或 MQ broker。事务提交后,由 Outbox relay 异步发布 AccountDeductedEvent;消费者再用自己的幂等键处理事件。这样即使服务在“扣减成功但消息尚未发送”时崩溃,也可以通过扫描 Outbox 补发,而不是依赖内存队列或 try-catch 后立即发 MQ。
单实例 service 的落地边界可以这样理解:
| 场景 | 可以放在 JVM 内 | 必须放在数据库或外部事实源 |
|---|---|---|
| 本地限流器 | 令牌桶计数、滑动窗口缓存 | 多实例全局配额、资金扣减结果 |
| 本地批处理 | 当前实例的聚合队列、批量刷盘缓冲 | 已处理请求、成功扣减流水 |
| 本地缓存 | 账户展示信息、商品详情副本 | 账户余额、可售库存、核销状态 |
| 本地锁 | 防止同一实例重复刷新缓存 | 防止多个实例同时扣减同一账户 |
换成 Kubernetes、ECS 或虚拟机弹性伸缩后,服务实例之间没有共享堆内存,synchronized 锁对象、ReentrantLock 队列和 AtomicReference 引用都只存在于各自进程内。多实例下的数据安全来自三个共同点:所有写请求携带同一个业务幂等键,所有状态变化都提交到同一个事实源条件更新,所有异步副作用都能从事务日志或 Outbox 恢复。
乐观锁冲突不应该简单地无限重试。企业级系统通常会把冲突处理显式纳入治理策略:
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| 低冲突账户扣减 | 乐观锁 + 2 到 3 次指数退避重试 | 避免偶发冲突暴露给用户 |
| 热点库存或热点账户 | 条件更新 + 排队削峰 + 分片账户或库存桶 | 热点行冲突会让乐观锁退化为重试风暴 |
| 强一致资金转账 | 本地事务 + 行级锁或可串行化约束 | 涉及两个账户或多行不变量时,单行 CAS 不够 |
| 跨服务扣减链路 | 幂等键 + Outbox/Saga + 补偿任务 | 远程调用无法加入同一个本地数据库事务 |
| 重复请求或消息重投 | 幂等表 + 唯一约束 + 消费端去重 | 网络超时后客户端和 MQ 都可能重复投递 |
冲突处理还要区分“业务失败”和“技术冲突”。余额不足、库存不足、账户冻结是确定性业务失败,不应该重试;version 不匹配、死锁重试异常、短暂锁等待超时才可能进入有限重试。重试必须重新读取最新快照,不能拿旧版本号原地循环;每次退避要加入 jitter,避免同一批请求在固定间隔后再次同时打到热点行。
一个更接近生产的外层编排通常会把幂等、限流、隔离和有限重试拆清楚:
public DeductResult deductWithPolicy(DeductCommand command) {
return idempotencyGuard.execute(command.requestId(), () -> {
String resourceKey = "account:" + command.accountId();
if (!rateLimiter.tryAcquire(resourceKey)) {
return DeductResult.rejected("too_many_requests");
}
return bulkhead.execute(resourceKey, () ->
retryWithJitter.execute(
retry -> deductWithOptimisticLock(command),
result -> result.isRetryableConflict()
)
);
});
}这段代码的工程含义是:JMM 负责保证当前 JVM 内 idempotencyGuard、rateLimiter、bulkhead、retryWithJitter 等组件自身的线程安全;业务一致性仍由数据库条件更新、版本号、唯一约束和事务日志兜底。外层幂等守卫可以做短路缓存和重复请求快速返回,但最终裁决仍应以数据库唯一约束和扣减流水为准。
生产上还应为这条链路配置专门指标,而不是只看接口平均耗时:
| 指标 | 说明 | 异常信号 |
|---|---|---|
optimistic_lock_conflict_total | 版本号或条件更新失败次数 | 突然升高说明热点行或重试风暴 |
deduct_retry_attempts | 单次业务请求的重试次数分布 | P95/P99 偏高说明乐观锁不再适合 |
idempotency_hit_total | 幂等命中次数 | 异常升高说明客户端超时、MQ 重投或上游重复提交 |
outbox_lag_seconds | Outbox 事件从写入到发布的延迟 | 持续升高说明异步发布链路堆积 |
deduct_processing_stuck_total | 长时间停留在 PROCESSING 的流水数 | 说明事务边界、异常处理或补偿任务有漏洞 |
落地时可以按下面的顺序设计:
- 先定义业务不变量:余额不能为负、同一请求只能扣一次、扣减成功必须有流水。
- 再确定事实源:余额以数据库为准,缓存只能加速读取,不能作为扣减成功的最终依据。
- 然后选择并发控制:单行扣减优先条件更新,多行不变量使用事务和行锁,跨服务使用 Saga/Outbox。
- 最后补治理能力:幂等、限流、熔断、隔离、重试退避、冲突监控、补偿任务和审计报表。
案例3:缓存系统的缓存击穿问题
问题描述: 热点数据失效时,大量请求同时访问数据库,导致数据库压力激增。
原始代码:
@Service
public class CacheService {
@Autowired
private CacheManager cacheManager;
@Autowired
private DataRepository dataRepository;
public Data getData(String key) {
// 问题:没有处理缓存击穿
Data data = cacheManager.get(key);
if (data == null) {
data = dataRepository.findByKey(key);
cacheManager.put(key, data, 1, TimeUnit.HOURS);
}
return data;
}
}问题分析:
- 缓存失效瞬间,多个线程同时访问数据库
- 没有使用互斥锁重建缓存
- 可能导致数据库雪崩
修复方案:
@Service
public class CacheService {
@Autowired
private CacheManager cacheManager;
@Autowired
private DataRepository dataRepository;
// 使用ConcurrentHashMap存储重建锁
private final ConcurrentHashMap<String, Lock> rebuildLocks =
new ConcurrentHashMap<>();
// 方案1:互斥锁重建
public Data getDataWithLock(String key) {
// 1. 先查缓存
Data data = cacheManager.get(key);
if (data != null) return data;
// 2. 获取重建锁
Lock lock = rebuildLocks.computeIfAbsent(key, k -> new ReentrantLock());
try {
if (!lock.tryLock(100, TimeUnit.MILLISECONDS)) {
// 获取锁失败,返回默认值或等待
return getDefaultData(key);
}
try {
// 双重检查
data = cacheManager.get(key);
if (data != null) return data;
// 重建缓存
data = dataRepository.findByKey(key);
if (data != null) {
cacheManager.put(key, data, 1, TimeUnit.HOURS);
}
return data;
} finally {
lock.unlock();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return null;
}
}
// 方案2:使用Guava Cache(自动处理)
private final LoadingCache<String, Data> cache = CacheBuilder.newBuilder()
.maximumSize(10000)
.expireAfterWrite(1, TimeUnit.HOURS)
.build(new CacheLoader<String, Data>() {
@Override
public Data load(String key) {
return dataRepository.findByKey(key);
}
});
public Data getDataWithGuava(String key) {
try {
return cache.get(key); // 自动处理并发加载
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
}
// 方案3:分布式锁 + 异步重建
public Data getDataWithDistributedLock(String key) {
Data data = cacheManager.get(key);
if (data != null) return data;
// 使用Redis分布式锁
String lockKey = "cache:rebuild:" + key;
Boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (locked) {
try {
// 只有一个线程能重建缓存
data = dataRepository.findByKey(key);
if (data != null) {
cacheManager.put(key, data, 1, TimeUnit.HOURS);
}
return data;
} finally {
redisTemplate.delete(lockKey);
}
} else {
// 其他线程等待一段时间后重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return getDataWithDistributedLock(key); // 重试
}
}
}经验总结:
- 缓存击穿是常见的并发问题
- 使用互斥锁保证只有一个线程重建缓存
- Guava Cache和Caffeine等库自动处理此类问题
- 考虑使用分布式锁处理集群部署
案例4:消息队列的消费顺序问题
问题描述: 使用多线程消费消息时,同一用户的订单消息处理顺序错乱,导致业务异常。
原始代码:
@Component
public class MessageConsumer {
private ExecutorService executor = Executors.newFixedThreadPool(10);
// 问题:消息可能乱序处理
@KafkaListener(topics = "order-topic")
public void consume(ConsumerRecord<String, String> record) {
executor.submit(() -> processMessage(record));
}
private void processMessage(ConsumerRecord<String, String> record) {
// 处理订单消息
Order order = parseOrder(record.value());
orderService.processOrder(order);
}
}问题分析:
- 多线程并行处理导致消息乱序
- 同一用户的订单可能被打乱
- 创建订单和支付回调顺序错乱
修复方案:
@Component
public class OrderedMessageConsumer {
// 使用ConcurrentHashMap存储每个用户的消息队列
private final ConcurrentHashMap<String, LinkedBlockingQueue<Message>>
userMessageQueues = new ConcurrentHashMap<>();
// 使用线程池处理每个用户的消息
private final ExecutorService userExecutors = Executors.newCachedThreadPool();
@KafkaListener(topics = "order-topic")
public void consume(ConsumerRecord<String, String> record) {
String userId = extractUserId(record.key());
// 将消息放入对应用户的队列
LinkedBlockingQueue<Message> queue = userMessageQueues
.computeIfAbsent(userId, k -> new LinkedBlockingQueue<>());
queue.offer(new Message(record));
// 确保每个用户只有一个处理线程
userExecutors.submit(() -> processUserMessages(userId));
}
private void processUserMessages(String userId) {
LinkedBlockingQueue<Message> queue = userMessageQueues.get(userId);
if (queue == null) return;
// 顺序处理该用户的消息
while (!queue.isEmpty()) {
Message message = queue.poll();
if (message != null) {
processMessage(message);
}
}
}
// 方案2:使用Kafka分区保证顺序
@KafkaListener(topics = "order-topic",
containerFactory = "kafkaListenerContainerFactory")
public void consumeWithPartition(ConsumerRecord<String, String> record) {
// Kafka保证同一分区内的消息顺序
// 将同一用户的消息发送到同一分区
processMessage(record);
}
// 生产者配置:按用户ID分区
public void sendOrderedMessage(String userId, Order order) {
// 使用userId作为key,保证同一用户的消息进入同一分区
kafkaTemplate.send("order-topic", userId, order);
}
// 方案3:使用内存队列保序
private final Map<String, MessageHandler> userHandlers = new ConcurrentHashMap<>();
public void consumeWithMemoryQueue(ConsumerRecord<String, String> record) {
String userId = extractUserId(record.key());
MessageHandler handler = userHandlers.computeIfAbsent(userId, id -> {
MessageHandler h = new MessageHandler(id);
h.start(); // 启动单线程处理器
return h;
});
handler.submit(record);
}
// 每个用户一个单线程处理器
private class MessageHandler {
private final String userId;
private final LinkedBlockingQueue<ConsumerRecord<String, String>> queue;
private final Thread processor;
MessageHandler(String userId) {
this.userId = userId;
this.queue = new LinkedBlockingQueue<>();
this.processor = new Thread(this::run);
}
void start() {
processor.start();
}
void submit(ConsumerRecord<String, String> record) {
queue.offer(record);
}
void run() {
while (!Thread.interrupted()) {
try {
ConsumerRecord<String, String> record = queue.take();
processMessage(record);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
}
}经验总结:
- 多线程消费时要考虑消息顺序
- 使用Kafka分区机制保证顺序
- 按用户ID分片处理,保证单用户顺序
- 使用内存队列缓存和排序消息
案例5:ThreadLocal内存泄漏
问题描述: Web应用部署在Tomcat中,热部署后出现内存溢出,分析发现ThreadLocal未清理导致。
原始代码:
public class UserContextHolder {
// 问题:没有正确清理
private static final ThreadLocal<User> userContext = new ThreadLocal<>();
public static void setUser(User user) {
userContext.set(user);
}
public static User getUser() {
return userContext.get();
}
}
// Controller使用
@RestController
public class UserController {
@GetMapping("/user")
public User getCurrentUser() {
User user = userService.getCurrentUser();
UserContextHolder.setUser(user); // 设置
return user;
}
}问题分析:
- ThreadLocal的值存储在Thread的ThreadLocalMap中
- 线程池复用线程,导致旧值一直存在
- Tomcat热部署时ClassLoader更换,旧值无法GC
- 没有在使用后及时清理
修复方案:
public class UserContextHolder {
private static final ThreadLocal<User> userContext = new ThreadLocal<>();
public static void setUser(User user) {
userContext.set(user);
}
public static User getUser() {
return userContext.get();
}
// 关键:提供清理方法
public static void clear() {
userContext.remove();
}
}
// 使用Interceptor自动清理
@Component
public class UserContextInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response,
Object handler) {
// 清理之前的值
UserContextHolder.clear();
return true;
}
@Override
public void afterCompletion(HttpServletRequest request,
HttpServletResponse response,
Object handler,
Exception ex) {
// 请求结束后清理
UserContextHolder.clear();
}
}
// 或者使用Filter
public class ThreadLocalCleanupFilter implements Filter {
@Override
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
try {
chain.doFilter(request, response);
} finally {
// 确保清理所有ThreadLocal
UserContextHolder.clear();
OtherContextHolder.clear();
// ...
}
}
}
// 方案2:使用InheritableThreadLocal的注意事项
public class InheritableUserContextHolder {
// InheritableThreadLocal会继承父线程的值
// 子线程可能看到父线程的旧值
private static final InheritableThreadLocal<User> userContext =
new InheritableThreadLocal<>();
public static void setUser(User user) {
userContext.set(user);
}
public static User getUser() {
return userContext.get();
}
public static void clear() {
userContext.remove();
}
}
// 方案3:使用TransmittableThreadLocal(阿里开源)
public class TransmittableUserContextHolder {
// 配合线程池使用,正确传递ThreadLocal
private static final TransmittableThreadLocal<User> userContext =
new TransmittableThreadLocal<>();
public static void setUser(User user) {
userContext.set(user);
}
public static User getUser() {
return userContext.get();
}
public static void clear() {
userContext.remove();
}
}
// 使用TtlExecutors包装线程池
ExecutorService executorService = TtlExecutors.getTtlExecutorService(
Executors.newFixedThreadPool(10)
);经验总结:
- ThreadLocal必须在使用后及时remove()
- 使用拦截器或过滤器保证清理
- 配合线程池使用时注意值传递问题
- 考虑使用TransmittableThreadLocal处理父子线程传递
- 避免在static变量中长期持有ThreadLocal
16.3 诊断工具与实践
工具1:JCStress框架
JCStress是OpenJDK提供的并发测试框架,用于验证内存模型行为。
@JCStressTest
@Outcome(id = "0, 0", expect = Expect.ACCEPTABLE)
@Outcome(id = "1, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "1, 0", expect = Expect.FORBIDDEN)
@State
public class MemoryOrderingTest {
int x, y;
@Actor
public void actor1() {
x = 1;
y = 2;
}
@Actor
public void actor2(II_Result r) {
r.r1 = y;
r.r2 = x;
}
}
// 运行测试
// java -jar jcstress.jar -t MemoryOrderingTest工具2:async-profiler
用于分析CPU热点和锁竞争。
# 启动async-profiler
./profiler.sh -d 60 -f profile.html <pid>
# 分析结果
# - 查看热点方法
# - 查看锁竞争情况
# - 查看内存分配工具3:JMH基准测试
用于性能测试和对比。
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 3)
@Measurement(iterations = 5)
@Fork(1)
public class SyncBenchmark {
private int counter = 0;
@Benchmark
public synchronized int synchronizedIncrement() {
return counter++;
}
@Benchmark
public int atomicIncrement() {
return atomicCounter.incrementAndGet();
}
private AtomicInteger atomicCounter = new AtomicInteger(0);
}16.4 性能调优指南
指南1:减少volatile使用
// 优化前
while (running) { // 每次循环都是volatile读
doWork();
}
// 优化后:本地缓存
boolean local = running;
while (local) {
doWork();
local = running; // 定期刷新
}指南2:使用缓存行填充
// 伪共享示例
public class FalseSharing {
public volatile long value1;
public volatile long value2; // 可能在同一缓存行
}
// 解决方案
public class PaddedValues {
public volatile long value1;
private long p1, p2, p3, p4, p5, p6, p7; // 填充
public volatile long value2;
}17. HotSpot VM源码深度解读
17.1 OrderAccess类详解
OrderAccess是HotSpot JVM中实现内存屏障的核心类,位于hotspot/share/runtime/orderAccess.hpp。
OrderAccess类定义:
// hotspot/share/runtime/orderAccess.hpp
class OrderAccess : public AllStatic {
public:
// ==================== 屏障方法 ====================
// LoadLoad屏障:确保Load1在Load2之前完成
static inline void loadload() { acquire(); }
// StoreStore屏障:确保Store1在Store2之前完成
static inline void storestore() { release(); }
// LoadStore屏障:确保Load1在Store2之前完成
static inline void loadstore() { acquire(); }
// StoreLoad屏障:确保Store1在Load2之前完成(最昂贵)
static inline void storeload() { fence(); }
// ==================== 获取/释放语义 ====================
// 获取语义(Acquire Semantics)
// 用于读操作,确保读操作不会被重排到后面
static inline void acquire() {
// x86: 无操作(TSO保证)
// ARM: dmb ishld
// POWER: lwsync
}
// 释放语义(Release Semantics)
// 用于写操作,确保写操作不会被重排到前面
static inline void release() {
// x86: 无操作(TSO保证)
// ARM: dmb ish
// POWER: lwsync
}
// 完全内存屏障
static inline void fence() {
// x86: mfence 或 lock addl
// ARM: dmb ish
// POWER: sync
}
// ==================== volatile访问 ====================
// volatile读模板
template<typename T> static inline T volatile_load(const volatile T* p) {
// 插入LoadLoad和LoadStore屏障
acquire();
T value = *p;
return value;
}
// volatile写模板
template<typename T> static inline void volatile_store(volatile T* p, T v) {
// 插入StoreStore和StoreLoad屏障
release();
*p = v;
fence(); // StoreLoad屏障
}
};17.2 x86平台的具体实现
x86的内存屏障实现较为简单,因为TSO已经保证了很多顺序。
x86实现(hotspot/cpu/x86/orderAccess_x86.hpp):
// hotspot/cpu/x86/orderAccess_x86.hpp
inline void OrderAccess::fence() {
// 方法1: 使用mfence指令
// __asm__ volatile ("mfence" ::: "memory");
// 方法2: 使用lock前缀(HotSpot实际使用)
// lock addl $0x0, (%%rsp)
__asm__ volatile ("lock; addl $0,0(%%rsp)" ::: "memory", "cc");
}
inline void OrderAccess::acquire() {
// x86不需要显式屏障
// TSO保证Load-Load和Load-Store顺序
}
inline void OrderAccess::release() {
// x86不需要显式屏障
// TSO保证Store-Store顺序
}为什么使用lock addl而不是mfence?
示例性能对比(周期数,具体数值受微架构、微码、JDK build 和测试方法影响):
| 微架构 | mfence | lock addl |
|---|---|---|
| x86 Skylake | 约 150 | 约 50 |
| x86 Haswell | 约 100 | 约 35 |
| x86 Ivy Bridge | 约 80 | 约 30 |
在很多 x86 平台上,lock addl 的成本低于 mfence,因此 HotSpot 历史实现中经常选择带 lock 前缀的伪操作来实现所需屏障语义。但这类数字不能脱离具体 CPU、JDK 版本和基准方法直接用于容量规划。
17.3 ARM平台的具体实现
ARM使用弱内存序模型,需要显式屏障指令。
ARM实现(hotspot/cpu/arm/orderAccess_arm.hpp):
// hotspot/cpu/arm/orderAccess_arm.hpp
inline void OrderAccess::fence() {
// DMB SY - 全屏障
__asm__ volatile ("dmb sy" ::: "memory");
}
inline void OrderAccess::acquire() {
// DMB ISHLD - LoadLoad + LoadStore
__asm__ volatile ("dmb ishld" ::: "memory");
}
inline void OrderAccess::release() {
// DMB ISH - StoreStore + LoadStore
__asm__ volatile ("dmb ish" ::: "memory");
}
// ARM64实现
inline void OrderAccess::fence() {
// DMB ISH - 内部共享域屏障
__asm__ volatile ("dmb ish" ::: "memory");
}17.4 volatile字段访问的模板代码生成
HotSpot的模板解释器负责生成volatile访问的机器码。
volatile读的代码生成:
// hotspot/cpu/x86/templateTable_x86.cpp
void TemplateTable::getfield_or_static(int byte_no, bool is_static) {
// ... 准备工作 ...
if (is_volatile) {
// x86: volatile读不需要显式屏障
// TSO保证Load的顺序
// 执行实际读取
switch (bytecode()) {
case Bytecodes::_getfield:
__ movl(rax, Address(obj, off));
break;
case Bytecodes::_lgetfield:
__ movq(rax, Address(obj, off));
break;
// ... 其他类型
}
}
}volatile写的代码生成:
// hotspot/cpu/x86/templateTable_x86.cpp
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
// ... 准备工作 ...
if (is_volatile) {
// StoreStore屏障
// x86: 不需要显式屏障(TSO保证)
// 执行实际写入
switch (bytecode()) {
case Bytecodes::_putfield:
__ movl(Address(obj, off), val);
break;
case Bytecodes::_lputfield:
__ movq(Address(obj, off), val);
break;
}
// StoreLoad屏障 - 最关键!
// 使用lock addl作为轻量级屏障
__ lock();
__ addl(Address(rsp, 0), 0);
}
}17.5 synchronized的底层实现
MonitorEnter(加锁)的内存屏障:
// hotspot/share/runtime/synchronizer.cpp
void ObjectSynchronizer::enter(Handle obj, ...) {
// 获取对象头
markWord mark = obj->mark();
// 尝试快速加锁。现代 JDK 重点关注轻量级锁路径;偏向锁已是历史机制。
if (mark.is_unlocked()) {
// CAS设置锁状态
markWord displaced = obj->cas_set_mark(lock, mark);
if (displaced == mark) {
// 成功获取锁
// 插入获取屏障
OrderAccess::acquire();
return;
}
}
// 膨胀到重量级锁
// 使用操作系统互斥量
// 操作系统内部也提供内存屏障
}MonitorExit(解锁)的内存屏障:
void ObjectSynchronizer::exit(Handle obj, ...) {
// 插入释放屏障
OrderAccess::release();
// 解锁操作
markWord mark = obj->mark();
if (mark.is_unlocked()) {
// 快速解锁
obj->set_mark(mark.unlock());
// StoreLoad屏障
OrderAccess::storeload();
}
}17.6 CAS操作的内存语义
Unsafe类提供的CAS操作底层使用lock cmpxchg指令。
x86 CAS实现:
// hotspot/cpu/x86/assembler_x86.hpp
class Assembler {
public:
// CAS操作:lock cmpxchg
void cmpxchg(Register reg, Address adr) {
// lock前缀提供原子性和内存屏障
lock();
emit_int8((unsigned char)0x0F);
emit_int8((unsigned char)0xB1);
emit_operand(reg, adr);
}
};
// hotspot/cpu/x86/atomic_x86.hpp
jint Atomic::cmpxchg(jint exchange_value,
volatile jint* dest,
jint compare_value) {
jint prev;
__asm__ volatile ("lock cmpxchgl %1,(%3)"
: "=a" (prev)
: "r" (exchange_value), "a" (compare_value), "r" (dest)
: "memory", "cc");
return prev;
}lock前缀的内存屏障语义:
lock cmpxchg 提供:
1. 原子性保证
2. 完全的内存屏障(StoreLoad + StoreStore + LoadLoad + LoadStore)
3. 使所有Store Buffer刷新到缓存
4. 使所有处理器的缓存无效17.7 Final字段的内存屏障处理
final字段的特殊处理在putfield字节码中。
// hotspot/share/interpreter/bytecodeInterpreter.cpp
CASE(_putfield): {
// ... 准备工作 ...
if (is_final_field) {
// StoreStore屏障
// 确保final字段的写入在构造函数结束前完成
OrderAccess::storestore();
}
// 设置字段值
*field_addr = value;
if (is_volatile) {
OrderAccess::fence();
}
}17.8 JIT编译器的屏障优化
JIT编译器可以进行屏障优化。
冗余屏障消除:
// 源代码
volatile int v;
int x;
void example() {
x = 1; // (1)
v = 2; // (2) volatile写
v = 3; // (3) volatile写
int r = x; // (4)
}屏障优化可以理解为两步:
- 未优化时,
v = 2和v = 3两次 volatile 写都会引入屏障;其中相邻的 StoreStore 屏障可能是冗余的。 - 优化后,编译器在不破坏 JMM 语义的前提下保留必要的发布边界,合并或删除不会改变可见性结果的冗余屏障。
一种等价的抽象顺序是:x = 1,插入必要的 StoreStore 屏障,执行两次 volatile 写,保留最后一次 volatile 写之后的 StoreLoad 屏障,再执行后续普通读。实际机器码是否采用这种形态,仍取决于平台和编译器阶段。
18. 性能优化与最佳实践
18.1 并发编程的核心原则
原则1:优先使用不可变对象
// 推荐:不可变对象天然线程安全
public final class ImmutableConfig {
private final String host;
private final int port;
private final Duration timeout;
public ImmutableConfig(String host, int port, Duration timeout) {
this.host = Objects.requireNonNull(host);
this.port = port;
this.timeout = Objects.requireNonNull(timeout);
}
// 只有getter,没有setter
public String getHost() { return host; }
public int getPort() { return port; }
public Duration getTimeout() { return timeout; }
}
// 不可变对象可以安全共享
public class ConfigHolder {
// volatile保证引用的可见性
private volatile ImmutableConfig config = DEFAULT_CONFIG;
// 读操作无锁
public ImmutableConfig getConfig() {
return config;
}
// 写操作原子替换
public void updateConfig(ImmutableConfig newConfig) {
config = newConfig; // volatile写
}
}原则2:Happens-Before是基石
// 理解并正确使用happens-before关系
public class SafePublication {
// 使用volatile保证happens-before
private volatile Data data;
public void publish(Data newData) {
// volatile写保证之前的操作都完成
data = newData;
}
public Data get() {
// volatile读保证能看到完整的写入
return data;
}
}原则3:volatile的正确使用场景
// 正确使用1:状态标志
public class Server {
private volatile boolean running = true;
public void shutdown() {
running = false; // volatile写
}
public void doWork() {
while (running) { // volatile读
process();
}
}
}
// 正确使用2:单次写入的配置
public class Configuration {
private volatile String configValue;
// 只在初始化时写入一次
public void initialize(String value) {
configValue = value;
}
// 多次读取
public String getConfig() {
return configValue;
}
}
// 错误使用:计数器
public class BadCounter {
private volatile int count = 0; // 错误!
public void increment() {
count++; // 非原子操作
}
}
// 正确替代
public class GoodCounter {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // CAS原子操作
}
}原则4:减少锁的使用
// 方案1:使用并发集合代替显式锁
public class UserCache {
// 使用ConcurrentHashMap代替HashMap+锁
private final ConcurrentHashMap<String, User> cache =
new ConcurrentHashMap<>();
public User get(String key) {
return cache.get(key);
}
public void put(String key, User user) {
cache.put(key, user);
}
// 原子计算
public User computeIfAbsent(String key, Function<String, User> f) {
return cache.computeIfAbsent(key, f);
}
}
// 方案2:使用读写锁
public class CacheWithReadWriteLock {
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final Map<String, Object> cache = new HashMap<>();
public Object get(String key) {
lock.readLock().lock();
try {
return cache.get(key);
} finally {
lock.readLock().unlock();
}
}
public void put(String key, Object value) {
lock.writeLock().lock();
try {
cache.put(key, value);
} finally {
lock.writeLock().unlock();
}
}
}
// 方案3:使用StampedLock(Java 8+)
public class Point {
private final StampedLock lock = new StampedLock();
private double x, y;
public void move(double deltaX, double deltaY) {
long stamp = lock.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
lock.unlockWrite(stamp);
}
}
// 乐观读
public double distanceFromOrigin() {
long stamp = lock.tryOptimisticRead();
double currentX = x;
double currentY = y;
if (!lock.validate(stamp)) {
// 乐观读失败,转为普通读锁
stamp = lock.readLock();
try {
currentX = x;
currentY = y;
} finally {
lock.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
}18.2 并发编程检查清单
基础检查项:
- 共享变量访问:所有共享变量是否都有适当的同步机制?
- 复合操作:i++、先读后写等操作是否使用了原子类?
- 对象发布:对象是否在构造函数完成后才发布到共享区域?
- this逸出:构造函数中是否避免了this引用逸出?
- final字段:是否充分使用了final关键字?
高级检查项:
- happens-before链:是否能完整推导操作的happens-before关系?
- 伪共享:高并发场景下是否考虑了缓存行对齐?
- 锁粒度:锁的范围是否足够小?
- 锁顺序:是否存在死锁风险?
- 线程安全:工具类是否为线程安全的?
企业级并发治理检查项:
- 事实源归属:核心状态到底以 JVM 内存、数据库、缓存、消息队列还是外部系统为准?
- 不变量保护点:余额不能为负、库存不能超卖、订单状态不能回退等约束是否落在事实源层?
- 数据库原子性:读-校验-写是否合并为条件更新、版本号乐观锁、行级锁或本地事务?
- 乐观锁边界:版本号冲突是否有最大重试次数、指数退避、冲突指标和降级策略?
- 幂等设计:请求、消息、回调、补偿任务是否都有业务幂等键和唯一约束?
- 缓存一致性:缓存是否只作为派生视图?写路径是否避免把缓存当成最终事实源?
- 消息一致性:本地事务和消息发送之间是否使用 Outbox、事务消息或可恢复补偿?
- 顺序保证:需要按账户、订单、商品维度顺序处理的消息是否按聚合根分区?
- 服务治理:热点资源是否有按业务 Key 的限流、熔断、隔离、排队和降级策略?
- 可观测性:锁等待、乐观锁冲突、重试次数、幂等命中、热点 Key、补偿失败是否有指标和告警?
性能检查项:
- volatile优化:循环中的volatile访问是否缓存到本地变量?
- 缓存行填充:@Contended或手动填充是否适当?
- 锁竞争:是否存在高竞争的锁?
- 原子类选择:是否选择了合适的原子类?
- 线程池配置:线程池大小是否合理?
JVM调优检查项:
- 锁路径版本:目标 JDK 是否仍包含偏向锁?JDK 18+ 已移除,应重点检查轻量级锁、锁膨胀和 JFR monitor 事件。
- Contended注解:JDK 9+是否启用了-XX:-RestrictContended?
- 内存模型:是否理解了底层硬件的内存模型?
- GC影响:并发操作是否受到GC停顿影响?
18.3 常见误区与陷阱
误区1:过度使用volatile
// 误区:认为volatile可以保证原子性
public class VolatileCounter {
private volatile int count = 0;
public void increment() {
count++; // 错误!非原子操作
}
}
// 正确:使用原子类
public class AtomicCounter {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 正确,原子操作
}
}误区2:忽视指令重排序
// 误区:认为代码顺序就是执行顺序
public class ReorderingDemo {
int x = 0, y = 0;
int a = 0, b = 0;
void thread1() {
x = 1; // (1)
a = y; // (2) 可能被重排序到(1)之前
}
void thread2() {
y = 1; // (3)
b = x; // (4) 可能被重排序到(3)之前
}
// 可能的结果:a=0, b=0(尽管看起来不可能)
}
// 正确:使用volatile或synchronized
public class FixedReordering {
volatile int x = 0, y = 0;
int a = 0, b = 0;
void thread1() {
x = 1; // (1) volatile写
a = y; // (2) 不会被重排序到(1)之前
}
void thread2() {
y = 1; // (3) volatile写
b = x; // (4) 不会被重排序到(3)之前
}
}误区3:错误的DCL实现
// 误区:JDK 5之前的DCL
public class BrokenSingleton {
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // 危险!
}
}
}
return instance;
}
}
// 正确:使用volatile
public class SafeSingleton {
private static volatile Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
// 最佳:使用静态内部类(延迟加载,线程安全)
public class BestSingleton {
private BestSingleton() {}
private static class Holder {
static final BestSingleton INSTANCE = new BestSingleton();
}
public static BestSingleton getInstance() {
return Holder.INSTANCE;
}
}18.4 学习资源与进阶路径
官方文档:
-
JSR-133规范:https://www.cs.umd.edu/~pugh/java/memoryModel/
- 官方内存模型规范
- 最权威的定义和说明
-
Java Language Specification, Chapter 17
- Oracle官方语言规范
- 线程和锁的语义
-
OpenJDK HotSpot VM源码
- github.com/openjdk/jdk
- 了解底层实现细节
推荐书籍:
| 书名 | 作者 | 重点章节 |
|---|---|---|
| 《Java并发编程实战》 | Brian Goetz | 第16章:Java内存模型 |
| 《深入理解Java虚拟机》 | 周志明 | 第12章:Java内存模型与线程 |
| 《Java并发编程的艺术》 | 方腾飞 | 第3章:Java内存模型 |
| 《并发编程:Java理论与实践》 | Doug Lea | 全书 |
在线资源:
-
shipilev.net:Aleksey Shipilev的JMM深入文章
- 最权威的JMM实践指南
- 大量测试代码和性能数据
-
JCStress项目:OpenJDK并发测试框架
- github.com/openjdk/jcstress
- 学习如何测试内存模型
-
Mechanical Sympathy:
- mechanical-sympathy.blogspot.com
- Martin Thompson的性能博客
进阶路径:
- 基础:理解 happens-before 关系,掌握
volatile和synchronized,熟悉java.util.concurrent包。 - 进阶:理解内存屏障,掌握 CAS 和原子类,理解伪共享和缓存行。
- 高级:阅读 HotSpot 源码,理解不同 CPU 架构的内存模型,能够进行 JVM 调优。
- 专家:参与 OpenJDK 开发,设计并发框架,使用形式化方法验证关键并发算法。
19. 总结与展望
19.1 核心知识点回顾
本文系统地介绍了Java内存模型的各个方面:
基础概念:
- happens-before关系的数学定义和推导
- volatile的可见性和禁止重排序语义
- final字段的安全发布保证
- synchronized的互斥性和可见性保证
底层机制:
- 内存屏障的四种类型和硬件实现
- x86/ARM/POWER等不同架构的差异
- 缓存一致性协议(MESI/MESIF/MOESI)
- Store Buffer和Invalidate Queue的影响
实践应用:
- DCL问题的分析和解决
- 伪共享的识别和优化
- 生产环境并发Bug的案例分析
- HotSpot VM的源码实现
19.2 Java内存模型的演进
过去(Java 5之前):
- 内存模型存在严重缺陷
- DCL问题广泛存在
- 并发编程困难重重
现在(Java 5-17):
- JSR-133提供了坚实的理论基础
- java.util.concurrent简化了并发编程
- JMM在实践中被广泛验证
现代演进(Java 21+):
- Project Loom:虚拟线程已在 JDK 21 GA,结构化并发仍需按目标 JDK 的 Preview 状态启用。
- Project Valhalla:值类和值对象仍处于 JEP 401 等设计/预览候选阶段,不能当作当前 GA 语法。
- Project Panama:原生接口和内存访问
- 更强大的并发原语和内存模型扩展
19.3 对开发者的建议
日常开发:
- 优先使用java.util.concurrent中的工具
- 理解并正确使用happens-before关系
- 避免自己实现复杂的同步机制
- 充分测试并发代码
性能优化:
- 使用JMH进行基准测试
- 使用async-profiler分析热点
- 理解底层硬件特性
- 避免过早优化
持续学习:
- 关注OpenJDK的更新
- 阅读相关论文和源码
- 参与社区讨论
- 实践并总结经验
参考文献
- Java Language Specification, Chapter 17: Threads and Locks. Oracle, 2024.
- JSR-133: Java Memory Model and Thread Specification. jcp.org, 2004.
- Manson, J., Pugh, W., & Adve, S. V. (2005). The Java memory model. ACM SIGPLAN Notices, 40(1), 378-391.
- Pugh, W. (2004). The Java memory model. Doctoral dissertation, University of Maryland.
- OpenJDK HotSpot VM Source. github.com/openjdk/jdk.
- Doug Lea. Concurrent Programming in Java: Design Principles and Patterns. Addison-Wesley, 1999.
- Goetz, B., et al. Java Concurrency in Practice. Addison-Wesley, 2006.
- Aleksey Shipilev. Java Memory Model Pragmatics. shipilev.net, 2024.
- 周志明. 深入理解Java虚拟机:JVM高级特性与最佳实践. 机械工业出版社, 2019.
- 方腾飞, 魏鹏, 程晓明. Java并发编程的艺术. 机械工业出版社, 2015.
- David Dice, et al. JSR-133 FAQ. cs.umd.edu, 2004.
- Intel 64 and IA-32 Architectures Software Developer’s Manual. Intel, 2024.
- ARM Architecture Reference Manual for ARMv8-A. ARM, 2024.
- Martin Thompson. Mechanical Sympathy. mechanical-sympathy.blogspot.com.
- Nitsan Wakart. JMM Pragmatics. psycho-lob-saw.blogspot.com.
Series context
你正在阅读:Java 核心技术深度解析
当前为第 1 / 8 篇。阅读进度只写入此浏览器的 localStorage,用于回到系列页时定位继续阅读入口。
Series Path
当前系列章节
点击章节会在此浏览器记录本地阅读进度;刷新后可继续阅读。
- Java 内存模型深度解析:从 happens-before 到安全发布 理解 JMM、volatile、final 字段、安全发布、乐观锁、锁语义和现代 ConcurrentHashMap 的工程边界。
- 现代 Java 垃圾回收:生产判断、证据采集与调优路径 以生产症状、GC logs、JFR、容器内存和回滚策略为主线,建立 G1、ZGC、Shenandoah、Parallel、Serial 的证据化选型与调优方法。
- 虚拟线程在生产系统中的并发治理 从吞吐、阻塞、资源池、下游保护、pinning、结构化并发、可观测性与迁移边界理解 Loom 的生产治理方法。
- Valhalla 与 Panama:Java 未来内存与外部接口模型 区分已交付的 FFM API、仍在演进的 Valhalla 值类型与泛型专门化,并从对象布局、内存局部性、native interop、安全边界和迁移治理视角建立生产判断。
- Java 云原生生产运行指南:镜像、容器、Kubernetes、Native Image 与交付治理 从 JVM 容器资源、镜像策略、Kubernetes 运行边界、Native Image、Serverless、供应链安全到故障诊断,建立 Java 云原生生产判断路径。
- Spring AI 与 LangChain4j:企业级 AI 应用边界 区分 Spring AI 官方 API、LangChain4j 抽象、示例封装和企业级 AI 运行治理。
- JIT 与 AOT:从症状、诊断到优化决策 面向 HotSpot、Graal、Native Image 与 PGO 的性能诊断和决策路径。
- Java 技术生态展望:JDK 25 LTS、JDK 26 GA 与 JDK 27 EA 以企业架构视角判断 Java 未来十年的版本策略、路线图状态、生态边界、云原生、AI 与性能演进。
Reading path
继续沿这条专题路径阅读
按推荐顺序继续阅读 Java 相关内容,而不是只看同专题的随机文章。
Next step
继续深入这个专题
如果这篇内容对你有帮助,下一步可以回到专题页继续系统阅读,或者订阅后续更新。
正在加载评论...
评论与讨论
使用 GitHub 账号登录参与讨论,评论将同步至 GitHub Discussions