Article
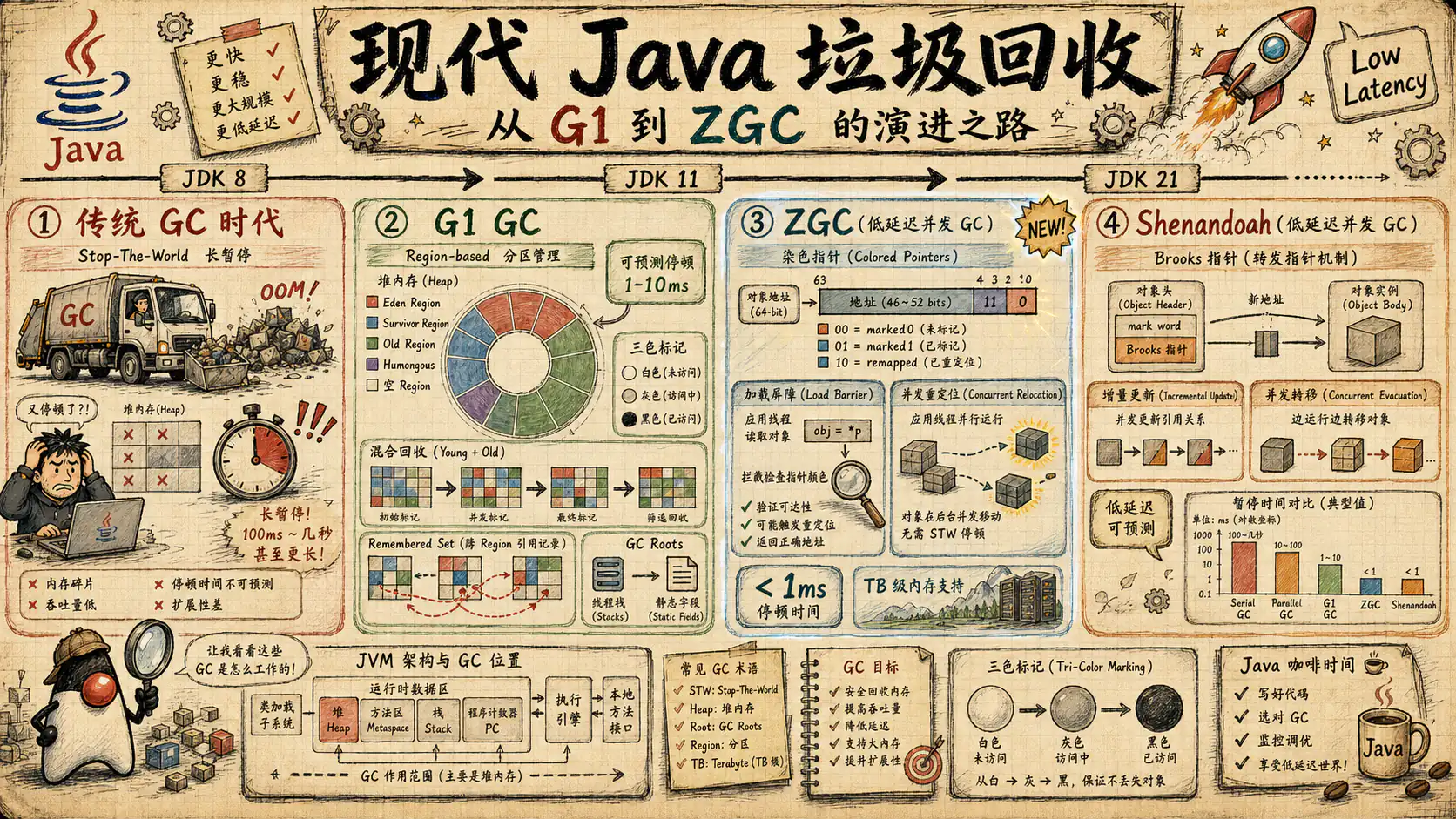
现代 Java 垃圾回收:生产判断、证据采集与调优路径
以生产症状、GC logs、JFR、容器内存和回滚策略为主线,建立 G1、ZGC、Shenandoah、Parallel、Serial 的证据化选型与调优方法。
现代 Java 垃圾回收:生产判断、证据采集与调优路径
核验与阅读口径:本文核验日期为 2026-05-15。涉及 JDK/JEP、collector 状态、默认行为、移除行为和 GA/LTS/EA 口径时,以 OpenJDK JEP、OpenJDK 项目页、JDK 发行说明或供应商正式发布说明为优先来源。文中关于 G1、ZGC、Shenandoah、Parallel GC、Serial GC 的性能和行为描述,都只作为工程判断框架,不作为跨硬件、跨业务、跨 JDK build 的固定结论。任何“低延迟”“吞吐更高”“更适合大堆”之类的表述,都应在自身工作负载、CPU 配额、内存预算、容器限制和 SLO 下重新验证。
摘要
GC 在生产环境里不是一组 JVM 参数,也不是一张“某个收集器适合某类业务”的速查表。真正需要架构师解决的问题是:当 Java 服务出现吞吐下降、延迟抖动、CPU 升高、RSS 持续增长、容器 OOMKill、Young GC 过密、Mixed GC 回收收益变差、Full GC 突增,或者压测时 p99 和 p999 明显失控时,如何快速判断 GC 是否真的是根因,还是只是在给更深层的问题背锅。
很多团队在 GC 问题上长期停留在 cargo-cult 阶段。表现方式通常有几种:第一,看到延迟高就把 MaxGCPauseMillis 继续调小;第二,看到 OOM 就直接把堆扩大;第三,听说 ZGC 停顿短,就在所有服务里统一切换;第四,在容器中把 -Xmx 配到接近 memory limit,却忽略 Metaspace、direct memory、thread stack、code cache、native memory 和 GC 元数据;第五,把所有慢请求都归因到 GC,却从未去比对 safepoint、锁竞争、线程池排队、数据库慢查询和下游超时。
这篇文章的目标不是讲“某个算法有多先进”,而是重建一条生产可执行的判断链路:先从症状建立诊断入口,再用 GC logs、JFR、堆/非堆/容器内存证据判断 GC 是否是根因,再根据服务的吞吐目标、尾延迟目标、对象生命周期、堆规模、CPU 预算和回滚要求选择合适的 collector family,最后通过小步假设、对照压测、灰度发布和持续观测完成调优,而不是靠网上复制来的 JVM flags 解决一切。
读完本文后,读者应该能建立几个关键能力。第一,知道 GC 的本质是生产工程契约,而不是 Java 基础课上的“自动内存管理”。第二,知道哪些症状优先怀疑 GC,哪些症状更可能来自业务对象生命周期、线程池、缓存、序列化、网络或容器内存预算。第三,能从统一 GC 日志和 JFR 里读出暂停阶段、分配速率、晋升压力、并发阶段推进情况、humongous allocation、promotion failure、allocation stall 和 safepoint 关联。第四,知道 heap、Metaspace、direct memory、thread stack、code cache、native memory 与 cgroup limit 之间的预算关系。第五,知道 G1、ZGC、Shenandoah、Parallel GC、Serial GC 的工作边界与误区,并把 collector 选型与发布、回滚、观测和团队可操作性联系起来。
全文主线遵循一个非常明确的生产阅读路径:GC 是工程契约;症状如何转成诊断入口;如何用日志和 JFR 获取证据;堆与容器内存如何共同决定故障边界;collector families 的适用工作负载和版本边界是什么;如何建立调优工作流;不同 collector 的常见误用有哪些;发生问题后 runbook 应该如何执行;最后如何识别那些最常见、也最昂贵的误判。
如果进一步抽象,本文其实围绕三个问题展开。第一,GC 在生产里什么时候是真问题,什么时候只是暴露其他问题的温度计。第二,即便确定 GC 参与了问题,应该把视线放在 collector、对象生命周期、内存账本、容器预算还是团队观测缺口上。第三,当需要做出变更时,如何让 collector 选择和参数调整具备可验证性,而不是一次次变成“这次好像好了一点”的经验叙事。这三个问题回答清楚之后,GC 才真正从一个高门槛 JVM 话题,变成可以被架构师、平台团队和应用团队共同治理的生产能力。
从读者角色看,本文既不是 JVM 内核源码导读,也不是只面向值班 SRE 的 runbook 速记。它的目标读者是需要在技术评审、故障复盘、平台规划和运行治理之间来回切换的架构师与高级工程师。因此文章刻意减少了长代码载体,强化了症状、证据、边界、误判和回滚语言,因为这些内容才是生产现场真正需要被反复复用的部分。懂算法原理当然重要,但在生产上更稀缺的能力,是把算法原理转译成可执行判断。
1. GC 是生产工程契约,而不是参数清单
如果把 GC 只看成 JVM 的一个子系统,团队很容易落入“性能问题交给 JVM 工程师解决”的分工陷阱。实际上,GC 之所以会在生产中变成事故源,往往不是因为 collector 内部某个算法突然变坏,而是因为系统边界上已经存在未被治理的张力:业务侧不断追求更高吞吐,平台侧要求更高容器密度,应用侧通过缓存和批量化换取局部性能,运维侧又把日志、JFR 和堆证据保留得过短。等这些张力在高峰时刻同时出现,GC 就会成为第一个被看到的放大器。理解这一点非常关键,因为它决定了架构师是在做“JVM 参数优化”,还是在做“系统运行契约修复”。
从组织协作角度看,GC 还是一个非常典型的责任交叉区。应用开发往往决定对象生命周期、集合体量、缓冲区大小、序列化方式和缓存淘汰策略;平台团队决定容器 limit、节点密度、镜像基线、JDK 版本和诊断开关;SRE 决定告警口径、取证窗口与灰度回滚流程。如果这三方没有共同语言,GC 相关故障复盘就会变成彼此甩锅:开发说 collector 不行,平台说应用太占内存,SRE 说大家都没留证据。把 GC 定义为契约,实际上是在强制各方承认:只有把对象生命周期、资源预算和观测面写成可执行约束,collector 的行为才能被正确解释。
还有一个经常被忽略的现实问题是时间尺度。很多 GC 事故并不是部署后立刻出现,而是在数小时、数天甚至更长周期后逐步累积。这意味着“发布后一小时没问题”并不能证明 collector 选择正确,也不能证明内存预算正确。某些缓存膨胀、classloader retention、native allocator 累积、批处理窗口叠加、租户数据分布变化,都可能在稳态运行一段时间后改变分配率和存活率曲线。架构师如果只用短窗口压测结论来代表长期运行状态,就会高估 collector 本身、低估运行周期内的数据形态变化。
因此,进入 GC 讨论之前,团队最好先统一几个最基本的问题:我们要保护的是哪类 SLO;在什么时间尺度上判断 collector 健康;哪类实例允许更激进的实验;哪类实例必须优先保守;哪些指标属于 collector 本身,哪些指标属于系统整体;如果 collector 变更导致业务回归,谁负责在多快时间内回滚。很多文章喜欢从算法开始,但生产上的正确起点其实是治理问题。算法解释是必要的,治理边界更必要。
1.1 先定义你到底在优化什么
GC 调优的第一步不是看参数,而是先把优化目标说清楚。很多服务口头上说“要优化 GC”,实际却没有明确是在优化吞吐、平均延迟、尾延迟、内存利用率、CPU 成本、容器密度、发布风险,还是某一种具体故障。没有目标,就没有正确的 collector 选择,也没有办法判断一次变更是进步还是退步。
从生产角度看,GC 涉及至少六个互相拉扯的目标。第一是吞吐,也就是业务线程能拿到多少 CPU 做真正的应用工作。第二是延迟,尤其是 p99、p999 这类尾延迟,因为 GC 往往不会把所有请求都拖慢,但会把一小部分请求拖到 SLA 之外。第三是内存占用,包括堆本身、额外元数据、并发回收的缓冲区、Remembered Set、转发表、屏障带来的额外结构等。第四是分配效率,也就是单位时间内系统能承受多大的对象创建速率。第五是可操作性,也就是团队是否真的能读懂该 collector 的证据面。第六是发布与回滚成本,因为 collector 切换属于基础行为变更,远比改一个业务参数危险。
如果你面对的是交易网关、实时风控、撮合、实时推荐、低延迟 RPC 服务,真正要看的是尾延迟和抖动,而不是单次 benchmark 的平均耗时。相反,如果你面对的是批处理、离线 ETL、索引构建、日志聚合、定时报表,业务也许可以接受秒级停顿,但更在意总处理时间和硬件成本。再比如某些多租户容器服务,本质诉求不是绝对停顿最短,而是进程 RSS 更可控、容器密度更高、OOMKill 风险更低。不同目标会直接导向不同选择。
这就是为什么“某收集器更先进所以更好”是一个错误命题。先进不等于适配。低停顿不等于低总成本。更复杂的并发回收协议通常意味着更高的 CPU 消耗、更多的元数据、更多的观察点和更难的误判成本。架构师真正要做的,不是追逐最炫的 collector,而是把 collector 放进业务约束、硬件预算和可回滚的工程流程里。
从平台治理视角再看一遍,这个命题还包含一个常见的组织误差:团队往往只比较 collector 的技术特征,却不比较 collector 对组织流程的要求。某个 collector 即便在纯技术上更接近目标,如果它要求团队重建大量观测能力、重新培训值班工程师、修改灰度模板、重新定义回滚阈值,那么这些附带成本就已经是决策的一部分。很多时候,架构师真正的成熟不在于知道哪个 collector 更先进,而在于知道组织当前是否具备承接它的运行条件。
1.2 GC 的代价模型:吞吐、延迟、内存、CPU、分配与尾部风险
GC 的生产代价不能只看“暂停时间”一个数字。暂停时间当然重要,但不是全部。很多人把 GC 认知固定在 stop-the-world 上,这是 HotSpot 早期年代遗留给团队的心智模型,而现代 G1、ZGC、Shenandoah 都在把部分工作移到并发阶段。问题在于,并发并不等于免费。它只是把代价从一个大的暂停,拆成若干分布在应用运行期间的小代价:屏障开销、并发线程 CPU、额外元数据、浮动垃圾、转发表、remembered set 维护、并发标记和重定位带来的缓存与内存带宽争用。
因此,生产上至少要同时看五类指标。第一类是暂停指标,例如 Young pause、Mixed pause、Remark、Cleanup、relocation pause 等。第二类是并发指标,例如并发标记阶段是否跟得上分配速率,并发线程是否与业务线程抢 CPU。第三类是内存指标,例如回收后堆占用是否持续抬升、Old 区增长是否可逆、RSS 是否在 heap 稳定时仍持续增长。第四类是分配指标,例如每秒分配字节数、survivor 压力、晋升速率、humongous object 频率。第五类是尾部风险指标,例如 p99/p999 延迟、请求排队时间、超时比例、重试放大等。
如果一个服务平均暂停只有几毫秒,但 p999 请求仍然很差,那么问题很可能不在“平均 GC 很短”,而在某些阶段与业务峰值叠加,或者分配突刺、锁竞争、线程池排队把局部影响放大了。相反,如果暂停偶尔较长,但业务本身是批处理,整体 wall-clock 时间和硬件成本更优,那这也许是合理选择。工程判断永远优先于单指标执念。
在这五类指标里,最容易被组织忽视的是“指标之间的顺序关系”。例如某次 GC pause 变长,也许并不是问题的起点,而是因为前面已经发生了分配突刺、连接池等待和线程排队,collector 只是最后把风险显性化。反之,有些事件会先从并发 GC CPU 或 old-after-GC 变化上体现出来,随后才逐步拖到业务尾延迟和吞吐。架构师如果只把这些指标当作平铺图表,而不去看它们之间的先后关系,就很难判断究竟该优先改 collector、改业务对象、改预算,还是改平台治理。
还有一种常见偏差,是团队习惯按绝对值判断风险。例如“pause 超过 100ms 才算问题”“RSS 超过某个固定比例才危险”“Young GC 超过每秒多少次才异常”。这些阈值可以作为报警起点,却不能直接作为工程真理。因为不同业务的目标不同、流量峰值不同、实例大小不同,甚至同一业务在不同时间段的可接受区间也不同。真正稳定的做法,是把绝对阈值和相对变化结合起来:和自身历史基线相比变了多少,与业务损伤是否同向,是否持续,是否只在某个特定场景出现。
架构评审里还应把“代价支付方式”写清楚。某次 collector 切换也许确实缩短了 pause,但如果换来更高 CPU、更低 pod 密度、更复杂的值班判断和更高的发布门槛,那么它并不是零成本优化。GC 调优的成熟度,往往体现在团队是否能同时说出“我们获得了什么”和“我们为此付出了什么”。只有收益与代价都被写出来,collector 决策才真正具备商业和工程意义。
1.3 为什么说 GC 是“契约”
把 GC 理解成“契约”,是为了逼迫团队承认一个事实:GC 不是 JVM 单方完成的事情,而是应用对象生命周期、线程模型、缓存策略、序列化方式、容器资源限制、发布策略、观测能力共同签署的一份合同。HotSpot 只是在执行这份合同。你如果让服务无限制缓存对象、频繁构造大数组、把解码结果堆在内存里、在容器里把 -Xmx 配到极限、给业务线程和 GC 线程同样的 CPU 配额、又不保留 GC logs 和 JFR,那合同的破裂就不该归咎于 collector 本身。
这一点在云原生环境尤其重要。过去物理机时代,一个 Java 进程吃掉一点额外 native memory 也许还不致命;但在 Kubernetes 或者多租户平台中,RSS 超出 limit 的后果不是“稍慢一点”,而是直接 OOMKill。很多团队只看 jstat 或应用内埋点里的 heap usage,就误以为内存很安全,结果容器层面因为 direct buffer、TLS/native 库、code cache、thread stack 或 GC 元数据增长被杀掉。此时如果你继续扩大堆,只会让问题更快出现。
1.4 版本边界也是生产契约的一部分
GC 的很多“常识”其实只在某些 JDK 版本成立。把这些版本边界说错,会直接把文章从工程指南写成误导材料。比如很多老资料仍然把 G1 Full GC 说成单线程串行路径,但 JDK 10 通过 JEP 307 已经为 G1 引入 Parallel Full GC。再比如把 ZGC 笼统描述成“实验性低延迟 GC”,那只适用于早期阶段;从 JDK 15 起,ZGC 已经作为 product 特性发布。再比如如果还把非分代 ZGC 当作现代默认行为,那就已经落后于 JDK 23 和 JDK 24 的事实。Shenandoah 也有类似问题,尤其是在 generational mode 的实验性、product 状态和默认行为上,必须谨慎表述。
因此,本文一律采用保守表达:当某个行为明显依赖 JDK/JEP 状态时,会明确说“从某版本开始可用”“某模式在某版本成为默认”“某模式在某版本移除”“某能力属于实验性或 product 状态”。如果你在生产中使用的是特定发行商 build,还要再看对应 vendor release notes,因为 HotSpot 主线结论不总能完整覆盖每个发行版的运维现实。
版本边界还会影响团队内部沟通质量。一个很常见的问题是,不同人脑中记着不同年代的“Java 常识”,结果在评审会上说的其实不是同一个运行时。例如有人以 JDK 8 或 JDK 11 的经验讨论 G1 和 ZGC,有人已经按 JDK 21 之后的 generational 语义理解 collector,还有人只从供应商镜像的默认配置出发。若不先把版本边界钉住,后面的讨论很容易变成“每个人都对,但大家说的不是一个对象”。因此,把版本写在 collector 判断的开头,不是教条,而是为了让团队在同一张地图上说话。
这也解释了为什么快变事实必须谨慎处理。collector 默认行为、模式移除、JDK feature release、供应商支持周期、诊断参数可用性,都属于容易随时间变化的事实。文章里如果把这些内容写成永恒结论,不仅会误导读者,还会让后续维护成本迅速增加。对技术内容而言,保守表达并不是“讲得不够确定”,而是给事实变化留下可审计空间。
2. 从症状建立诊断入口:先问“是不是 GC”,再问“是哪类 GC 问题”
症状分流之所以重要,是因为生产世界的故障成本往往来自误判而不是慢一点发现真相。一个团队如果在第一次看到延迟抖动时就直接切换 collector,可能在几小时内做了很多“积极动作”,却让真正的根因继续扩大。相反,一个团队如果能在十分钟内先回答“这是尾延迟事件、对象存活事件、容器预算事件还是分配突刺事件”,哪怕还没最终定位,也已经把后续决策质量拉高了一个数量级。诊断入口不是形式主义,它是降低返工与误操作成本的第一道门。
更成熟的做法,是把症状按业务形态做一次映射。比如 API 网关和 BFF 更容易把请求峰值、JSON 编解码、短命对象风暴和下游队列放大到 GC 节奏里;批处理和流式任务更容易把大批量对象、长链路缓冲区和大数组问题放大到 Old 区与 humongous allocation 上;多租户 SaaS 服务则更常见“少数租户数据形态异常导致局部实例内存倾斜”;实时风控、撮合和广告竞价之类的低延迟服务则更怕小概率但高破坏性的尾部事件。只有把业务形态纳入症状分流,后续证据才不会脱离服务现实。
症状还必须按时间关系来读。有些问题是冷启动后立刻出现,比如 JIT 预热、类加载、初始缓存填充、镜像层加载、初次大批量请求;有些问题只在稳态数小时后出现,比如缓存膨胀、对象引用链积累、租户数据偏斜、某些任务周期性运行;还有些问题只在流量峰值或特定批任务窗口中出现。对 GC 来说,时间关系本身就是线索。Young GC 过密和 Full GC 激增如果只在峰值发生,通常和分配率、突发对象形态有关;如果在低流量也持续出现,则更像 leak、错误缓存或容器预算过紧。
另一个需要提前统一的判断规则是:症状要优先被定性为“业务可见后果”,而不是“技术现象”。例如“容器被 OOMKill”是业务后果,不是技术原因;“p999 超过 SLA”是业务后果,不是技术原因。技术现象应该是“RSS 在 steady state 持续上升”“Old 区回收后不回落”“allocation stall 与峰值同时出现”“某些请求路径创建巨大临时对象”。先把两者分清,团队讨论才不会不断在业务语言和 JVM 语言之间跳跃,导致结论含混。
最后,症状分流要留下决策痕迹。每一次故障排查都应该有一句可以复述的判断,比如“本次先按容器预算问题处理,不先改 collector”“本次先按 allocation pressure 处理,不先 dump 堆”“本次先按尾延迟事件看 safepoint 与 request queueing 同步关系”。这句话看似简单,却能在团队协作时减少大量无序动作。GC 问题里,判断顺序本身就是工程资产。
2.1 症状不是根因,症状只是入口
生产故障通常不是以“GC 出问题了”这种形式出现,而是以更含混的业务语言表现出来:接口偶发超时、网关在流量高峰时 jitter 增大、批处理任务突然跑慢、pod 被 OOMKill、容器 RSS 在低流量下仍不下降、CPU 比上周高很多、节点密度下降、压测时 tail latency 爆炸、重新部署后前几分钟一切正常但数小时后开始抖动。所有这些都可能与 GC 有关,但也同样可能根本不是 GC。
因此症状的价值,不在于直接告诉你答案,而在于帮你分类问题空间。好的架构师不会一上来就问“换不换 ZGC”,而会先问:这是延迟问题、吞吐问题、内存问题、分配问题、暂停问题,还是容器预算问题?它是持续性问题、周期性问题,还是流量峰值触发的问题?它只在某个版本、某个实例、某种租户请求、某类数据集上出现,还是全局一致?它是在冷启动、稳态、发布后、GC 周期交替、批任务开始时出现,还是与下游依赖抖动同步?
把问题分类之后,才有可能决定要优先看哪类证据。否则很多团队会同时拉出 GC log、heap dump、thread dump、CPU profile、数据库慢查询、容器监控,结果信息堆积但没有判断顺序,最后仍然只能回到“感觉像 GC”这种不可靠结论。
2.2 吞吐下降:GC 可能是拖慢者,也可能只是放大器
吞吐下降是最容易被误判的一类问题,因为它表面上常常伴随 GC 次数变多、CPU 升高、服务处理能力下降,看起来非常像“GC 抢 CPU”。但更准确的说法是:GC 可能是真正的拖慢者,也可能只是系统开始失衡后的放大器。
如果业务分配率突然上升,例如请求里出现更大的 JSON、更多临时字符串、更多解压/编解码对象、更多 Map/List 拼装,Young GC 次数自然会上升;但这并不自动意味着要换 collector。也许真正要改的是对象生命周期和数据结构。相反,如果业务对象存活率没什么变化,但 collector 的并发阶段明显跟不上分配速率,导致退化到更多暂停路径,那么这就更接近 GC 本身的能力边界。
判断吞吐问题时,必须把几个观察点放在一起:第一,看 CPU 总体占用和 GC 线程占比。第二,看应用吞吐下降是否与分配率突增同步。第三,看 Old 区占用是否因为晋升压力而持续抬升。第四,看回收后可用空间是否越来越少。第五,看暂停时间之外,并发标记、并发重定位、remembered set 更新是否在稳定消耗 CPU。只有这些证据串起来,才能判断吞吐下降到底是“GC 过度工作”,还是“应用制造了让 GC 不得不工作”的局面。
2.3 延迟抖动:平均值会掩盖真正的风险
如果一个服务最核心的 SLA 指标是 p99 或 p999,那么“平均 GC 暂停只有几毫秒”几乎没有意义。生产中的风险通常出现在尾部:某次 remark、某次 evacuation pause、某次 humongous allocation 导致的路径变化,与业务峰值、线程池饱和、网络重试、数据库拥塞叠加后,被放大成几个九上的尾延迟事故。
延迟问题最常见的误区,是把单次 pause 直接等同于端到端请求延迟。实际上 GC 暂停只是延迟组成的一部分。一次 20ms 的停顿在空闲时段可能对业务完全无害,但在排队已经拉长、线程池接近满载、下游连接池紧张时,可能触发雪崩式超时。因此架构师关注的不只是 pause 本身,还要看 pause 发生时系统整体压力处于什么状态。
这就是为什么 JFR 和 tracing 要一起看。GC log 可以告诉你某个时刻发生了什么 GC 事件,JFR 可以补充 allocation、safepoint、线程状态、方法热点、锁竞争、socket I/O 等信息,而 tracing 或服务端延迟指标可以告诉你那一刻业务请求是否真的同步抖动。少任何一层,判断都可能失真。
2.4 内存症状:先区分 heap、committed heap、RSS 与容器 kill
很多“内存问题”其实只是团队把不同层次的内存概念混在了一起。heap used、heap committed、进程 RSS、容器 memory working set、cgroup usage、JVM 报出的 OutOfMemoryError、内核 OOM killer 的 kill event,这些不是一回事。架构师如果在术语层面没有先分清,就很容易做出错误动作。
例如某些服务在 GC 后 heap used 已经回落,但 RSS 仍然高企,这不一定是“GC 没回收干净”。原因可能是 committed heap 没缩回去,也可能是 direct memory、Metaspace、thread stack、native allocator、mmap 文件、JIT/code cache 或 TLS/native library 占用没有下降。相反,某些服务看到 heap used 持续爬升,以为只是业务缓存增多,但实际上 Old 区回收后仍无法回落,这更像 retention 或 leak 问题。
因此所有内存症状都应该先经过一层拆分:究竟是 Java heap 空间不足、GC overhead 过高、Metaspace 异常、Direct buffer memory、native memory 持续增长,还是容器 RSS 超限?这一步非常基础,但决定了后面证据链的方向。
这一步之所以基础却总被跳过,是因为“内存高了”在业务沟通里看起来足够直观,而把它继续拆成 heap、committed、RSS、native 似乎像 JVM 细节。但对生产来说,这恰恰不是细节,而是能否做出正确动作的分界线。假如你把 RSS 高当成 heap 高,就会扩大堆;把 Metaspace 增长当成 Old 区增长,就会在错误方向上做 dump;把 direct memory 问题当成 GC 问题,就会在 collector 上浪费时间。很多昂贵误判,都是从这里开始的。
在团队培养上,一个很有效的办法是要求复盘时禁止使用“内存问题”这种笼统说法,而是必须明确写成“heap after GC 持续抬升”“container RSS 在 steady state 继续增长”“Metaspace 接近上限”“direct memory budget 失衡”“thread stack 与线程数共同放大 RSS”。语言一旦被精细化,排查动作自然会更精准。
为了让这种语言真正落地,平台团队还可以把内存告警按层拆开。比如 heap 相关告警只对应用团队和 JVM 方向工程师触发,RSS 与 cgroup 告警同时抄送平台与 SRE,Metaspace 或 direct memory 趋势异常则要求在排查单中单独填写。这样做会增加一些运营成本,但长期看能显著减少“所有内存问题都混到一个告警里”的混乱。GC 相关误判很多时候并不是技术深度不够,而是告警语言一开始就把问题混成一团。
还可以再进一步,把典型事故类型预先归档成样例。例如“heap after GC 不回落但 RSS 正常”的样例更像长期存活对象问题;“heap 正常但 RSS 连续抬升”的样例更像堆外预算问题;“Young GC 激增但业务延迟无感”的样例可能只是正常高分配业务形态;“pause 不长但吞吐掉、CPU 抬高”的样例则要优先怀疑并发代价和业务热点。样例并不能替代分析,但它们能帮助团队在第一次看到图时迅速进入正确的问题空间。
2.5 分配压力、晋升失败、humongous allocation 与容器 OOMKill
在现代 Java 服务里,最容易被忽视的不是传统意义上的“垃圾太多”,而是分配压力和对象形态变化。一个接口在优化前后都可能有相同的业务逻辑,但如果新版本在序列化、聚合、日志拼接、批量缓存、解压缩或协议转换时产生了大量短命对象,就会直接改变 Young GC 的节奏。再进一步,如果 Survivor 和 Old 区承受不了这些对象的存活路径,就会出现晋升压力、promotion failure 或 mixed collection 收益下降。
humongous allocation 也经常被低估。对于 G1 这类 region-based collector,大对象会走特殊路径,频繁的大对象分配不只是“占更多内存”,还可能改变 region 使用方式、压缩空间、影响 mixed GC 收益,并在错误时机触发 Full GC 或回收效率下降。很多服务在处理大 JSON、protobuf、列式数据块、压缩包、图像、批量聚合缓冲区时都会踩这个坑。
容器 OOMKill 则是另一类更危险的问题。它常常发生在 Java 自己还没抛出 OutOfMemoryError 之前,因为对内核来说,只要 RSS 超过 cgroup limit,进程就可以被杀。对架构师而言,这意味着“JVM 没报错”绝不代表“内存没问题”。如果你只看 heap 曲线,就可能错过最关键的信号。
从架构设计角度看,分配压力往往是最值得优先治理的一类问题,因为它同时影响吞吐、延迟和内存。大量短命对象会增加 Young GC 频率,部分幸存对象会带来 Survivor 与晋升压力,而某些批量对象或大数组又可能演化成 humongous allocation 问题。也就是说,一个看似只是“对象创建有点多”的应用层问题,最后能沿着多条路径同时恶化 collector 表现。相比之下,单纯围绕 pause 去调参数,往往只能缓解表层症状。
团队还应注意“分配突刺”与“平均分配率”不是同一件事。有些服务平均看起来并不激进,但会在特定操作、租户、批次或峰值窗口内瞬间制造大量对象。这种尖峰式分配更容易把 collector 推向边界,也更容易和业务尾延迟叠加。平均值很好看并不能保护你。针对这种场景,观察和限流策略有时比 collector 变更更先见效。
2.6 建立症状到入口的最小诊断表
在生产里,最有价值的不是最复杂的分析工具,而是一张能让团队快速分流问题的判断表。下面这张表的意义,不是代替分析,而是规定第一步该看什么。
| 症状 | 第一怀疑对象 | 首先收集的证据 | 常见误判 |
|---|---|---|---|
| p99/p999 偶发尖刺 | GC 暂停、safepoint、线程池排队、下游抖动 | GC log、JFR、request latency timeline、thread dump | 把任何慢请求都归因到 GC |
| 吞吐在峰值期下降 | 分配率、并发 GC CPU、对象生命周期变化 | GC log、allocation profile、CPU profile、JFR | 只因 GC 次数变多就换 collector |
| Old 区持续增长 | cache retention、listener leak、classloader、晋升率 | heap dump、JFR old object sample、GC log | 以为“堆再大一点就好” |
| 容器被 OOMKill | RSS 预算错误、direct/native memory、thread stack | cgroup metrics、NMT、container events、JFR | 只看 Java heap usage |
| Full GC 增多 | evacuation failure、humongous pressure、heap reserve 不足 | GC log phase detail、heap region stats | 把 Full GC 视为“偶发可接受” |
| CPU 升高但暂停不长 | 并发标记/重定位、屏障开销、业务本身 CPU 热点 | CPU profile、JFR、GC concurrent phase timing | 认为“pause 不长就不是 GC” |
这张表背后的核心思想很简单:症状只负责缩小范围,证据负责决定下一步。没有证据,就不要开始调参数。
如果要把这张表真正用到一线值班里,还可以进一步把它变成几个“固定追问”。例如当看到 p999 抖动时,先问三个问题:故障窗口里是否真的有 GC 事件;这些事件是否与请求抖动时间同步;若同步,抖动发生前系统是否已经排队。再例如当看到 RSS 增长时,先问:heap used 是否同步增长;GC 后 Old 区是否能回到基线;NMT 与 direct memory 是否有异常抬升。这样做的价值,在于把“经验丰富的人脑中已有的判断顺序”显式化,让非 JVM 专家也能在高压环境下做出接近正确的第一轮判断。
很多团队之所以在 GC 相关事故里反复打转,就是因为他们的第一轮问题问错了。比如一看到 OOM 就问“堆要不要加大”,一看到延迟就问“pause target 要不要调小”,一看到 Full GC 就问“是不是换 ZGC”。正确的问题应该更接近“这次症状属于哪一层系统行为”“collector 只是看起来忙,还是确实在引发业务损伤”“我们现在缺的是哪类证据”。问题一旦问准,后面很多动作会自动收敛。
另一个值得强调的细节是:诊断入口需要考虑正常噪声。生产系统里不是所有 Young GC 频率升高都危险,不是所有 Old 区增长都异常,也不是所有 CPU 升高都与 GC 有关。真正危险的,是模式改变而且这种改变与业务损伤同向。也就是说,团队应该学会建立“平时的正常形态”基线。没有基线时,人们容易把任何看起来不熟悉的图形都当成故障信号,最后让告警系统和排查流程都疲于奔命。
因此,GC 诊断表的长期用途并不只是事故排查。它还能反向帮助团队设计日常 dashboard:哪些图是值班真的会用到的,哪些图只是看起来很专业却几乎没有决策价值。把 diagnostics 反哺到日常观测面,是让 GC 从“事故时才想起”的专题,变成平时就有治理抓手的关键一步。
对于架构师来说,这一点尤其重要,因为很多平台图表从设计一开始就偏向“展示很多数据”,而不是“支持关键决策”。例如 dashboard 上堆满了 heap 曲线、pause 曲线和 CPU 曲线,却没有把 post-GC old occupancy、allocation rate、RSS 与 cgroup limit、容器重启事件、JFR 保留窗口、发布版本信息放进同一视图。这样的图表在汇报时看起来很全,真正排查时却缺少决定性的上下文。诊断入口做得好,日常观测面就会更像决策面板,而不是图表陈列室。
3. GC logs 与 JFR:证据链应该如何建立
证据链的核心价值,不在于“收集了很多数据”,而在于每一类数据都能回答一个明确问题。GC log 最适合回答“collector 当时做了什么”;JFR 更适合回答“JVM 当时整体在发生什么”;容器和系统指标回答“进程与平台边界是否紧张”;trace 与延迟指标回答“业务到底有没有同步受伤”。如果这些证据之间没有问题分工,最后就会出现很常见的现象:日志很多、图表很多、结论却仍然只是“应该和 GC 有关系”。
一个高质量证据包通常具备三个特征。第一,它能还原时间顺序,而不是只给出孤立快照。第二,它能让不同角色的人都读懂自己需要的部分,比如应用开发看到对象分配热点,平台团队看到容器与 JVM 边界,SRE 看到发布窗口与告警时序。第三,它支持复验,也就是在事后复盘或下次类似事故里还能复用判断过程。仅能解释一次事故、但无法复用的证据体系,长期价值其实很低。
GC 证据还有一个常见陷阱:团队只保留“最重”的证据,例如 heap dump,却不保留“最连续”的证据,例如 GC logs 和 JFR。结果就是一旦 dump 太大、抓取太慢、权限太敏感,平时根本没人愿意做,而最基础的持续证据又缺失。成熟的生产治理应该反过来:优先保证低成本、持续性、可对齐的证据永远存在,再根据窗口和风险决定是否上更重的工具。没有基础连续证据,任何重型证据都难以解释时间关系。
还有一点非常重要:证据的保留期要覆盖真实故障周期。很多团队的 GC 日志轮转策略和 JFR 保留策略都过短,导致问题真正发生时,关键窗口已经被覆盖。尤其对于“运行数小时后才出现”的内存和尾延迟问题,如果日志只保留一小时,你根本不可能看见从正常到异常的渐变过程。证据保留不是单纯的运维细节,而是直接决定能否做因果判断的前提条件。
从审计视角看,证据链还承担“让技术判断可复查”的职责。很多 GC 相关结论在现场看似显而易见,比如“这里就是 Full GC 导致的超时”“这里就是 RSS 头寸不够”。但如果没有原始日志、JFR 和平台指标窗口保留下来,几周后复盘时就很难再证明当时为什么做出那个判断。生产里的好结论不仅要能说服当班的人,还要能在事后经得起团队再次审核。否则经验无法沉淀,平台治理也无法长期进步。
3.1 为什么 GC log 是起点,而不是终点
统一 GC 日志是 JVM 在 GC 维度最基础、也最容易持续启用的证据面。它能告诉你发生了什么类型的回收、暂停花了多久、GC 前后堆占用如何变化、并发阶段推进情况如何、某些 collector 特定事件是否频繁出现,以及 Full GC、humongous、to-space exhaustion、evacuation failure 等关键告警是否出现。
但 GC log 只能回答一部分问题。它更像是事故现场摄像头,只记录 collector 角度的事件,而不是整个服务系统的因果链。它能告诉你“这里发生了一次 40ms pause”,却不能自动告诉你这 40ms 是否恰好压中了网关尾延迟、线程池是否已经排队、数据库是否同时抖动、应用是否刚经历大规模对象构造。也就是说,GC log 非常适合建立“GC 有没有参与”的第一层证据,但不适合单独承担根因判断。
所以正确的姿势是:GC log 先判断 collector 侧发生了什么,再用 JFR、延迟指标、CPU profile、heap dump、container metrics 去回答“为什么发生”和“它是不是主因”。
3.2 看 GC log 时先看哪些字段
读 GC log 最常见的问题不是日志不够多,而是团队不知道先看什么。许多人一打开日志就盯着 pause 时长,忽略了更能解释根因的上下文。更有效的顺序通常是这样的。
第一,先看 GC 类型和频率。Young GC 很密不一定是坏事,但如果频率高到与请求峰值同步、或者每次回收收益越来越差,就值得深入。Mixed GC 如果长期回收收益低,可能意味着 Old 区里大多是真正存活对象,也可能意味着回收策略跟不上对象形态变化。Full GC 一旦出现,就必须把它当成重大信号,而不是“有 GC 就会这样”。
第二,看 GC 前后堆占用变化。回收后空间是否明显释放?Old 区是否持续单向增长?回收是否只对 Eden 有效果,对 Old 几乎无影响?这决定后续是去查分配压力、晋升压力,还是 retention/leak。
第三,看暂停阶段分解。某些服务的问题不是 pause 总量太大,而是其中某个子阶段异常,例如 root scanning、remembered set scan、reference processing、evacuation、relocation prepare、remark 等。只有看 phase breakdown,才能知道瓶颈在 collector 哪个阶段。
第四,看 collector 专属告警。G1 需要重点关注 humongous、to-space exhaustion、evacuation failure、mixed reclaim 收益;ZGC 要看 allocation stall、并发阶段推进、relocation/mark 事件;Shenandoah 要看并发转移进度、degenerated 或 full 路径。不同 collector 的“危险词”不同,阅读方式不能一刀切。
3.3 GC log 与应用延迟怎么对齐
生产分析里最关键的一步,是把 GC 事件与业务时序对齐。单看 GC log,你可能发现某次 pause 是 18ms,于是直觉上觉得不严重;但如果那 18ms 恰好发生在网关排队、数据库慢查询和超时重试叠加的窗口里,它对业务的破坏可能远大于数字本身。反过来,如果一次 60ms pause 发生在离线任务中,业务用户根本无感,那就不是同级别问题。
因此,延迟服务的标准动作应该是把 GC 时间线与请求耗时分布、错误率、线程池队列、连接池耗尽、CPU 峰值同步放在一个窗口里观察。你真正要寻找的是“相关性”与“前后因果”。GC 是在业务已经抖动后才变忙,还是 GC 先发生,业务随后抖动?这两者意义完全不同。前者更可能是业务放大了 GC 工作量,后者更可能是 GC 触发了业务波动。
3.4 JFR 补足 GC log 的盲区
JFR 的价值在于,它不是只看 GC,而是把 GC 放在 JVM 运行上下文中一起观察。对于 GC 诊断来说,JFR 至少补足四类盲区。
第一,分配证据。GC log 只能间接反映回收节奏,JFR 可以更直接地看到 allocation rate、热点分配路径、TLAB/外部分配模式、对象样本等,这有助于判断问题究竟来自 collector 本身,还是来自代码对象创建过多。
第二,线程与 safepoint 证据。许多服务把 safepoint 或线程阻塞误认为 GC。JFR 可以帮助区分是 GC 相关 safepoint,还是 class redefine、biased locking 历史路径、线程 dump、其他 VM operation 触发的停顿。
第三,方法与 CPU 证据。如果并发 GC 线程真的抢走了大量 CPU,JFR 往往能看到相关线程和阶段特征;如果 CPU 主要被业务代码、序列化、加密、正则、压缩、日志框架吃掉,JFR 也能帮你及时排除“不是 GC 主因”。
第四,I/O、锁与外部依赖证据。某些慢请求恰好伴随 GC,但主要时间消耗在数据库等待、网络等待、文件 I/O 或锁竞争。只有把这些维度一起看,GC 才不会被误判成唯一根因。
JFR 对架构师还有一个额外价值:它能帮助团队跨角色对齐语言。应用开发更容易从 allocation hotspot、stack trace sample、method profile 理解问题;SRE 更容易从时间轴、事件密度和系统状态关联理解问题;平台团队则更容易把 JFR 结论与镜像、JDK、容器配额和发布轨迹联系起来。GC log 单独使用时,往往只有少数 JVM 背景强的人能快速读懂;JFR 提供的上下文,能把这件事变成跨角色可沟通的问题。
但 JFR 也不是“录了就有答案”。如果录制策略不合适,比如保留窗口太短、关键事件没打开、文件轮转策略不匹配故障周期,或者压根没有和业务指标做时间对齐,那么 JFR 只是另一份很大的文件。因此团队在平时就应该决定:哪些服务需要持续 profile 级别采样,哪些服务只在灰度与故障窗口开启,哪些事件足以支撑 GC 诊断,哪些事件属于锦上添花而不是刚需。没有这个策略,JFR 在很多组织里会变成“理论上很强,实际上从来没人用熟”的工具。
还有一个经常被忽略的用法,是把 JFR 当成 collector 变更的验收工具,而不只是事故排查工具。比如你从 G1 切到 ZGC,不能只看 pause 是否下降;你还应该通过 JFR 去确认 allocation pressure 是否变化、并发阶段 CPU 是否抬升、线程状态是否更稳定、safepoint 分布是否改善。也就是说,JFR 在 collector 选型中既服务于故障解释,也服务于变更验收。
3.5 建立“先日志、再 JFR、再 dump”的采证顺序
采证顺序本身也是工程纪律的一部分。很多团队一出现 GC 怀疑就马上 dump 堆或改 JVM 参数,这是高成本低质量的做法。更推荐的顺序是:先开统一 GC 日志,确认 collector 侧症状;再录 JFR,判断 GC 与 CPU、分配、线程、safepoint、I/O 是否同向变化;再决定是否需要 heap dump 或 Native Memory Tracking;最后才开始尝试参数变更。
原因很现实。heap dump 非常重,Native Memory Tracking 会带来一定成本,参数变更则会直接改变系统行为。如果你在没有建立前置证据时就进入这些步骤,很容易把问题分析成“改了之后好像好了”,但根本不知道好转来自参数、来自流量变化、来自缓存预热,还是来自某个无关的发布窗口。
3.6 最小可用的日志与 JFR 采样基线
下面这段配置不是“推荐参数模板”,而是为了满足最基本的可观察性。读者使用时必须根据自身 JDK 版本、日志系统、磁盘配额和采样策略调整。
场景:补齐最小 GC 证据。原因:避免猜测。观察点:对齐 GC/JFR 事件。生产边界:仅作起点。
java \
-Xlog:gc*,gc+heap=debug,gc+ergo=trace,gc+phases=debug:file=/var/log/app/gc.log:time,uptime,level,tags:filecount=10,filesize=50m \
-XX:StartFlightRecording=filename=/var/log/app/app.jfr,settings=profile,dumponexit=true,maxage=2h,maxsize=1024m \
-jar app.jar这段命令真正重要的,不是你是否精确使用了相同的标签,而是它体现了两个原则:第一,GC 证据必须可持续、可对齐,而不是故障时才临时抓;第二,GC 日志与 JFR 应该被视为互补证据,而不是互相替代。
4. 堆、非堆与容器内存:为什么 heap 正常,容器仍然会死
很多 Java 团队直到进入容器平台之后,才第一次真正感受到“JVM 看见的世界”和“内核看见的世界”不一致。对 JVM 来说,堆可以看起来很健康;对内核来说,进程 RSS 已经危险。对应用埋点来说,heap used 回落了;对平台来说,pod 的 working set 却没有下降。只要这两种视角不被同时纳入日常运维,团队就会不断重复一种代价极高的误判:明明 GC 之后内存掉下来了,为什么还是 OOMKill。
要解决这个问题,最重要的不是记住更多术语,而是建立统一账本的习惯。每个服务在设计期就应该回答几个问题:线程数上限是多少、direct buffer 典型体量是多少、是否使用大量反射和代理、是否有 native SDK、是否依赖 mmap 或大页缓存、是否有大规模压缩与解压、是否存在大批量批处理窗口。这些问题不是上线后才临时想起的排查清单,而是决定 heap 预算能否合理设置的前提。没有这些回答,任何“经验比例”都会在真实场景里失效。
容器环境还放大了一个历史上不那么刺眼的问题:资源隔离会把原来可以缓冲的误差直接转成故障。物理机时代,一个服务多占一两 GB native memory,也许只是让同机邻居难受;容器时代,这可能直接导致当前 pod 被杀、触发实例重建、引发连接风暴和重试放大。于是一个看起来只是“内存多了点”的问题,最后会变成集群层面的稳定性事件。架构师如果还把内存治理理解成“JVM 堆多大合适”,就会明显落后于现实运行模式。
此外,heap 和 non-heap 的关系也会影响 collector 选型本身。某些服务堆并不算大,但 direct memory、thread stack 和 native 库占比很高,那么 collector 再怎么调也不可能单独解决 RSS 风险。相反,某些服务 heap 极大、对象生命周期复杂、tail latency 严苛,那么 collector 路线就更值得认真比较。也就是说,内存账本不仅决定 sizing,还决定你是否应该花成本去切换 collector。账本没算清之前,collector 再先进也只是局部补丁。
最后需要强调的是,内存治理是一个长期的“偏差控制”问题,而不是单次配置问题。服务一旦演进,线程模型、依赖库、对象布局、缓存策略、协议大小和租户结构都会变。今天合理的 heap 与容器预算,半年后未必仍然合理。成熟团队会定期重算账本,而不是把初始配置当成永久正确。
4.1 Java 进程的内存账本从来不只有 heap
很多 GC 调优失败,不是因为 collector 没调好,而是因为团队根本没建立完整的 Java 进程内存账本。Java heap 只是其中最显眼的一部分,但远远不是全部。只看 heap usage 的团队,在容器环境里极易做出危险配置,比如把 -Xmx 直接顶到 memory limit 附近,然后在 direct buffer、线程栈、Metaspace、native 库、code cache 或 GC 元数据稍有波动时被 OOMKill。
从生产运维角度,至少要把以下几类空间明确记在预算里:heap、Metaspace、code cache、direct memory、thread stack、GC 元数据、JIT/compiler 内存、native allocator 以及由 mmap、TLS、压缩/解压库、网络库等带来的附加 native 开销。只有把这些都纳入预算,你才能真正回答“这个 pod 能配多大堆”。
这也是为什么“JVM 还没报 OOM,说明内存没问题”是非常危险的误判。内核的 OOM killer 不关心 Java 语言视角里的 heap 是否健康,它只关心整个进程是否超出 cgroup limit。
4.2 heap、committed、used、RSS、working set 不是同一层概念
Heap used 指当前真正被对象占用的堆空间;heap committed 指 JVM 已经向操作系统申请并保留给堆使用的空间;RSS 是进程实际驻留内存页;container working set 还会再叠加 cgroup 和 page cache 等视角。它们之间没有简单的一一映射关系。
例如某个服务 GC 后 heap used 已经明显下降,但 heap committed 不会立刻缩回,RSS 也可能因为页仍然驻留而保持较高。此时如果你只看 RSS,就会误以为“GC 没回收”;如果你只看 used heap,又可能低估容器预算风险。反过来,如果 heap used 本身就持续抬升,而回收后仍不下降,那就更像是长期存活对象、cache retention 或 leak 的问题。
所以内存分析时必须明确自己在看哪个层次。如果你回答不了“当前告警是 heap used 高,还是进程 RSS 高”,那还没到调 GC 参数的时候。
4.3 Metaspace、direct memory、thread stack 为什么会被误判成 GC 问题
Metaspace 增长常见于 classloader 泄漏、动态代理、频繁热部署、插件式加载路径或某些代码生成框架。它不是 Java heap,但如果实例 RSS 因此持续增长,业务团队仍然可能把问题甩给 GC。Direct memory 则经常出现在 Netty、NIO、零拷贝、压缩和部分数据库驱动场景里。它的风险在于,应用内埋点往往默认看不到,只有从 JVM 参数、NMT、容器监控或相关库指标中才能补足证据。Thread stack 则与线程数、虚拟线程之外的 carrier thread、连接池、调度器和错误的线程模型有关。
这些空间之所以会被误判为 GC 问题,是因为故障表象常常高度相似:RSS 高、pod 被杀、服务抖动、CPU 升高。但它们的解决路径完全不同。Metaspace 问题更像类加载治理;direct memory 问题更像 I/O 和 buffer 生命周期治理;thread stack 问题则更像线程模型和并发治理。GC 在这里可能只是因为内存压力增大而更加忙碌,但并不是源头。
4.4 容器里的正确问题不是“堆多大”,而是“预算怎么分”
在容器环境中,堆的大小不能独立决定,必须从整个进程预算反推。最常见的坏配置,是把 -Xmx 直接设成 limit 的 80% 到 95%,以为这样“利用率高”。这在轻量单线程服务上也许还能勉强工作,但在真实的 Java 服务里,线程数、Metaspace、direct buffer、TLS/native 内存、GC 元数据一旦同时抬头,RSS 就会突破 limit。
一个更成熟的做法,是先估算非堆部分的稳定预算与峰值预算,再决定 heap 上限。这个比例无法给出通用常数,因为不同工作负载差异很大。比如网络代理和 RPC 网关通常 direct memory 更敏感;反射、代理和热加载多的服务 Metaspace 风险更大;线程多的服务 stack 更显著;低延迟 collector 还可能在元数据和并发回收阶段保留更多头寸。因此生产中的正确动作不是问“Xmx 设多少”,而是问“这个服务各类内存的峰值分布是什么,留给 heap 的安全空间还有多少”。
这里还有一个很常见的组织性误区:平台团队喜欢给所有 Java 服务提供统一容器模板,例如同样的 requests/limits 比例、同样的 JAVA_TOOL_OPTIONS、同样的 heap 百分比算法。这样的模板在治理上确实方便,但如果没有按服务类型分层,很容易把某类服务的安全做法复制成另一类服务的隐患。举例来说,IO 网关、批处理、AI 编排服务、低延迟 RPC 服务和轻量 CLI 任务,它们的内存结构差异可能非常大。统一模板可以作为起点,但不能替代服务分层。
此外,容器预算不仅影响稳定性,还影响成本结构。heap 给得过大,可能导致 pod 密度下降、节点利用率降低;heap 给得过小,又会让 collector 提前承压、回收频率上升、业务尾延迟恶化。真正成熟的平台会把这两种成本一起算,而不是把“尽量多给 heap”当作永远安全的保守策略。因为在多租户环境中,过度保守本身也会转化成组织成本。
一个常见但很少被明说的现实是:容器预算的错误,往往不会先以“堆不够”这种容易理解的形式出现,而会以更难解释的症状出现,例如少数实例在峰值时 RSS 先升、pod 被随机杀掉、重启后短期恢复、随后又在高峰重复。若团队只会在故障后扩大 heap,很可能会让重启后的 warm-up 更慢、每个实例的 RSS 峰值更高、节点密度更差,最后把一个本可通过预算重分配解决的问题,演变成容量成本问题。架构师应当把“预算错误会制造哪些表象”提前讲给团队听,这样事故发生时才不会总走向最昂贵的补救动作。
还有一种值得长期防范的情况,是服务功能不断膨胀,但容器模板长期不变。起初一个模板对大多数服务都足够安全,后来某类服务引入了更多 TLS、压缩、代理、批量缓冲、AI SDK 或第三方 native 组件,内存账本已经变了,模板却还在延续旧假设。于是 collector 侧会越来越像问题的呈现面。真正成熟的组织会定期复核模板假设,而不是把模板视为一劳永逸的基础设施真理。
当组织进入多团队协作阶段后,内存账本还需要被纳入变更评审。也就是说,新引入的中间件、SDK、驱动、代理层、监控探针,最好在上线前就回答“它会增加哪些内存形态”“它是否会改变 direct memory、thread stack 或 Metaspace 预算”“它会不会让 collector 更频繁进入某类路径”。这听起来像是增加流程,但长期来看,它是在把 GC 风险前移,而不是等风险在生产中用 OOMKill 的方式提醒你。
4.5 用一个统一账本理解容器内存
为了让团队在事故复盘时不再把所有问题笼统叫成“内存不够”,可以把容器中的 Java 进程记成一个统一账本:
其中, 表示容器可承受的 Java 进程 RSS 预算, 表示 heap, 表示 Metaspace, 表示 code cache, 表示 direct memory, 表示 thread stacks, 表示 GC metadata, 表示 JIT/compiler memory, 表示 native libraries 与 allocator overhead。
这不是一个精确可加总的 HotSpot 内部公式,而是一个架构师必须长期保有的预算视图。它的价值在于提醒你:RSS 爆掉时,不要只盯着 heap;heap 紧张时,也不要忘记整个进程预算。GC 调优如果不放在这个账本里,最终都会走向误判。
4.6 容器内存预算的最小观察动作
场景:核对容器内存账本。原因:避免把 OOMKill 错判成 heap 问题。观察点:RSS、heap、NMT 是否对齐。生产边界:NMT 仅在诊断窗口启用。
jcmd <pid> VM.native_memory summary
jcmd <pid> GC.heap_info
jcmd <pid> Thread.print -locks这组命令的意义不在于“命令本身多高级”,而在于它逼迫团队把问题拆开:堆、native、线程分别看,而不是继续用“内存高”这种模糊语言讨论。
5. Collector families 与工作负载边界:不要用 slogan 选型
collector family 的比较最容易被写成“技术百科”式文章:一个一个讲原理、优点、缺点,再给一张参数表。这样写当然方便,但对生产决策帮助有限。架构师真正需要的是:当某类服务的目标函数明确后,如何迅速排除不合适的 collector,如何识别“值得进一步压测”的 collector,如何判断组织当前有没有能力稳定运营它。也就是说,选型不是单点技术比较,而是一种资源配置决策。
从组织角度看,collector 选择还受两个非算法因素影响。第一个是知识与经验分布。如果团队几乎没有人能解释 ZGC 或 Shenandoah 的日志,而 G1 的问题已经有成熟 runbook,那么即使低延迟 collector 在技术上可能更优,组织切换成本也必须被计入决策。第二个是平台默认能力。如果当前监控、镜像、JDK 升级流程、灰度系统、告警模板都围绕某类 collector 建设,那么切换到另一类 collector 的真实成本不仅是 JVM 层面,还包括平台层面的演进成本。
此外,collector 选型不应该只看“稳态平均表现”,还应该看异常窗口里的退化方式。某些 collector 在平时看起来都足够好,但在对象形态突变、CPU quota 收紧、峰值流量、批任务叠加、容器内存吃紧时,退化方式完全不同。有的 collector 更容易表现为 pause 变长,有的更容易表现为并发阶段抢 CPU,有的更容易表现为 RSS 头寸紧张。真正成熟的比较,是比较“当它不再完美时,系统会以什么方式变坏”,因为生产真正面对的往往就是这些不完美窗口。
最后,collector 的选择还应与未来路线相关。比如某个服务今天只是普通在线服务,但预期未来会有更大堆、更高尾延迟要求、更严格多租户隔离,那么团队也许需要提前建立低停顿 collector 的观察能力;反过来,如果某类服务未来会被拆成更小的容器单元、转向更轻量的批任务,那么更简单的 collector 可能仍然更有性价比。选型不是只看今天,还要看未来一年到两年的运行轨迹。
5.1 Serial 与 Parallel:不是落后,而是目标不同
许多团队在谈 GC 选型时,会默认只讨论 G1、ZGC、Shenandoah,仿佛 Serial 和 Parallel 已经不值得提。但从生产工程角度,这恰恰是危险的,因为它会让团队误以为“现代 collector 一定全面更好”。实际上 Serial 和 Parallel 的价值从来没有消失,只是它们适用的目标不同。
Serial 的定位非常明确:实现简单,适合资源极少、堆很小、单核或极低并发环境,或者某些启动型、工具型、小型任务型进程。它当然不适合大多数高并发服务,但在体量很小的任务里,复杂并发回收协议带来的收益可能并不值得。
Parallel GC 的核心诉求则是吞吐优先。它接受较大的 stop-the-world 暂停,用更多并行 worker 在暂停窗口内完成回收,从而让业务在长时间尺度上得到更多有效 CPU。对于离线批处理、可接受明显暂停但追求总处理效率的任务,这个目标非常合理。问题不是 Parallel “过时”,而是团队常常把它用错到低延迟在线服务里,然后又抱怨 pause 太长。
5.2 G1:通用服务默认起点,但不是“默认就不用看”
G1 成为许多现代 JDK 服务的默认起点,不是因为它在所有场景里都最优,而是因为它在通用服务场景中提供了相对平衡的折中:region-based heap、可预测的暂停目标、对中大堆的适应性、成熟的日志和生态、对绝大多数 Web/RPC/业务服务都足够友好。很多团队真正需要的,不是立刻上 ZGC,而是先把 G1 用对。
但“默认起点”绝不意味着“默认安全”。G1 的危险之处在于太多人因为它是默认,就以为不需要理解它的回收收益、remembered set 成本、mixed collection 质量、humongous object 风险和 pause target 的边界。实际上,G1 误用比 collector 切换更常见。典型误区包括:把 MaxGCPauseMillis 当绝对承诺、忽略 Old 区回收收益、忽略 remembered set 扫描成本、忽略大对象布局对 region 使用方式的影响、在容器 CPU 受限时误判 GC worker 行为。
如果团队还没建立稳定的 GC log 与 JFR 证据链,G1 往往应该是第一站,而不是跳板。因为 G1 的问题更容易被观察和解释。换句话说,先把通用 collector 用明白,通常比盲目追逐更先进 collector 更划算。
5.3 ZGC:低停顿导向,但不是“切换后万事大吉”
ZGC 的核心吸引力在于把 pause 与 heap size 的强耦合降到更低,通过 colored pointers、load barrier、并发标记和并发重定位,让大堆服务更容易把 GC pause 压在较短区间内。对于大堆、严格尾延迟要求、愿意接受额外并发与屏障成本的在线服务,ZGC 确实是一个强有力的候选。
但 ZGC 不应该被写成“只要低延迟就上”的口号。首先,它仍然受 CPU、内存带宽、分配率和对象生命周期影响。其次,低停顿并不自动等于低端到端延迟,如果真正的瓶颈在业务排队、数据库、锁竞争或流量峰值,切换 ZGC 可能只是把症状推迟。再次,ZGC 的观测和调试思维与 G1 不同,团队必须愿意维护对应的知识和运行经验。最后,版本边界必须说清:从 JDK 15 起它是 product;从 JDK 21 起有 Generational ZGC;从 JDK 23 起 generational mode 成为默认;JDK 24 又移除了非分代模式。这些变化直接影响你阅读日志、理解参数和解释默认行为的方式。
因此,ZGC 更适合“明确存在尾延迟目标 + 堆规模较大 + 团队能接受并维护其运维复杂性”的场景,而不是“所有服务统一升级”的组织性动作。
5.4 Shenandoah:也是低延迟路线,但团队能力与发行版支持更重要
Shenandoah 与 ZGC 一样,属于低停顿导向 collector,但它的实现路径不同,尤其在 Brooks pointer、并发转移、屏障语义和部分阶段处理上有自己的特性。对架构师来说,选择 Shenandoah 不应只看“它也是 low pause”,而要看团队对其运行特征是否熟悉、所用发行版是否稳定支持、观察工具和故障处理经验是否具备。
Shenandoah 的一个现实工程问题是:很多团队对它的理解远少于对 G1 和 ZGC 的理解。生产里你不仅要考虑 collector 本身,还要考虑谁来读日志、谁来分析退化路径、谁来判断并发阶段是否推进正常、谁来处理版本升级后的行为变化。也就是说,团队知识和发行版支持,本身就是选型维度。
对 generational Shenandoah 的表述也必须保守。可以说它在后续 JDK 演进中出现了实验性/产品化阶段,但不要在没有精确来源矩阵时,把它写成“现代默认做法”或“与 ZGC 完全等价的替代品”。
5.5 G1、ZGC、Shenandoah、Parallel、Serial 的生产判断框架
更靠谱的选型方式,不是按“先进程度”排序,而是按业务目标、堆规模、延迟容忍度、CPU 预算、容器密度和团队操作能力排序。
| Collector | 更适合的工作负载 | 主要收益 | 主要代价 | 常见误区 |
|---|---|---|---|---|
| Serial | 小堆、小工具、低并发任务 | 简单、额外元数据少 | 暂停长,扩展性弱 | 把它用于高并发服务 |
| Parallel | 吞吐优先的批处理或离线任务 | 总吞吐高、模型简单 | STW 暂停明显 | 用于严格尾延迟在线服务 |
| G1 | 通用服务、中大堆、需要平衡吞吐与延迟 | 默认成熟、证据面丰富、折中稳健 | remembered set、mixed GC 调优成本 | 把 pause target 当承诺 |
| ZGC | 大堆、尾延迟敏感、愿意承担并发成本的在线服务 | pause 更容易控制、对大堆友好 | 屏障与并发成本、运维理解门槛 | 认为切换后所有慢请求都会消失 |
| Shenandoah | 低停顿诉求明确且发行版/团队支持充分的场景 | 低停顿路线、并发回收能力 | 团队经验门槛、发行版差异、观察复杂度 | 把它视为“另一个名字的 ZGC” |
这张表不是替代压测,而是替代 slogan。collector 选型如果不能回答“为什么这个服务是这一列而不是另一列”,那就说明还没选型,只是在模仿别人。
如果还要再往前一步,架构师最好把每类 collector 的“失败姿态”也提前写出来。因为生产中真正昂贵的,往往不是平时表现,而是当 collector 碰到边界时,系统会怎样退化。G1 的典型退化姿态往往是 mixed reclaim 质量下降、humongous object 压力增加、Old 区回收后不再回到基线、pause target 逐渐失守,最终在极端情况下出现 Full GC 或 evacuation 相关压力。ZGC 的退化姿态更多表现为并发阶段跟不上分配速率、CPU 被并发回收持续消耗、allocation stall 风险提高、tail latency 虽然不一定有长 pause,但整体系统变“闷”。Shenandoah 则要重点关注退化路径是否被触发以及团队是否真的理解这些退化路径对业务意味着什么。Parallel GC 的失败姿态最直白,就是 STW 停顿明显增长;Serial 则会在并发和堆规模上快速触顶。
把失败姿态写出来有两个好处。第一,它会逼迫团队承认 collector 并不是“成功/失败”二元状态,而是以不同方式接近边界。第二,它能帮助运维提前布告警。若团队知道 G1 的主要风险信号是什么,就可以围绕 Old after GC、humongous event、mixed reclaim、Full GC 建立观察;若知道 ZGC 风险更偏并发推进和 CPU 头寸,就应该围绕 allocation stall、并发阶段耗时与容器 CPU 余量做监控。告警如果不跟 collector 的失败姿态对齐,就只是数据堆积。
此外,collector 的组织适配性也应当纳入框架。比如有些公司平台层面对 G1 的仪表板、日志解析、报警和经验已经比较成熟,那么除非业务目标明确证明需要 low-pause collector,否则贸然切换的组织成本可能高于技术收益。反过来,若组织已经有多支低延迟团队、灰度体系完善、JFR 与日志解读能力成熟,那么更激进的 collector 试验就更可行。换句话说,同一工作负载在不同组织中,collector 的“适配度”并不完全相同,因为运行时能力并不只来自 JVM,还来自团队。
最后,collector 选择还应服从平台演进节奏。不是每个团队都需要在最新 feature release 上探索新 collector 行为,也不是每个团队都应当永远停留在最熟悉的 LTS 配置。好的平台规划通常会同时维持几条轨道:生产稳定轨、下一版评估轨、兼容性验证轨和实验轨。collector 选型应该落在这些轨道里,而不是单点拍板。这样即使需要切换,也是在治理体系中切换,而不是在事故中切换。
如果要把 collector 选择进一步沉淀成组织规范,最有价值的不是写一份“最终推荐 collector 列表”,而是写一份“进入某 collector 路线前必须具备的前提”。例如进入 low-pause collector 路线前,团队是否已经具备稳定 GC logs、JFR、container metrics、灰度环境、回滚机制、对象分配画像,以及对应的值班解释能力。没有这些前提,即使技术上 collector 更先进,组织上也未必能承接它。这样的规范比“统一用什么 collector”更难写,但长期效果更好。
还可以把 collector 评审模板制度化。每次有人提出 collector 切换或关键 GC 参数变更时,必须回答固定问题:目标是什么、证据是什么、替代方案是什么、预期收益是什么、代价是什么、灰度与回滚怎么做、稳定运行多久才算通过、结论适用哪些服务、哪些服务不适用。这种模板会让 collector 决策从“高手经验”变成“组织流程”,也能显著减少因为个人偏好导致的路线摇摆。
在很多企业里,最难的不是第一次做 collector 评审,而是如何让评审结论变成可复用资产。一次成熟评审结束后,最好能沉淀出若干可复用的模板:什么样的服务属于 G1 默认适配面,什么样的服务需要证明 low-pause 收益,什么样的内存账本结构最容易触发容器风险,什么样的观察面必须先补齐。这些模板不应该把未来决策锁死,而应成为下一次评审的起跑线。没有这层沉淀,组织每次都会从“有人提出要不要换 collector”重新开始。
6. 调优工作流:假设、对照、灰度、回滚,而不是一次性大改 JVM flags
真正高质量的 GC 调优,往往看起来没有那么“激进”。它不像论坛帖子里那样一次改十几个参数,也不像某些事故处理那样连 collector 一起换掉。它更像严谨的工程实验:先把问题写窄,再确定验证方式,再小步变更,再收集可对照结果,最后明确保留、回滚或继续试验。之所以强调流程,是因为 GC 变更的 blast radius 很大,任何一次没有控制好的试验,都可能把业务抖动扩大成发布事故。
这个流程还有一个隐藏收益:它会反向提高团队对业务对象生命周期的理解。很多时候,GC 调优一路做下来,最终最有价值的结论不是“某个 flag 更好”,而是“这个接口创建了过多短命对象”“这个缓存没有明确上限”“这个批处理把对象持有时间拉长了”“这个容器 limit 配置从一开始就不合理”。如果没有调优流程,这些对象治理问题往往不会被系统地说出来,因为团队一直停留在 collector 层面打转。
架构师在调优流程中还有一项经常被忽视的职责:定义试验退出条件。不是所有问题都值得持续优化,也不是所有 collector 都值得继续试。若某个参数只带来微弱收益,却显著增加团队理解成本;若某个 collector 只在压测中看起来好,却让灰度观测和故障解释更困难;若某次优化改善了 pause 却恶化了 CPU 与成本,那就应该有勇气终止试验,而不是因为已经投入精力而继续加码。优化本身也需要止损纪律。
另一个非常现实的问题是,GC 调优必须嵌入发布治理。很多事故复盘里都能看到这样一幕:参数已经改完,但发布说明只写了“优化 JVM 参数”,没有写明假设、预期收益、回滚条件、观察指标和试验适用范围。结果值班工程师根本不知道该如何验证。把 GC 调优写成结构化变更说明,本身就是降低组织风险的重要动作。
6.1 调优不是配置艺术,而是证据实验
很多 GC 调优失败,不是因为参数本身错得离谱,而是因为整个过程像炼金术:一次性改十几个参数、改完直接上生产、业务负载没对齐、没有回滚路径、指标面也不完整,最后即使结果变差,也没人知道究竟是哪一项改动造成的。这种调优方式最大的问题不是“可能没调好”,而是根本无法学习。
一个成熟的调优工作流应该像实验。先定义症状与目标,再建立前置证据,再形成假设,然后一次只改少量变量,用同一类工作负载和同一类指标做对照,最后通过灰度观察与回滚策略把风险关住。GC 调优如果缺少这条链路,就算偶然调对,也不可复制。
6.2 先采样和复现,再开始假设
最危险的动作,是一看到告警就先改参数。正确顺序应该是:先把故障窗口里的 GC log、JFR、服务延迟分布、容器指标、CPU 指标拉出来;如果生产证据不足,再在预演环境、灰度环境或复现环境建立最小可重复工作负载。因为 GC 问题高度依赖对象分配模式和存活率,没有相似工作负载,参数实验很难有解释力。
复现不一定要做到百分百还原线上数据,但至少要还原几类关键形态:分配速率峰值、对象大小分布、典型请求并发、是否有批量缓冲、是否有大对象、是否有 burst traffic、容器 CPU/内存限制是否一致。只有这样,实验结果才有资格指导生产。
这里最容易踩的坑,是把“功能压测”误当成“GC 复现”。很多团队的预演环境只能证明接口逻辑可跑通、吞吐大致还行,却不能证明对象生命周期、批量数据形态、异常重试、缓存命中路径与线上相似。GC 对这些细节极其敏感,所以一个不具备对象形态相似性的复现环境,哪怕 QPS 看起来像线上,也很可能得出错误结论。架构师应该主动追问:我们复现的是业务请求量,还是复现了对象生命周期与分配峰值。
另一个关键点是,复现并不只服务 collector 变更,也服务对象设计变更。很多时候,你最终发现最有效的优化并不是 JVM 参数,而是缩短对象持有时间、减少中间集合、拆分批量、按页处理、调整序列化方式、或把某些缓存移到更合适的层。没有可重复的复现环境,这些应用层面的改动很难和 collector 层面的改动做公平比较。
从项目治理角度看,复现环境最好还能保留“实验元数据”。也就是说,每次 collector 或参数试验都不只是跑一下压测,而是留下运行镜像、JDK 版本、容器限制、数据样本、流量脚本和关键指标截图或原始数据。没有这些元数据,几周之后再回头看,团队往往只记得“那次好像验证过”,却已经无法确认是在什么前提下验证过。GC 相关结论如果不能复用到未来版本升级和相似服务上,它的组织价值会被大幅削弱。
很多团队在这一点上吃过亏:一次 collector 试验在某个压测环境中成功,于是结论被当作组织共识沿用;几个月后同样的 collector 在另一个服务里表现很差,大家却已经无法还原第一次成功的环境前提。是 CPU 配额不同、对象大小分布不同、租户行为不同,还是容器 budget 不同?如果没有元数据,所有讨论都会滑向“印象派”。GC 试验看似是运行时优化,其实和科学实验一样,最怕没有实验上下文。
6.3 从“假设”组织参数,而不是从“参数表”组织假设
好的调优从假设开始,坏的调优从参数表开始。比如你观察到 Young GC 频率很高、但每次回收都很快,且业务延迟正常,那假设可能是“高分配率是业务特性,不构成问题”;这时候就不该为了“让 GC 次数变少”而盲目调大年轻代。相反,如果你观察到 mixed GC 回收收益很低、Old 区持续增长、heap dump 显示大量缓存对象长期存活,那假设就应该优先指向对象生命周期或缓存治理,而不是 collector 参数。
只有当假设已经指向 collector 行为边界时,参数才有意义。例如 G1 里你可能要验证 pause target 是否过于激进、是否有 humongous pressure、是否需要重新审视 heap reserve 与对象布局;ZGC 里你可能要验证并发阶段是否跟得上分配速率、CPU 是否足以支撑并发线程;Shenandoah 里你可能要验证并发转移是否稳定推进。参数是验证假设的工具,不是替代假设的快捷键。
6.4 collector-specific tuning 也必须服从统一流程
很多人误以为统一流程只适合通用问题,collector-specific tuning 则可以直接查官方建议。实际上越是特定 collector 的参数,越不能脱离统一流程,因为这些参数往往更强地依赖工作负载。
G1 的 pause target、IHOP、年轻代比例、humongous 风险、mixed GC 回收收益,本质上都受分配速率和对象生命周期影响。ZGC 的 headroom、并发线程推进、allocation stall 风险,也离不开 CPU 配额和峰值分配行为。Shenandoah 的退化路径和版本支持,更不能脱离具体发行版和团队观察能力。换言之,collector 变了,流程不能变;变的是你要关注的证据细节。
6.5 灰度、回滚与持续观测是调优闭环的一半
GC 变更属于基础运行时行为变更,风险级别高于多数业务配置修改。无论是 collector 切换,还是关键参数调整,都应该被当作灰度发布对象,而不是普通部署的一部分。你必须提前准备好回滚条件,例如 p99/p999 变差多少、RSS 增长到什么水平、CPU 高于什么阈值、错误率是否抬升、某些 collector 特定事件是否出现。
持续观测也不能只盯着“改后 GC pause 变短了”。真正需要追踪的是:业务吞吐有没有改善、尾延迟有没有收敛、容器密度有没有提升、CPU 成本有没有上升、Full GC 是否消失、老年代回收后是否稳定、是否引入新的异常波动。只看 collector 自己的好转,是非常典型的局部最优陷阱。
6.6 最小调优实验模板
场景:做单变量 GC 试验。原因:避免多变量混杂。观察点:延迟、吞吐、RSS 与 phase。生产边界:仅作实验骨架。
experiment:
hypothesis: "G1 mixed GC 回收收益下降与 humongous allocation 增加有关"
baseline:
jdk: "25.0.x vendor-build"
collector: "G1"
workload: "peak-like replay"
change:
type: "single-variable"
variable: "object layout and batch size"
observe:
- p99_latency
- throughput
- rss
- gc_pause
- old_after_gc
- humongous_events
rollback_when:
- "p99 regress > 10%"
- "rss grow > 15%"
- "full_gc appears"这个模板最重要的不是字段齐不齐,而是强制团队回答三个问题:你改的到底是什么、你用什么证明它有效、你在什么条件下承认它失败并回滚。
7. G1、ZGC、Shenandoah、Parallel、Serial 的选择与误区
进入这一节后,很多读者最容易产生的冲动,是寻找一张“最终推荐表”。但现实世界里最有价值的,不是被别人告诉“你应该选哪个”,而是学会如何在评审会上问出正确问题。比如:当前服务的故障主要表现在哪个目标维度;团队有没有持续可用的 GC log 与 JFR;容器预算是否已经算清;有没有小规模实例可以灰度;是否存在必须在数分钟内回滚的强约束;团队是否能够理解目标 collector 的异常窗口行为。只要这些问题没有被回答,再漂亮的 collector 推荐都只是技术叙事。
误区往往也不是出现在“collector 名称选错”这一瞬间,而是出现在解释框架一开始就偏了。例如把“更现代”当成“更适合”,把“官方支持”当成“组织能运营”,把“压测 pause 更小”当成“线上业务更安全”,把“别人已经切换成功”当成“我们的工作负载也适合”。这些都是很容易让技术评审失真的语言。架构师如果不能主动把评审语言改成目标、证据、风险和退化模式,collector 讨论就会迅速滑向口号战。
还有一个值得强调的点是,collector 的误区往往具有路径依赖。团队如果过去几年长期依赖“出问题就扩堆”“延迟高就调 pause target”“内存紧就换 low-pause collector”,那新的 collector 进入后,这些旧习惯大概率仍会被套用到新 collector 上。换句话说,collector 变了,误用方式未必变。真正要改变的是判断框架,而不是只更换工具。
7.1 G1 的正确问题:是否已经把通用服务的平衡点用明白
G1 的最大价值,在于它足够通用、足够成熟、足够容易建立团队共识。对大多数业务服务而言,问题通常不在“G1 太差”,而在“团队从未真正用证据理解过 G1”。如果一个服务使用 G1 时已经表现出稳定吞吐、可接受尾延迟、良好的 heap 回落和合理的容器预算,那没有必要为了“追求更现代”而强行换 collector。
G1 的典型误区包括:只盯 pause 而忽略 Old 区回收收益;看到 humongous 就只会调堆;把 MaxGCPauseMillis 当作承诺;在容器 CPU 很紧时仍默认把 GC worker 当作无限资源;忽略 remembered set 带来的额外成本。这些误区背后其实都是同一个问题:把 G1 当黑箱。
7.2 ZGC 的正确问题:低停顿收益是否真的覆盖并发成本
ZGC 适合的不是“所有低延迟服务”,而是那些已经明确证明 pause 风险是核心矛盾、堆规模较大、尾延迟敏感、并且有足够 CPU headroom 去支付并发成本的服务。如果一个服务主要瓶颈在下游数据库、锁竞争或应用对象设计,换 ZGC 很可能看上去很先进,实际却收益有限。
ZGC 的典型误区是把“pause 更短”理解成“端到端延迟一定更低”。这在工程上几乎从不自动成立。因为业务延迟还取决于请求排队、连接池、网络、线程调度、数据结构和缓存命中。真正正确的提问方式是:在当前工作负载和容器预算下,ZGC 缩短的 pause 是否正好打中了我们最贵的尾部风险。
7.3 Shenandoah 的正确问题:组织能否稳定运营它
Shenandoah 常常在技术讨论里被简化成“另一种低停顿选择”,但对生产组织来说,更实际的问题是:你所在的发行版是否稳定支持、团队是否读得懂它的日志和退化路径、压测和灰度是否覆盖了对应模式、升级 JDK 后是否有人负责重新验证。很多时候,Shenandoah 技术上并非不可行,真正的问题出在组织运营能力不足。
因此,如果团队对 ZGC 和 G1 都还没建立稳定证据链,就不要轻易把 Shenandoah 当作“换个 collector 也许更好”的探索方向。collector 不是试错玩具,尤其对关键业务而言更不是。
7.4 Parallel GC 的正确问题:业务是否接受暂停换吞吐
Parallel GC 经常在现代讨论里被不公平地排除,仿佛它天然不适合生产。事实上,对于吞吐优先、离线批处理、总体 wall-clock 时间比瞬时停顿更重要的任务,Parallel GC 仍然可能是非常理性的选择。它的逻辑很直接:在暂停中并行做更多回收工作,把更多 CPU 留给整体完成速度。
Parallel GC 的误区不是“它过时”,而是把它放进尾延迟敏感服务后再去抱怨暂停长。任何 collector 都要为目标负责,Parallel GC 只是非常明确地把目标设在吞吐一侧。
7.5 Serial GC 的正确问题:进程是否足够小、足够简单
Serial GC 在大多数现代服务里不会是首选,但它并没有消失。小型工具、CLI 任务、启动期短、资源极小、单核环境或某些轻量作业里,复杂 collector 额外带来的元数据和并发成本未必有意义。Serial 的核心不是“技术落后”,而是“目标明确”。如果你的进程本来就不需要高并发或大堆,它可能反而更干净。
7.6 不要把 collector 选型写成组织口号
架构治理中最危险的做法之一,是把某个 collector 上升为组织级口号,比如“以后统一 ZGC”“所有服务都用 G1”“新服务必须 low-latency collector”。这类口号在管理上看似高效,实际上会把工作负载差异、容器预算差异、业务 SLO 差异全部抹掉。真正成熟的治理方式,应该是规定证据门槛和灰度流程,而不是规定唯一 collector。
换句话说,组织应该统一的是“怎么证明该选它”,而不是“大家都选它”。
8. 生产 runbook:当怀疑 GC 时,团队应该怎么执行
runbook 的价值,不在于把所有诊断知识写成百科,而在于在最混乱的时刻给团队一个共同顺序。值班工程师、应用开发、平台工程师和 SRE 在事故窗口里关注点天然不同,如果没有统一步骤,团队很快就会变成多线程混战:有人先改参数,有人先扩容,有人先抓 dump,有人只盯 Grafana,有人坚持这是数据库问题。runbook 的作用,就是用顺序把这些动作重新排队。
一个好 runbook 还应该明确角色分工。谁负责锁定故障窗口,谁负责导出 GC log 和 JFR,谁负责核对容器事件与 cgroup 指标,谁负责比对业务延迟与错误率,谁负责决定是否需要灰度 collector 变更,谁负责准备回滚。很多技术团队在平时觉得这些分工“没必要写”,但事故里一旦没有分工,时间就会被浪费在反复确认和重复劳动上。
runbook 还应该要求产出最小证据包,而不是只要求“问题解决”。因为很多 GC 相关问题都不是一次性修复,它们会在未来以相似但不完全相同的方式再次出现。如果这次排查没有留下结构化证据和结论,下次团队又会从零开始。所谓结构化证据,不一定是复杂报告,可能只是统一格式的窗口时间、collector、症状分类、核心日志片段、JFR 结论、容器预算结论、回滚条件和最终决策。关键在于别人之后还能读懂。
另外,runbook 也要内置“停止线”。不是每次怀疑 GC 都必须深入到 dump 和参数实验。若前两轮证据已经明确表明主因不在 GC,就应该停止继续在 GC 方向上投入排查成本,并把精力转回真正的问题。没有停止线的 runbook,会让团队在错误方向上越走越深。
8.1 第一步:先确认故障窗口与业务症状
生产 runbook 的起点永远不是 JVM 参数,而是故障窗口。你必须先回答:问题发生在什么时候、持续多久、影响了哪些实例、是否只出现在某一类请求或某个 AZ、是否与流量峰值、发布窗口、下游抖动同步。没有这个窗口,所有 GC 分析都会失去时间坐标。
在这个阶段,团队应该收敛出两个最关键的信息:第一,业务症状到底是什么,例如 p99 超时、吞吐下降、OOMKill、CPU 升高;第二,症状是在瞬时爆发还是缓慢积累。瞬时爆发更像暂停、分配突刺、峰值竞争;缓慢积累更像 leak、缓存膨胀、native memory 增长或持续回收收益恶化。
8.2 第二步:提取同窗口内的 GC log、JFR、容器与业务指标
第二步的动作,是把故障窗口里的 GC log、JFR、延迟分布、错误率、RSS、heap、CPU、线程数、连接池/线程池指标放在一起。注意,这一步的关键不是“抓更多数据”,而是保证同一个时间窗口对齐。不同时间段拼接出来的证据,很容易制造假相关。
如果当前实例没有 JFR 或日志,只能说明 observability 还不够,而不能说明 GC 不是问题。此时要做的不是拍脑袋调参,而是先补上后续可复现的采证能力。
8.3 第三步:判定 GC 是主因、共同因素,还是旁观者
这是 runbook 中最关键也最容易跳过的一步。你必须在证据层面回答:GC 是主因、共同因素,还是旁观者?
主因意味着:GC 事件本身足以解释业务症状,例如 Full GC、明显 pause、allocation stall、回收跟不上导致的持续抖动。共同因素意味着:GC 在系统压力中起了放大作用,例如业务本就接近极限,GC 再把尾部推过 SLA。旁观者意味着:GC 看起来很忙,但根因其实在业务或系统其他部分,比如缓存失控、慢 SQL、锁竞争、线程池耗尽、native memory 泄漏。
只有把这一步说清,后面的动作才不会跑偏。否则团队最容易陷入“看到 GC 有动作,就开始调 GC”。
8.4 第四步:确定是分配问题、存活问题、暂停问题,还是容器预算问题
即使已经确认 GC 参与了症状,也还要继续细分。因为 GC 相关问题不等于“collector 参数问题”。它可能是分配速率太高、对象存活太久、某阶段 pause 过长、humongous allocation 过多、Old 区回收收益低、容器预算错误、native memory 撑爆,或者几个问题叠加。
这一步决定是否要往代码层面追对象生命周期,还是往 collector 行为层面调策略。许多真正昂贵的事故,都是因为团队在这一步偷懒,导致后续所有参数变更都在替代真正需要的对象治理。
8.5 第五步:形成小步假设并准备回滚
当问题已经被细分到足够具体时,才进入参数或 collector 变更。无论你是修改 G1 相关设置、切换到 ZGC、重新规划 heap 与容器 limit,还是缩减大对象批次、调整缓存策略,都必须把回滚条件写清楚。生产上没有“先改了再看”的空间,尤其 collector 切换属于高风险动作。
8.6 第六步:灰度发布后只盯关键指标
灰度时不要看一切,重点盯少数关键指标:p95/p99/p999、吞吐、错误率、CPU、RSS、GC phase、回收后 Old 占用、Full GC 或特定 collector 告警是否出现。盯的东西越多,越容易失焦;盯的维度越偏 collector 本身,越容易忽视业务端效果。
更进一步说,灰度指标最好按“业务结果”“运行时成本”“回滚信号”三类分层。业务结果回答这次变更是否真的改善了用户体验或任务完成效率;运行时成本回答这次变更是否只是把 pause 换成了 CPU 或 RSS 成本;回滚信号回答一旦 collector 路线错误,团队能多快发现。把指标分层之后,值班和评审时就不容易陷入“图太多,但不知道哪张最重要”的状态。
灰度窗口的长度也需要根据问题类型调整。对冷启动和立即生效的问题,短窗口可能足够;对缓存膨胀、native memory 增长、稳态对象存活、租户偏斜这类慢变量问题,灰度窗口过短会制造假安全感。很多 collector 变更之所以在线上二次翻车,就是因为第一次灰度只覆盖了部署后最平稳的一段时间,没有覆盖真正的稳态压力。
8.7 第七步:复盘时记录“为什么不是别的问题”
成熟的 GC 复盘,不只记录“最终怎么改”,还要记录“为什么排除了其他方向”。例如为什么不是数据库慢查询、为什么不是线程池耗尽、为什么不是 direct memory、为什么不是 classloader leak。这样的记录才会帮助团队下次更快区分 GC 主因和伴生噪声,而不是重复走弯路。
这类复盘之所以重要,是因为 GC 事故往往有很强的叙事惯性。第一次排查结束后,团队容易把结论简化成一句口号,例如“这次是 G1 不适合”“这类服务都该换 ZGC”“以后堆要统一加大”。如果没有保留“为什么排除其他方向”的证据,下次相似事故出现时,这句口号就会被当成现成答案,反而压制新的判断。结构化记录排除链,可以迫使团队每次都重新尊重证据,而不是重用旧印象。
复盘记录还应该明确哪些结论只对当前工作负载成立。例如某次事故中,ZGC 在大堆低延迟服务里带来明显收益,这并不等于同组织的离线批处理也该切换;某次事故中,扩大 direct memory 上限后 OOMKill 消失,也不等于所有容器都该同步扩大非堆预算。把结论的适用范围写清楚,是防止“局部胜利故事”被平台误推广的关键。
另一个经常被忽略的复盘点,是证据缺口本身。若这次故障之所以花了很久才判断,是因为 GC logs 太短、JFR 没有保留、容器事件和 JVM 指标对不上、团队不清楚当前实际 collector 或 flags,那这些缺口就应该进入整改项。很多组织会把精力都放在“参数怎么改”,却不修 observability 缺口,结果下一次又在同一个盲区里跌倒。
复盘中还应当显式记录“这次没有做什么”。例如没有立刻切换 collector、没有直接扩大堆、没有先抓大型 heap dump、没有在无灰度条件下动生产参数。这类“没做”的动作看似平淡,其实能够保护系统免于更大风险。把这些克制也写进复盘,有助于组织形成正确的事故处理文化:不是动作越多越专业,而是顺序越对、证据越完整、回滚越明确才越专业。
如果组织已经比较成熟,复盘里还可以增加“知识更新项”。例如本次事故是否纠正了团队对某个 collector 的旧认知,是否暴露了某个模板假设已经过期,是否需要在平台培训中加入新的 RSS/heap 区分案例,是否需要修改默认 JFR 保留策略。这样一来,复盘就不只是解释过去,还能主动提升未来的 collector 运营能力。
8.8 最小 runbook 操作片段
场景:线上先做最小取证。原因:避免各自为战。观察点:flags、heap、短窗 GC 节奏。生产边界:受实例权限与白名单约束。
jcmd <pid> VM.flags
jcmd <pid> GC.heap_info
jstat -gcutil <pid> 5s 12这些命令不能直接替代完整分析,但足以在 runbook 第一轮里建立最基础的问题轮廓:当前跑的到底是什么 collector、堆的大体状态如何、短时间内 GC 使用率和回收节奏是否异常。
9. 常见误判与反模式:GC 往往不是被调坏,而是被看错
反模式之所以值得单独写,不是为了做道德评判,而是因为 GC 相关错误大多不是缺乏知识,而是因为人在压力下会自动选择最快、最熟悉、最显眼的解释。GC 恰好又是 JVM 中最显眼的一块:它有日志、有暂停、有图表、有 collector 名称。因此当系统抖动时,它天然比对象生命周期、direct memory、线程池、慢 SQL、压缩库、classloader retention 更容易被看见。很多误判就是这样产生的。
这些误判还有一个共同特点:它们往往在局部证据上“说得通”。比如延迟高时日志里确实有 pause,内存高时 heap 图确实在上涨,吞吐下降时 GC 次数确实更多。问题在于,局部相关并不代表主因判断正确。架构师的职责不是否认这些现象,而是把它们放回完整系统时序中重新解释。也正因为如此,反模式训练本质上是一种判断力训练,而不是 collector 知识背诵。
从团队能力建设角度看,反模式还可以用来设计复盘模板。每次 GC 相关事故结束后,都可以反问几个固定问题:我们有没有过早把 GC 当主因;有没有忽略容器预算;有没有只看平均值;有没有复制经验参数;有没有把 collector 切换当结果而不是手段;有没有留下足够证据让下次更快判断。长期坚持这组问题,团队会比单纯增加更多参数知识更快成熟。
9.1 只看平均暂停,不看尾延迟
这是最典型的反模式。平均暂停很好看,不代表 p99/p999 也好看。对于在线服务而言,真正影响 SLA 的往往是少量长尾事件与系统排队叠加后的放大效应。如果团队持续用平均值讲故事,最终一定会错过最贵的问题。
9.2 一见 OOM 就扩大堆
扩大堆有时是必要动作,但如果在没有区分 heap OOM、Metaspace、direct memory 和容器 OOMKill 之前就扩大堆,往往只是把问题藏久一点,甚至让 RSS 更快撞 limit。架构师应该先判断“谁在涨”,而不是默认“堆太小”。
9.3 复制网上 JVM flags
网上的参数清单最大的问题,不是它们一定错误,而是它们脱离了工作负载、JDK 版本、硬件和容器环境。你在别人的系统里看到某个参数有效,不代表在自己的对象生命周期和 CPU 预算下也有效。更糟的是,许多参数建议本身来自早期 JDK 或过时 collector 语境,在新版本里已经失去原有意义,甚至会与默认策略冲突。
9.4 把业务慢查询、锁竞争或线程池排队误判为 GC
GC 是一种非常显眼的运行时事件,所以它很容易成为背锅对象。只要看到日志里恰好有一段 pause,团队就会天然相信“就是它”。但生产中更常见的情况是:系统已经因为锁竞争、线程池排队、下游超时或慢查询接近饱和,GC 只是恰好在这个窗口增加了压力。如果不把线程、I/O、数据库和 tracing 一起看,误判几乎是必然的。
9.5 把容器 OOM 当成 Java heap OOM
容器被杀并不需要 JVM 先抛出 OutOfMemoryError。如果团队不看 cgroup 指标、RSS 和 native memory,而只看 Java heap usage,就会形成一种危险错觉:明明 heap 还没满,为什么 pod 会死?答案往往就是堆外预算根本没算。
9.6 把 collector 切换当作“问题解决”
有些团队一切换 collector,图表短期变好,就宣告问题解决。但工程上更严谨的说法应该是:collector 切换改变了系统的回收行为,是否真正解决了业务目标,还要看吞吐、尾延迟、容器密度、CPU 成本、发布稳定性和回滚复杂度。collector 切换是手段,不是胜利本身。
9.7 把“经验百分比”当成工程定律
例如“direct memory 大概只会占 heap 的多少”“某 collector 在大堆一定更好”“某个 pause target 设成多少最合理”,这些说法在讨论时可以作为经验起点,但绝不能当工程定律。生产的本质就是上下文,而经验只能在上下文里成立。
还有一种更隐蔽的反模式,是把“别人已经踩过的坑”理解成“我们可以跳过验证”。经验当然有价值,但经验真正的价值在于帮助你更快形成假设,而不是帮你取消实验。比如别人告诉你某类低延迟服务在大堆下更适合 ZGC,这可以成为你优先测试 ZGC 的理由,却不能直接成为线上切换理由。任何把经验直接当结论的做法,最终都会在自己独特的工作负载、容器限制或团队能力面前付出代价。
另一个需要长期警惕的反模式,是把问题命名得过于宽泛。像“GC 顶不住了”“JVM 不行了”“Java 内存就是大”这类表达,听起来像结论,实际上没有任何工程可执行性。成熟团队会逼自己把语言写窄:是 Young GC 频率异常、Old 区 post-GC 不回落、humongous allocation 过多、allocation stall 触发、容器 RSS 预算不够,还是 direct memory 看不见。语言越窄,动作越准;语言越宽,反模式越容易反复出现。
9.8 把 GC 治理做成平台资产,而不是专家口头经验
如果一个组织的 GC 能力主要依赖少数 JVM 专家临场判断,那么它在小规模团队里可能勉强可用,但在多业务、多租户、多 JDK 版本、多容器规格的企业环境里一定会逐渐失效。专家经验最容易丢失的部分,往往不是“知道某个参数名”,而是“知道什么时候不该改参数”“知道一个症状背后可能有三个系统层原因”“知道某个 collector 在当前团队能力下运营成本过高”。这些经验如果只存在于聊天记录、事故群和个人脑子里,就无法变成组织能力。
更可持续的做法,是把 GC 治理沉淀成平台资产。第一类资产是术语和指标字典,明确 pause、safepoint、allocation rate、post-GC occupancy、RSS、native memory、direct buffer、Metaspace、container working set 等词在公司内部的含义。第二类资产是采证模板,规定 GC log、JFR、容器事件、业务延迟、线程 dump、pool 指标应该如何按同一时间窗口收集。第三类资产是变更模板,规定 collector 切换、heap 调整、容器 limit 调整、direct memory 上限调整必须写清目标、假设、回滚条件和观察窗口。第四类资产是复盘库,把典型事故按“症状、误判、证据、真实原因、修复动作、适用边界”归档。
这些资产的价值,在于让普通团队也能沿着正确路径前进,而不是每次都等待专家介入。平台资产不是要消灭专家,而是把专家判断中可以重复的部分产品化,把必须由专家判断的部分留在更高价值的位置。比如某次 collector 切换是否值得做,仍然可能需要资深工程师判断;但“切换前应该采哪些证据”“灰度时看哪些指标”“失败时怎么回滚”不应该每次重新发明。
9.9 容器预算要从服务画像开始,而不是从固定比例开始
在 Kubernetes 或其它容器平台里,GC 讨论经常被简化成“Xmx 应该占 container limit 的多少”。这种讨论虽然方便,却容易制造错误安全感。真正的容器预算应该从服务画像开始:它是请求/响应服务、批处理任务、网关聚合层、消息消费者、搜索索引服务、AI SDK 调用服务,还是包含大量 native 库和 direct buffer 的混合服务?不同画像的非堆预算差异很大,线程栈、TLS、压缩库、Netty buffer、JNI/FFM、class metadata、code cache、profiling agent、sidecar 交互都会改变 RSS。
因此,架构师在做容器预算时至少要回答四个问题。第一,heap 的增长是否真能提升业务目标,还是只会压缩 native 空间。第二,非堆预算中哪些部分随流量、连接数、类加载、批大小或租户数增长。第三,collector 自身是否需要额外元数据或并发阶段 CPU 预算。第四,容器 limit 触发时,是 JVM 能先感知并抛出错误,还是进程会直接被平台杀掉。没有这些问题,单纯谈比例就只是在用一个数字遮盖系统复杂性。
这类预算还应该进入容量评审,而不是只留在 JVM 参数文件里。很多线上事故并不是因为某个工程师不知道 -Xmx,而是因为应用画像发生了变化:一个原本轻量的 HTTP 服务引入了大批量 JSON 压缩,一个普通同步服务接入了高并发 AI SDK,一个消息消费者增加了本地缓存,一个网关开始承接更多 TLS 连接。业务功能变化改变了内存账本,但容器预算没有同步更新,最终表现为“GC 好像越来越忙”或“heap 没满但 pod 被杀”。把预算和服务画像绑定,才能让 GC 治理跟得上业务演进。
9.10 JDK 升级时不要只回归业务功能,也要回归 GC 行为
JDK 升级经常被当成兼容性工程:编译是否通过,单元测试是否通过,框架是否支持,依赖是否还有非法反射或已移除 API。对 GC 来说,这些远远不够。不同 JDK 版本可能改变默认 collector、改进或移除某些模式、调整日志格式、改变容器识别行为、优化并发阶段、引入新的诊断字段,甚至让旧经验不再适用。业务功能通过,只能说明应用还能跑;GC 行为回归通过,才能说明运行时边界仍然可信。
一个可靠的 JDK 升级 GC 回归,至少应该覆盖三类证据。第一是静态事实:当前 JDK、发行商、容器镜像、默认 collector、关键 flags、GC 日志配置和 JFR 配置。第二是基线对比:同一 workload 下的 allocation rate、pause 分布、post-GC occupancy、RSS、CPU、Full GC 或 collector 特定事件是否发生结构性变化。第三是诊断可用性:原有 dashboard、日志解析、报警规则、runbook 命令和 JFR 分析流程在新版本下是否仍然可用。很多团队升级后才发现日志字段变了、告警失效了、旧脚本解析不了,这些问题本质上也是生产风险。
升级评审还应该避免一个常见误区:看到新版本某项 GC 能力更强,就默认应该改变 collector 或参数。JDK 升级本身已经是运行时变更,如果同时叠加 collector 切换、heap 调整、容器 limit 修改和业务版本发布,事故发生后很难归因。更稳妥的路径是先完成最小升级并冻结 GC 变量,再按证据逐步评估是否需要利用新能力。升级不是一次把所有运行时愿望打包实现的机会,而是一次重新确认契约边界的过程。
9.11 典型案例:延迟尖刺、容器 OOMKill 与 Full GC 突增应该如何分流
为了让上面的原则更可执行,可以把三类常见事故放在一起看。第一类是延迟尖刺。正确入口不是“哪种 collector 更低延迟”,而是先把业务 p99/p999、GC pause、safepoint、线程池排队、下游 RTT 和 retry 时间线叠在一起。如果尖刺只和某类请求、某个租户或某个批量路径相关,优先怀疑对象生命周期、下游排队或请求 fan-out;如果尖刺和特定 GC phase 高度重合,再继续细看 pause 类型和 collector 状态。这样可以避免把所有尾延迟都推给 GC。
第二类是容器 OOMKill。正确入口不是“把堆调小还是调大”,而是先判断 JVM 是否抛出了 OutOfMemoryError,容器事件是否显示 cgroup kill,RSS 与 heap used 是否背离,direct memory、thread count、Metaspace、native library、agent 和 sidecar 是否有变化。如果 heap 正常而 RSS 上升,继续扩大 heap 通常会恶化问题;如果 heap post-GC 持续不回落,才更应该进入对象存活和泄漏排查。这里最关键的是区分“JVM 认为自己没死”和“平台已经把进程杀掉”这两种完全不同的失败语义。
第三类是 Full GC 突增。正确入口不是立刻换 collector,而是先确认 Full GC 的触发原因:是 allocation failure、promotion failure、metadata pressure、humongous allocation、explicit GC、class unloading 压力,还是某些容器预算和 ergonomics 交互造成的边界问题。不同触发原因对应完全不同的修复路径。对象存活过长需要找生命周期;humongous allocation 需要看对象尺寸和批处理;显式 GC 需要看库和运维脚本;metadata pressure 需要看类加载和动态生成。把 Full GC 当成单一现象,会让团队在错误方向上调参。
9.12 组织能力成熟度:从救火到标准化,再到主动预防
GC 治理可以按组织成熟度分三层。第一层是救火型,只有事故发生时才关注 GC,平时没有统一日志、没有 JFR 保留、没有容器内存账本、没有 collector 评审。这个阶段最需要的不是复杂优化,而是建立最低限度的可观测性和 runbook。第二层是标准化型,团队已经有默认 GC log、JFR、dashboard、容器预算模板、参数变更流程和复盘规范。这个阶段的重点,是把不同服务画像和 collector 策略绑定,避免一个模板套所有服务。第三层是主动预防型,平台能在容量评审、JDK 升级、服务画像变化、依赖引入和发布灰度中提前发现 GC 风险。
从救火到预防的关键转变,是把 GC 从“事故响应主题”变成“架构评审主题”。比如新增本地缓存时,要问对象生命周期和 eviction 是否可控;接入 AI SDK 时,要问 streaming、buffer、TLS、JSON 和向量结果对象是否会改变内存画像;引入高并发网关功能时,要问连接、线程、direct buffer 与 heap 的预算是否同步调整;做 JDK 升级时,要问 GC 行为证据是否随版本冻结。只要这些问题能在设计阶段被问出来,很多事故就不会等到生产流量把它们暴露。
这也是 GC 文章需要有技术视野的原因。真正的生产 GC 从来不是 JVM 内部的一块孤立功能,而是应用对象设计、运行时版本、容器平台、容量规划、可观测性、事故流程和组织学习共同形成的系统能力。读者读完本文后,不应该只记住几个 collector 名称,而应该能判断:当前问题属于哪类症状,需要什么证据,什么动作会扩大风险,什么结论只能在当前 workload 中成立,什么经验应该沉淀为平台资产。做到这一点,GC 才从“调参技能”升级成“生产判断能力”。
9.13 多租户服务的 GC 风险,核心是隔离和归因
多租户系统里的 GC 问题,比单租户服务更难处理,因为对象生命周期、请求大小、缓存命中、批量操作和下游等待都可能按租户出现偏斜。一个大租户的批量导入、报表导出或大对象查询,可能让整个实例的 allocation rate 和 Old 区存活突然改变,进而影响同实例上的其它租户。此时如果只看实例级 GC 指标,团队会知道“这个 pod 很忙”,却不知道“是谁让它忙”。没有租户级归因,GC 调优就很容易变成全局加资源或全局改参数,结果让所有租户为少数异常行为买单。
多租户 GC 治理的第一原则,是把内存风险从实例维度继续下钻到租户、业务动作和数据形状。你需要知道哪些租户贡献了最大对象分配,哪些接口经常产生大结果集,哪些缓存按租户膨胀,哪些批任务会把短生命周期对象推成长生命周期对象。第二原则,是把隔离策略放在 collector 之前。限流、分页、批大小、租户级缓存上限、异步作业配额、实例分片和热点租户迁移,往往比直接改 GC 参数更有效。第三原则,是把回收压力纳入公平性治理:如果一个租户的行为让全局 GC 成本显著上升,平台应该能把成本归因给对应租户或业务动作,而不是只在 JVM 层面看到一团噪声。
9.14 大对象、序列化和 AI SDK 会让 GC 问题跨越传统服务边界
现代 Java 服务越来越多地处理大 JSON、大响应体、压缩包、向量检索结果、模型调用上下文、embedding 批次、流式 token 缓冲和工具调用审计日志。这些对象不一定都属于传统意义上的“业务实体”,但它们会真实进入 heap、direct buffer、TLS/native 层或序列化框架内部。于是团队可能会遇到一种新型 GC 现象:业务代码看起来没有明显新增缓存,数据库对象生命周期也正常,但接入某个 SDK 或某类大响应后,分配峰值、humongous allocation、直接内存、RSS 和 tail latency 同时变差。
处理这类问题时,不要把视角停留在 collector。更合适的入口是数据形状:一次请求最多产生多少中间对象,是否可以流式处理,是否可以分块解析,是否可以避免把完整响应体一次性 materialize,是否能把大对象生命周期缩短到方法栈附近,是否能把审计日志从同步路径移出,是否能限制单租户或单请求的上下文大小。对于 AI SDK 场景,还要问 token buffer、conversation memory、tool result、vector result 和 tracing payload 是否有预算。很多 GC 压力并不是“Java 回收不了”,而是系统把不必要的大对象创建成了必须回收的事实。减少对象出生,有时比优化对象死亡更有效。
9.15 给 GC 设 SLO,要同时覆盖业务、运行时和可操作性
企业里常见的错误,是只给业务接口设 SLO,却不给运行时能力设可操作目标。GC SLO 不应该写成“pause 必须低于某个固定数字”,而应该按服务类型和业务目标表达:在线交易服务关注尾延迟和错误率是否被 GC 放大,批处理服务关注吞吐和总完成时间,网关聚合服务关注排队、下游等待和对象峰值,AI 编排服务关注上下文大小、流式缓冲和模型调用等待是否引发内存波动。不同服务可以有不同 GC SLO,但都应该把业务结果、运行时成本和排查能力放在一起。
更完整的 GC SLO 至少包含三层。第一层是业务影响,例如 p99/p999、错误率、任务耗时、租户影响面。第二层是运行时信号,例如 pause 分布、allocation rate、post-GC occupancy、RSS、Full GC、collector 特定告警。第三层是可操作性,例如事故窗口内是否能拿到 GC log、JFR、容器事件和业务 timeline,是否有明确回滚条件,是否能解释结论为什么成立。没有第三层,SLO 很容易变成告警数字;有了第三层,SLO 才会成为团队可执行的生产契约。
最后,GC SLO 还必须有例外处理和复核机制。比如大促、批量导入、索引重建、模型数据同步、灾备演练这类窗口,可能暂时允许更高内存或更长尾延迟,但例外必须提前声明、限定时间、绑定负责人,并在结束后复核是否留下新的容量基线。没有例外机制,团队会在关键业务窗口临时绕过规则;没有复核机制,临时例外会慢慢变成永久默认。成熟的 GC SLO 不是僵硬阈值,而是带证据、带边界、带复盘的运行时治理协议。
把 GC SLO 真正落到企业流程里,还需要明确责任分层。应用团队负责解释对象生命周期、缓存策略、批量大小和请求数据形状;平台团队负责说明 JDK 版本、collector 默认策略、容器 memory limit、CPU request/limit、诊断开关和镜像基线;SRE 负责把业务延迟、GC log、JFR、容器事件、节点压力和发布事件对齐到同一个时间窗口。只有这三类责任能在事故前被写入变更模板,在事故中被快速调用,在事故后被复盘验证,GC SLO 才不会停留在“监控面板上有几个阈值”的层面。一个可执行的 GC SLO 应该能回答:谁有权触发 collector 变更,谁确认业务风险是否下降,谁判断新基线是否可以长期保留,谁负责把一次故障沉淀成下一次容量评审或代码评审的检查项。缺少这层治理,GC 调优很容易变成某个专家的一次临场操作;具备这层治理,GC 才能成为组织可以复制的生产能力。
GC SLO 还应该规定复核触发条件,而不是只在事故后被动更新。JDK 大版本升级、collector 切换、容器规格变化、连接池或缓存策略调整、引入大对象 SDK、租户体量明显变化、压测模型重做、节点硬件代际变化,都应该触发一次轻量复核。复核不一定意味着重新调参,但必须确认原来的假设仍然成立:对象生命周期是否变化,RSS 预算是否仍然安全,JFR 与 GC log 是否仍然可用,灰度指标是否能覆盖新的风险面。这样做的意义,是防止一份曾经正确的 GC 策略在环境变化后悄悄失效。
10. 结论:GC 的价值不在“调到最优”,而在让风险可观测、可解释、可回滚
对架构师而言,GC 这件事最值得保留下来的,不是某一次漂亮的调优案例,而是一套能长期传递的判断方法。今天你也许在 G1 与 ZGC 之间做选择,明天也许在 generational 模式、容器预算、对象布局或 native memory 治理之间做选择,但真正不会过时的是同一条判断链:先定义目标,再读症状,再拉证据,再做假设,再小步试验,再灰度验证,再记录为什么成立以及为什么失败。只要这个链路稳定存在,collector 和 JDK 继续演进也不会让团队失去方向。
这也是为什么 GC 不应该被写成“性能技巧集合”。技巧会过时,判断方法更耐久。很多团队真正缺少的从来不是更多 JVM 参数,而是把 collector、对象生命周期、容器预算、JFR、回滚与事故复盘串起来的长期工程视角。一旦这个视角建立起来,GC 就不再是一块只有少数 JVM 专家能碰的黑盒,而会变成整个团队都能参与治理的运行时能力。
Java GC 的真正价值,并不是把每个服务都调到一个抽象意义上的“最优状态”,而是让内存管理风险被持续观察、被正确解释、被小步修改、被安全回滚。只要团队还在用“看起来像 GC”“网上说 ZGC 更好”“堆不够就再加一点”“pause 变短就算成功”这类语言讨论问题,就说明 GC 仍停留在经验主义阶段。
更成熟的做法,是把 GC 放回它应有的位置:它是应用对象生命周期、服务 SLO、容器预算、CPU 配额、collector 行为和组织可操作性共同组成的一份生产契约。判断这份契约是否健康,不靠口号,只靠证据。Collector 选择不靠潮流,只靠目标和工作负载。参数不靠复制,只靠假设与验证。变更不靠运气,只靠灰度和回滚。
如果架构师能把这条路径建立起来,那么 GC 就不再是“Java 性能问题里最神秘的一块”,而会变成一个能被团队系统处理的工程领域。真正值得追求的,不是某次 benchmark 上更漂亮的 pause 数字,而是整个系统在面对流量、版本、容器和业务变化时,依然保持可观测、可解释、可控制。
如果一定要用一句话收束全文,那么最值得记住的不是“哪种 collector 最好”,而是“任何 collector 都只是系统契约的一部分”。你可以用更先进的 collector 去缩短 pause,也可以用更合适的对象设计去降低分配压力,可以用更好的容器预算避免 OOMKill,也可以用更完整的证据链减少误判。真正的成熟不是把某一个点做到极致,而是在这些环节之间建立稳定的协调。只有这样,GC 才不会在组织里永远以“玄学”身份存在。
对团队建设而言,本文的最终目的也不是让每个工程师都变成 JVM 内核专家,而是让所有相关角色共享同一套判断语言。应用开发知道什么样的代码与对象设计最容易放大 GC 问题,平台团队知道不同 collector 和内存账本对容器治理意味着什么,SRE 知道值班时该如何用统一窗口收集证据,技术负责人知道 collector 变更为什么必须挂接灰度与回滚。这套共享语言一旦建立,GC 问题的处理质量会比单纯背更多 collector 知识上升得更快。
从更长的时间看,GC 治理最终会沉淀成组织的几类资产:统一的术语、统一的 runbook、统一的证据模板、统一的 collector 评审表、统一的容器预算方法,以及若干经过复盘验证的典型事故样例。真正让团队变强的,往往不是某位 JVM 专家一次临场救火,而是这些资产是否被建立起来、被维护、被新成员继承。只要这些资产持续存在,collector 和 JDK 再怎么演进,团队也能在新问题上快速建立新的正确判断。
也正因如此,GC 最终应被纳入平台工程与架构治理的长期议程,而不是仅在事故发生时才被想起。只要一个组织仍把 GC 看成“少数专家负责的底层细节”,它就很难在新 JDK、容器化、AI SDK、大模型编排、数据量增长和多租户复杂度提升时保持稳定。相反,一旦 GC 被纳入长期治理框架,它就会和可观测性、容量规划、运行时升级、对象设计和平台模板一起构成现代 Java 体系的底座能力。那时 collector 不再只是“JVM 内部选项”,而是业务可靠性交付的一部分。
参考资料
- OpenJDK JEP 307: Parallel Full GC for G1.
- OpenJDK JEP 377: ZGC: A Scalable Low-Latency Garbage Collector.
- OpenJDK JEP 439: Generational ZGC.
- OpenJDK JEP 474: ZGC: Generational Mode by Default.
- OpenJDK JEP 490: ZGC: Remove the Non-Generational Mode.
- OpenJDK Shenandoah Project 页面与对应 JEP/发行说明。
- Oracle / OpenJDK HotSpot GC Tuning Guide 与 JDK release notes。
- Java Flight Recorder 官方文档与 HotSpot 诊断工具文档。
Series context
你正在阅读:Java 核心技术深度解析
当前为第 2 / 8 篇。阅读进度只写入此浏览器的 localStorage,用于回到系列页时定位继续阅读入口。
Series Path
当前系列章节
点击章节会在此浏览器记录本地阅读进度;刷新后可继续阅读。
- Java 内存模型深度解析:从 happens-before 到安全发布 理解 JMM、volatile、final 字段、安全发布、乐观锁、锁语义和现代 ConcurrentHashMap 的工程边界。
- 现代 Java 垃圾回收:生产判断、证据采集与调优路径 以生产症状、GC logs、JFR、容器内存和回滚策略为主线,建立 G1、ZGC、Shenandoah、Parallel、Serial 的证据化选型与调优方法。
- 虚拟线程在生产系统中的并发治理 从吞吐、阻塞、资源池、下游保护、pinning、结构化并发、可观测性与迁移边界理解 Loom 的生产治理方法。
- Valhalla 与 Panama:Java 未来内存与外部接口模型 区分已交付的 FFM API、仍在演进的 Valhalla 值类型与泛型专门化,并从对象布局、内存局部性、native interop、安全边界和迁移治理视角建立生产判断。
- Java 云原生生产运行指南:镜像、容器、Kubernetes、Native Image 与交付治理 从 JVM 容器资源、镜像策略、Kubernetes 运行边界、Native Image、Serverless、供应链安全到故障诊断,建立 Java 云原生生产判断路径。
- Spring AI 与 LangChain4j:企业级 AI 应用边界 区分 Spring AI 官方 API、LangChain4j 抽象、示例封装和企业级 AI 运行治理。
- JIT 与 AOT:从症状、诊断到优化决策 面向 HotSpot、Graal、Native Image 与 PGO 的性能诊断和决策路径。
- Java 技术生态展望:JDK 25 LTS、JDK 26 GA 与 JDK 27 EA 以企业架构视角判断 Java 未来十年的版本策略、路线图状态、生态边界、云原生、AI 与性能演进。
Reading path
继续沿这条专题路径阅读
按推荐顺序继续阅读 Java 相关内容,而不是只看同专题的随机文章。
Next step
继续深入这个专题
如果这篇内容对你有帮助,下一步可以回到专题页继续系统阅读,或者订阅后续更新。
正在加载评论...
评论与讨论
使用 GitHub 账号登录参与讨论,评论将同步至 GitHub Discussions